what is
every db holds its storage level,either memory or fs.this is similar to,hbase,it has HFile as underlying data structure which will be stored in fs or dfs.
exquisite data structure also must be matched appropriate algoriths.of course ,different requirements will lead to heavily varied db design styles.
like some other index tools,HFile is a indexed storage structure mainly for fast access.the idea of HFle is from TFile ,sure,the former has a bit differences improved, and its internal structures will like below figures:

*note:this file format(not Data block) is for HFile v1,the part File Info is placed after Meta Index for v2.
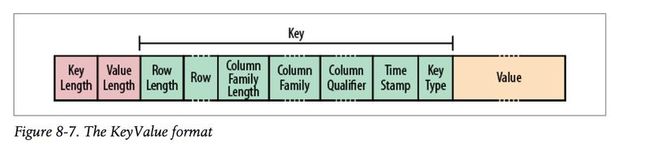
whye
as described above,hbase uses special file instead of existances in hadoop (eg. SequenceFile) is to speedup the readings by rowkeys,as you can see some index blocks in previous figures:
a.construct a reversed index query,speed up for reading(mainly)
b.supplys a hadoop-independent style to read/write file format without considering dfs's compability
| file | structure | compression | embed in |
| SequenceFile | 3 file types: 1)uncompressed 2)record-comprssed(only values be compressed) 3)block-compressed(both keys and vlaues are compressed,similar to HFile v2) |
yes | hadoop |
| HFile v1 | similar to v2,but some block indexes are different wth that. | yes | hbase |
| HFile v2 | 1)indexed reversed style 2)most data(except trailer) in file are compressed if configure compressor |
yes | hbase new file format for (94+) |
how to
there is a process model in the flush:
1.iterate all keyvaues in snapshot to write to memory buffer 2.generate a new data block if over a 'block-size' which in set when creating table 3.repeat 1 & 2 until no more data from snapshot 4.flush to memory compressed stream 5.flush to stream to outputStream (hfile stream) and clear the tmp buffer to avoid huage memory usage 6.similar to data block flush,flush meta block,data index,meta index,file-info and last trailer
why places extra parts of index and trailer to the last of a hfile?
i think some points are abvious:
a. as the index or trailer have some stats about the block and index,flushing memory buffer to hfile per 'block'(part of hfile) will min the memory overhead by region.
b. this can avoid going far away from the top of hfile offset to locate a special data block offset
others
using the or.apache.hadoop.hbase.io.hfile.HFile tool ,u wil look at the the details of it like below:
hbase hfile -f path-to-file
for a compressed file occupied size '18644309' will results like this:
Stats: Key length: count: 496573 min: 48 max: 53 mean: 49.44025551127427 Val length: count: 496573 min: 1 max: 915 mean: 34.053575204451306 Row size (bytes): count: 28930 min: 814 max: 3190 mean: 1570.45855513308 Row size (columns): count: 28930 min: 12 max: 21 mean: 17.16463878326996 Key of biggest row: 94678d0589778ade561378ac26dfd791Key length count--number of keys(composite keys,ie. rowkey+fml+col+ts+type)