java容器的整理(version0.1)
这方面的内容是根据thinking in java这本书为基本参考资料的,首先看一下java中的Container的简化图:
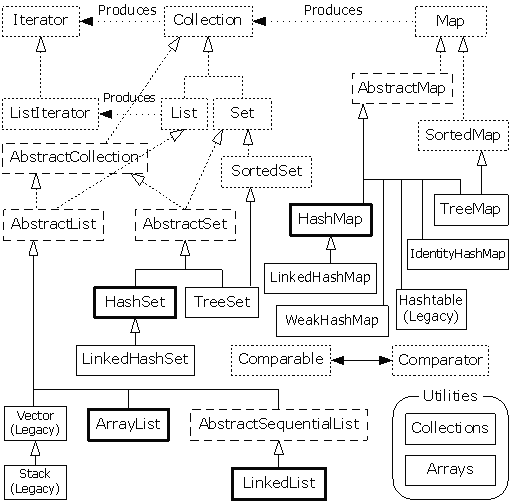
可能有人会做thinking in java(4th)的练习,那么参考答案在这里:http://greggordon.org/java/tij4/solutions.htm 感谢这位大哥的无私贡献……
1、Comparable与Comparator的区别:
public interface Comparable<T>此接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的 compareTo 方法被称为它的自然比较方法。实现此接口的对象列表(和数组)可以通过 Collections.sort(和Arrays.sort)进行自动排序。实现此接口的对象可以用作有序映射中的键或有序集合中的元素,无需指定比较 器。
public interface Comparator<T>强行对某个对象 collection 进行整体排序 的比较函数。可以将 Comparator 传递给
sort 方法(如 Collections.sort 或 Arrays.sort),从而允许在排序顺序上实现精确控制。还可以使用 Comparator 来控
制某些数据结构(如有序set-TreeSet或有序映射)的顺序,或者为那些没有自然顺序的对象 collection 提供排序。
使用Comparable有其局限性,对于一个给定的类,只能实现这个接口一次。如果在一个集合中需要按照编号对部件进行排序,在另一个集合中需要对此种部件按照另一种属性(比如按照描述信息)排序,而这个类的创建者并没有实现Comparable接口,那么在这种情况下,可以通过将Comparator对象传递给TreeSet构造器来告诉树集使用不同的比较方法。
SortedSet<Item> sortByDescription = new TreeSet<Item>(new
Comparator<Item>()
{
public int compare(Item a, Item b){
String descA = a.getDescription();
String descB = b.getDescription();
return descA.compareTo(descB);
}});
参考:http://zhanghu198901.iteye.com/blog/1575164 (看评论思考)
API: http://docs.oracle.com/javase/6/docs/api/java/lang/Comparable.html
http://docs.oracle.com/javase/6/docs/api/java/util/Comparator.html
2、Set和存储顺序
| Set (interface) |
Each element that you add to the Set must be unique; otherwise, the Set doesn’t add the duplicate element. Elements added to a Set must at least define equals( ) to establish object uniqueness. Set has exactly the same interface as Collection. The Set interface does not guarantee that it will maintain its elements in any particular order. |
| HashSet* |
For Sets where fast lookup time is important. Elements must also define hashCode( ). |
| TreeSet |
An ordered Set backed by a tree. This way, you can extract an ordered sequence from a Set. Elements must also implement the Comparable interface. |
| LinkedHashSet |
Has the lookup speed of a HashSet, but internally maintains the order in which you add the elements (the insertion order) using a linked list. Thus, when you iterate through the Set, the results appear in insertion order. Elements must also define hashCode( ). |
| Set (interface) | 存入Set的每个元素都必须是唯一的,因为Set的不保存重复元素。加入Set的元素必须定义equals()方法一确保对象的唯一性。Set与Collection有完全一样的接口。Set接口不保证维护元素的次序。 |
| HashSet* | 为快速查找而设计的Set。存入的元素必须实现hashcode()方法,至多包含一个null元素。 |
| TreeSet | 保持次序的Set,底层为树结构。使用它可以从Set中提取有序的序列,元素必须实现Comparable接口,它是SortedSet的唯一实现。 |
| LinkedHashSet | 具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。当遍历Set时,结果会按照插入的顺序的显示,元素也必须定义hashcode()方法。
|
散列表(hash table):可以快速的查找对象,在java中散列表用链表数组实现。每个列表被称为桶(bucket),要想查找表中对象的位置,就要先计算它的散列码,然后与桶的总数取余,所得到的结果就是保存这个元素的索引。,如某个对象的散列码为76268,并且有128个桶,对象应该保存在地108号桶中。有时候会遇到桶被占满的情况,这也是不可避免的,这种现象被称为散列冲突(hash collision)。散列表可以实现几个重要的数据结构,其中最简单的就是set类型(HashSet)。
3、Queue
队列(Queue)是一个典型的先进先出的容器。即从容器的一端放入事物,从另一端取出,并且事物放入容器的的顺序与取出的顺序一致。队列常被当做一种可靠的将对象从程序的某个区域传输到另一个区域的途径。队列在并发编程中特别重要,因为他们可以安全的将对象从一个任务传输给另一个任务。
| 抛出异常 | 返回特殊值 | |
| 插入 | add(e) |
offer(e) |
| 移除 | remove() |
poll() |
| 检查 | element() |
peek() |
插入操作的后一种形式(返回特殊值)是用于专门为有容量限制的 Queue 实现设计的;在大多数实现中,插入操作不会失败。具体内容可以查看Queue的API: http://docs.oracle.com/javase/6/docs/api/java/util/Queue.html
LinkedList提供了方法以支持队列的行为,并且实现了Queue接口,因此LinkedList可以作为Queue的一种实现。你可以将LinkedList向上转型为Queue以使用。
LinkedList本身还具有实现栈的所有功能方法,因此可以将LinkedList作为栈使用(“栈”通产是指后进先出的容器,你可以类比的事物是装有弹簧的储存器中的自助餐托盘,最后装入的肯定是最先拿出来使用的 )。
4、理解Map
| HashMap* | Map基于散列表的实现(它取代了Hashtable)。插入和查询“键值对”的开销是固定的。可以通过构造器设置容量和负载因子,以调整容器的性能。如果要用自己的类作为HashMap的键,那么要同时覆盖equals()方法和hashcode()方法。 |
| LinkedHashMap | 类似于HashMap,但是迭代遍历它时,取得”键值对“的顺序是它的插入顺序,或者是最近最少使用(LRU-Least-recently-used)的次序。比HashMap慢一点,但是迭代遍历时反而更快,因为它使用链表维护内部次序。 |
| TreeMap | 基于红黑树的实现,查看”键“或者”键值对“时,他们会被排序(次序由Comparable或者Comparator决定)。TreeMap的特点在于,所得到的结果是经过排序的。 |
对Map中使用键的要求与对Set中使用键的要求一致。任何键都必须有一个equals()方法;如果键被用于散列Map,那么它需要恰当的hashcode()方法;如果键被用于TreeMap,那么它必须实现Comparable。再次强调,默认的Object.equals()只是比较对象的地址,如果要使用自己的类作为HashMap的键没那么必须同时重载hashcode()和equals()。
使用散列的目的在于:想使用一个对象来查找另一个对象。
(未完待续)