抓取流程-fetcher
这个过程很简单,就是开启了一个maprunnable来实现自定义的输出(没有使用通常的mapper).red也是使用默认的.
过程是:
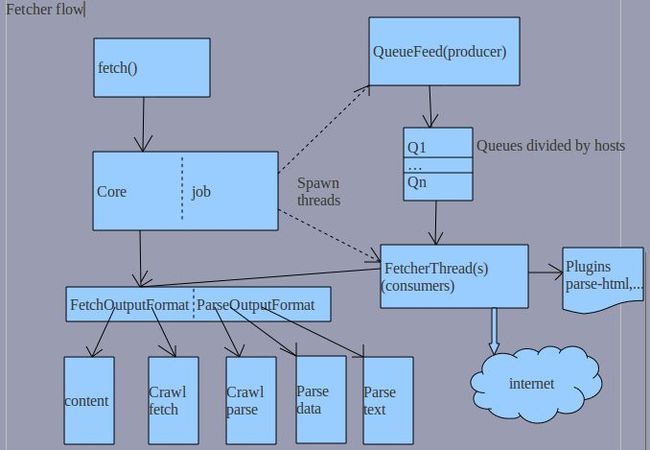
一。Fetch初始化
由于它实现了MapRunnable,那么它其实是一个mapper的启动器,包括将多个输入Key-value pairs处理,然后输出的过程完全由其中的run()实现了,所以发现job中并没有定义mapper;而reduce也是使用了默认的。
输入
segment:由上一过程generator的输出生成,形如segments/201106xxxxxx的格式;
threads:将由多少个fetcher threads来运行这批fetchlist。
InputFormat(sequence file):由于使用了自定义的input format,而其中的getSplits()正是按照fileStatus来对应生成的,所以有多少个file就有多少个splits,这意味着在generate时的rednum就是现在的mapnum了。
input path:segname/crawl_generate
output path:segname
output format:FetchOutputFormat,<text,NutchWritable>,有三种:
<url,crawldatum> --》crawl_fetch
<url,content> --> content
<url,parse> --> crawl_parse,parse_data,parse_text
其中nutchwritable是对其中的value的包装.除了了crawl_parse是sequence file,其它四个都是 map file
处理-MapRunnable
在抓取过程当前处理的urls是固定的,大小以threads * 50=total size来计算。数据结构是:
若干个queues,数量由当前的fetchlsit中的hosts决定;即queue与host是1:1
每个queue中items数量是不固定的,当然会受到total szie的结束。同时作者使用了巧妙的方法来记录当前正在fetching的urls set,当这个set中大于1时表明此host正由多个threads来处理其中的urls,所以用到了maxThreads来断言:
如果>maxThreads时返回 null,表明已经达到并行fetch的上限,让调用者等待。
fetch过程
1.以不固定的顺序从所有queues中(由FetcherQueues管理),返回其中的item元素来fetch;
2.分析此url所在的robts.txt。为了提供灵活的timeover控制及其它request headers,直接使用了socket处理。
3.处理限制性问题,如要不受限或时间间隔在此delay之外则继续;
4.开始真正的fetch。当然用到了parse plugins。由于没有使用mapper(注意不是Maptask)所以需要自己处理输出相关結果。 当有新urls添加到queue中?由updatedb 中可以看出,是不会添加进去fetch的,只会添加crawl_parse中等待下一回的fetch.
(由output()中也可以看出,当使用parsing参数并当status == STATUS_FETCH_SUCCESS时进行了一个parseutil.parse()操作,得到了个页面中的所有outlinks等数据,最后在ParseOutptuFormat#write中进行了一个iterator输出所有outlinks到crawl_parse中。)
5.对queue中的urls进行2,3,4步骤的循环处理。
---各文件内容---
content:
http://www.163.com/ Version: -1
url: http://www.163.com/
base: http://www.163.com/
contentType: text/html
metadata: X-Via=1.1 stcz187:8102 (Cdn Cache Server V2.0), 1.1 dg112:8080 (Cdn Cache Server V2.0) Vary=Accept Date=Sat, 09 Jul 2011 07:14:02 GMT Expires=Sat, 09 Jul 2011 07:15:22 GMT nutch.crawl.score=1.0 Content-Encoding=gzip _fst_=33 nutch.segment.name=20110706142546 Connection=close Content-Type=text/html; charset=GBK Server=nginx Cache-Control=max-age=80
Content:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
.
.
.
<dt class="txt_black"><cite class="txt_blue txt_12"><a href="http://blog.csdn.net/cheny_com
" onclick='LogClickCount(this,79);' target="_blank">cheny_com</a></cite><a href="http://blog.csdn.net/cheny_com/article/details/6587277" target="_blank" title="敏捷开发“松结对编程”实践之三:共同估算篇" onclick='LogClickCount(this,79);'>敏捷开发“松结对编程”实践之三:共同估算篇</a></dt>
<dt class="txt_black"><cite class="txt_blue txt_12"><a href="
http://blog.csdn.net/turingbooks
" onclick='LogClickCount(this,79);' t
从上可以看出,content是存放了所有fetch的html raw contents。
crawl_fetch:
http://www.163.com/ Version: 7
Status: 33 (fetch_success)
Fetch time: Sat Jul 09 15:14:02 CST 2011
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata: _ngt_: 1309933252318_pst_: success(1), lastModified=0
http://www.csdn.net/ Version: 7
Status: 33 (fetch_success)
Fetch time: Sat Jul 09 15:14:02 CST 2011
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata: _ngt_: 1309933252318_pst_: success(1), lastModified=0
通过下面的crawl_geneate的比较可以看出,这个阶段的結果是对原generate的修改,包括fetch time,status,metadata etc.
crawl_parse :(note this is a seqnence file but map files in other files)
http://www.163.com/ Version: 7
Status: 65 (signature)
Fetch time: Sat Jul 09 15:14:08 CST 2011
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 0 seconds (0 days)
Score: 1.0
Signature: 989844cdb45e225db2b2731315cb5342
Metadata:
http://img3.cache.netease.com/cnews/js/ntes_jslib_1.x.js Version: 7
Status: 67 (linked)
Fetch time: Sat Jul 09 15:14:08 CST 2011
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 0.01
Signature: null
Metadata:
.
.
.
http://g.csdn.net/5187332 Version: 7
Status: 67 (linked)
Fetch time: Sat Jul 09 15:14:08 CST 2011
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 0.01
Signature: null
Metadata:
http://g.csdn.net/5189759 Version: 7
Status: 67 (linked)
Fetch time: Sat Jul 09 15:14:08 CST 2011
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 0.01
Signature: null
Metadata:
这里其实就是包括seed urls在内的所有parse的urls状态 信息
parse_data:
http://www.163.com/ Version: 5
Status: success(1,0)
Title: 网易
Outlinks: 100
outlink: toUrl: http://img3.cache.netease.com/cnews/js/ntes_jslib_1.x.js anchor:
outlink: toUrl: http://reg.vip.126.com/enterMail.m anchor: 进入我的邮箱
。。。
Content Metadata: X-Via=1.1 stcz187:8102 (Cdn Cache Server V2.0), 1.1 dg112:8080 (Cdn Cache Server V2.0) Expires=Sat, 09 Jul 2011 07:15:22 GMT _fst_=33 nutch.segment.name=20110706142546 Connection=close Server=nginx _ftk_=1310195642769 Cache-Control=max-age=80 nutch.content.digest=989844cdb45e225db2b2731315cb5342 Date=Sat, 09 Jul 2011 07:14:02 GMT Vary=Accept Content-Encoding=gzip nutch.crawl.score=1.0 Content-Type=text/html; charset=GBK
Parse Metadata: CharEncodingForConversion=gb18030 OriginalCharEncoding=gb18030
.
.
.
http://www.csdn.net/ Version: 5
Status: success(1,0)
Title: CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台
Outlinks: 100
outlink: toUrl: http://www.csdn.net/1341df/csdn_ggmm.js anchor:
outlink: toUrl: http://counter.csdn.net/a/js/AreaCounter.js anchor:
。。。
Content Metadata: ETag=W/"e7bf7935f53dcc1:1111" Content-Length=126983 X-UA-Compatible=IE=EmulateIE7 Last-Modified=Sat, 09 Jul 2011 05:01:06 GMT _fst_=33 nutch.segment.name=20110706142546 Connection=close X-Powered-By=ASP.NET Server=nginx/0.7.68 Cache-Control=max-age=1800 _ftk_=1310195642771 nutch.content.digest=892e028e36c036049789babb3db5806b Date=Sat, 09 Jul 2011 07:14:02 GMT Vary=Accept-Encoding nutch.crawl.score=1.0 Content-Location=http://www.csdn.net/index.htm Content-Type=text/html; charset=utf-8 Accept-Ranges=bytes
Parse Metadata: CharEncodingForConversion=utf-8 OriginalCharEncoding=utf-8
这里就是各个seed urls中取出的所有出站urls,在搜索时的anchor项就是由这里提供的。
parse_text:
http://www.163.com/ 网易 帐号 密码 选择去向 网易通行证 163邮箱 126邮箱 VIP126邮箱 Yeah邮箱 188财富邮 vip邮箱 网易博客 网易相册 同城约会 网易论坛 网易微博 登录微博 注册免费邮箱 欢迎你, pInfo 进入通行证 进入我的邮箱 进入我的邮箱 进入我的邮箱 进入我的邮箱 进入我的邮箱 进入我的邮箱 进入我的博客 进入我的相册 进入。。。
http://www.csdn.net/ CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台 CSDN.NET - 中国领先的IT技术社区,为IT专业技术人员提供最全面的信息传播和服务平台 您还未登录! | 登录 | 注册 | 帮助 首页 资讯 论坛 博客 下载 搜索 空间 网摘 程序员 会议 CTO 俱乐部 项目交易 TUP 培训充电 学生大本营 移。。。
这里的内容是从整个page中所有tags解析的contents
----之前generator阶段的結果,
crawl_generate:
http://www.163.com/ Version: 7
Status: 1 (db_unfetched)
Fetch time: Mon Jul 04 14:57:19 CST 2011
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata: _ngt_: 1309933252318
http://www.csdn.net/ Version: 7
Status: 1 (db_unfetched)
Fetch time: Mon Jul 04 14:57:19 CST 2011
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata: _ngt_: 1309933252318
anyway ,这些数据都可以从code中了解,但显示出来是为了方便日后 的查找而已;
另外可以根据输出格式的来想像相关的数据亦可。