OSCache框架源码解析
OSCache是一个受到争议的开源缓存框架,OpenSymphony网站已经关闭(OpenSymphony可是诞生过Quartz、WebWork、SiteMesh和OGNL等数个非常有名的框架的)了,它也已经不维护了。在JavaEE的缓存框架领域,似乎已经是EhCache等其它支持分布式的缓存框架的天下了,OSCache垂垂老矣?但是OSCache的源代码依然值得一读,一度作为最常用的缓存框架,代码量却不大,绝大部分类一天的时间就可以详详细细地阅读完。
统观OSCache的代码,我最关注其中的base、algorithm、events、persistence、clustersupport、web、filter和tag几个子包,接下会对这几个主要模块作介绍。
核心类和核心概念
cache factory:AbstractCacheAdministrator,生产Cache,同时管理用户配置的config,配置监听器列表和Cache的绑定。子类GeneralCacheAdministrator是通用实现,子类ServletCacheAdministrator关联了一个ServletContext,以实现在Web容器中的存储和传值(对于session的scope,持久化时,存放路径上会建立一个sessionID的dir,以避免存放冲突)。
cache proxy:Cache,是OSCache缓存管理的核心,也是cache map的存放场所。子类ServletCache引入了一个scope的概念,用以管理不同的可见性缓存,存在application级别、session级别;
cache map:AbstractConcurrentReadCache,缓存存储map。下面有基于它的子类,分别实现了LRU算法、FIFO算法和无限制缓存策略;
cache entry:缓存条目,map中存储的每一项。其内部包含了缓存条目的创建、修改时间,存储的key、value等重要属性,此外,还有一个Set group,标识每个entry从属于哪些组。
它们之间的关系如下:
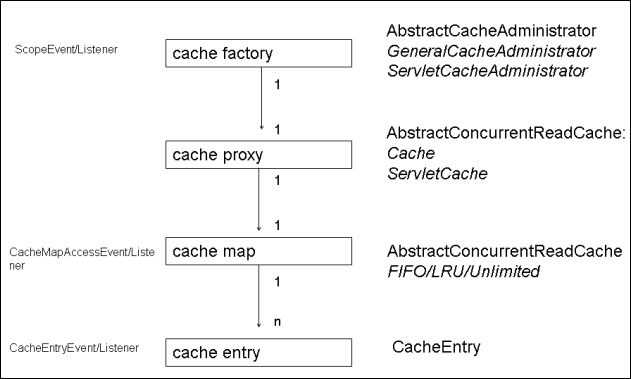
值得说明的是,这张图虽然简单,却很有借鉴意义,再复杂的缓存框架,它往往都逃脱不出这样的最基本的设计。
调用示例代码如下:
ServletCacheAdministrator admin = ServletCacheAdministrator.getInstance(config.getServletContext()); Cache cache = admin.getCache(httpRequest, cacheScope); cache.flushGroup(group);
EntryRefreshPolicy是entry的过期刷新策略接口,OSCache允许自行定义缓存项的过期策略:
cache.putInCache(key, content, policy);
cache map对cache entry的管理
EntryUpdateState是cache entry当前所处状态的表示,OSCache尽量避免了使用synchronize,引入了许多状态参量。状态变迁图示如下:

对于缓存超期的判定,官方推荐有两种方案,一种是“with fail over”的:
String myKey = "myKey";
String myValue;
int myRefreshPeriod = 1000;
try {
// Get from the cache
myValue = (String) admin.getFromCache(myKey, myRefreshPeriod);
} catch (NeedsRefreshException nre) {
try {
// Get the value (probably by calling an EJB)
myValue = "This is the content retrieved.";
// Store in the cache
admin.putInCache(myKey, myValue);
} catch (Exception ex) {
// We have the current content if we want fail-over.
myValue = (String) nre.getCacheContent();
// It is essential that cancelUpdate is called if the
// cached content is not rebuilt
admin.cancelUpdate(myKey);
}
}
还有一种是“without fail over”的:
String myKey = "myKey";
String myValue;
int myRefreshPeriod = 1000;
try {
// Get from the cache
myValue = (String) admin.getFromCache(myKey, myRefreshPeriod);
} catch (NeedsRefreshException nre) {
try {
// Get the value (probably by calling an EJB)
myValue = "This is the content retrieved.";
// Store in the cache
admin.putInCache(myKey, myValue);
updated = true;
} finally {
if (!updated) {
// It is essential that cancelUpdate is called if the
// cached content could not be rebuilt
admin.cancelUpdate(myKey);
}
}
}
这里出现了臭名昭著的NeedsRefreshException,它在缓存条目过期或者不存在的时候都会抛出。当这个异常出现,相应的cache map的key会被锁住,并且要访问它的所有其他线程都被block住了,所以,这个时候一定要调用putInCache或者cancelUpdate,千万不能遗漏,否则就是一个死锁。
为什么要这样实现?
首先,我们需要好好分析分析OSCache的核心,Cache类。Cache类的属性中,这个属性和这个问题最相关:
private Map updateStates = new HashMap();
其中,updateStates这个map,它的key是正在工作的缓存条目的key,value是EntryUpdateState,它是用来协调并发访问同一个缓存条目之用的。
当一条缓存条目正在被更新,那么有两种策略,根据配置项cache.blocking的配置,要么等待更新完成(阻塞策略),要么返回已经过时的缓存内容(非阻塞策略),选用哪种策略。
为了避免数据争用,cache map里面的值在某线程操作的过程中不能消失,因此updateStates实际的作用是显式引用计数(每一个updateState里面都有一个计数器),在所有线程都完成存取和更新以后,cache map的这条entry才能被清除掉。
再补充一个前提知识,缓存访问状态最终有三种:
- HIT——表示命中;
- MISS——表示未命中;
- STALE_HIT——表示命中了一个失效的缓存(就是getFromCache整个过程初期还有效,等到getFromCache逻辑执行完已经过期了)。
来看看getFromCache的逻辑:
(注意下面的updateStates,类型是Map<EntryUpdateState>;updateState是其中的一条状态,类型是EntryUpdateState,小心混淆)
首先看看该缓存条目是否需要刷新,如果需要,锁住updateState(同时,引用计数加一);
情况1:updateState状态如果是waiting或者cancelled:
把这条updateState标识为updating;
再看cache entry里的最近更新时间,如果还是NOT_YET,说明这次缓存访问判定为MISS;否则,就是STALE_HIT 。
情况2:如果updateState状态是updating:
那么在配置为阻塞策略的情况下,或者cache entry状态为NOT_YET,都需要等待这一次updating的完成:
do {
try {
updateState.wait();
} catch (InterruptedException e) {
}
} while (updateState.isUpdating());
如果更新的线程取消了更新,那么缓存仍然是过期的,执行和前面分支相同的操作——根据cache entry的时间把这次缓存访问判定为MISS还是STALE_HIT;如果没取消更新的话,那么这时updateState的状态应该是complete。
情况3:updateState状态是complete(也可以是前面情况2结束之后状态是complete),就可以载入缓存中的数据返回了,否则就要抛出NeedsRefreshException。(引用计数减一)
相反地,putInCache的逻辑非常简单,但要注意的是,其中调用了completeUpdate(key)方法,其中会唤醒putInCache中wait的updateState:
state.notifyAll();
而在cancelUpdate(key)方法中也有同样的逻辑。
所以,putInCache之后,业务逻辑上一定要调用到putInCache或者cancelUpdate,以避免永久wait导致死锁的发生。
OSCache就是采用这样的引用计数状态量机制,解决了多线程并发访问缓存的问题,同时,没有任何语句锁住整个cache map,在高并发的情况下不会有太大的性能损失。
PS:在实际使用中,发现还是会抛出一些非预期的异常,甚至也遇到过若干造成思索的bug,有的在OSCache的JIRA上都有记载,但是未有官方的解决出现。
淘汰算法
对于cache entry淘汰算法,常见的有FIFO和LRU,FIFO比较简单,这里以LRUCache为话题说几句。
不妨先问这样一个问题:如果让你来做LRU算法(Least Recently Used最近最少使用算法),你会怎样实现?
如果是我的话,我会回答:利用JDK的LinkedHashMap预留的机制来实现。
先来看看JDK的HashMap的存储:
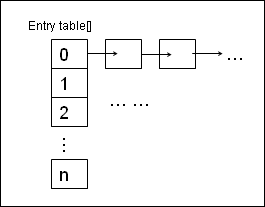
上图每一个矩形都是一个Entry,HashMap存放的时候,通过Entry[] table来管理hash之后的每一个桶的入口,在调用map的get方法的时候,先对key进行hash计算,找到桶,然后和桶内挨个entry的key进行equals操作,来寻找目标对象。
而LinkedHashMap,它的Entry继承自HashMap的Entry,比HashMap的Entry多了两个属性:before和after,这样就在HashMap的基础上,又单独维护了一个双向循环链表,同时LinkedHashMap保留了一个对这个链表head的引用。
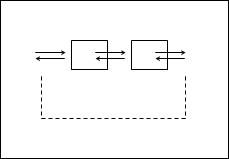
同时,LinkedHashMap引入一个accessOrder属性,用来控制access-order还是insertion-order,前者表示按照访问情况排序,后者表示按照插入情况排序。每次调用get方法时,进行一次recordAccess操作,如果是按照访问顺序排序的话,我需要在这次get访问后调整次序,即将刚访问的节点移到head节点之前(而每次要淘汰一个节点的时候,一定是淘汰header之后的那个节点)。
每次添加节点时都调用如下方法判断是否需要移除一个最近最少使用的节点:
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
而这个方法是protected方式扩展给子类实现的,我只要在我建立的子类LRUMap里面实现这个方法,判断当前cache map的size是否已经超出预设上限,超出则返回true即可。
好,我可以按照上面这个办法实现,但是这个办法的最大问题是,它不是线程安全的。
到此先打住,来看看OSCache是怎么做的:
AbstractConcurrentReadCache的实现本质上就是ConcurrentReaderHashMap。ConcurrentReaderHashMap 和 ConcurrentHashMap这两个Map(作者都是Doug Lea)实现是线程安全的,并且不需要对并发访问或更新进行同步,同时还适用于大多数需要 Map 的情况。它们还远比同步的 Map(如 Hashtable)或使用同步的包装器更具伸缩性,并且与 HashMap 相比,它们对性能的破坏很小。
AbstractConcurrentReadCache支持大多数情况下的并发读,但是不支持并发写。读策略比经典的读写策略要弱,但是总的来说在高并发下要快些。如果数据大多在被程序起始阶段创建,然后就是大量的并发读(有少量的添加和删除),这种情况下性能表现最好。因此,如果涉及到大量写的情况,不妨使用ConcurrentHashMap。
实现上,使用get(key)、contains(key)成功的获取是不加锁的,不过如果失败了(比如这个key不存在)就会调用synchronize加锁来实现了,同时,size和isEmpty方法总是synchronized的。
我对于这个类还是没有参透,不在此误人子弟了,有兴趣的同学请自行Google,如果有研究明白的请告诉我,这里给一个 ConcurrentReaderHashMap的APIdoc链接:ConcurrentReaderHashMap。
在AbstractConcurrentReadCache下有FIFOCache、LRUCache和UnlimitedCache三个子类。以LRUCache为例,它用一个LinkedHashSet,起到队列的作用,来存放所有的key,实现父类的回调方法进行这个队列的维护操作:
protected void itemRetrieved(Object key) {
// Prevent list operations during remove
while (removeInProgress) {
try {
Thread.sleep(5);
} catch (InterruptedException ie) {
}
}
// We need to synchronize here because AbstractConcurrentReadCache
// doesn't prevent multiple threads from calling this method simultaneously.
synchronized (list) {
list.remove(key);
list.add(key);
}
}
... ...
为什么LinkedHashSet会起到队列的作用?
原来,它是基于父类HashSet实现的,而调用父类构造器的时候,使用了三个参数,HashSet的构造器很有意思:
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<E,Object>(initialCapacity, loadFactor);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor);
}
可以看到,三个参数的构造器,实际实现的map是LinkedHashMap(这第三个参数dummy居然是毫无作用的),前文已经说过,它是怎样实现有序的。
在这个队列里面,每次删除都是删第一个,而每次put或者get的时候,都往把该节点挪到队尾。
事件/监听模型
CacheEvent下面有如下几个子类,其中CacheMapAccessEvent对应的listener是CacheMapAccessEventListener,ScopeEvent对应的listener是ScopeEventListener,其余的几个event对应的listener都是CacheEntryEventListener,这三种类型的实现类中都有相应的一个Statistic监听实现类,做统计用:
- CacheEntryEvent:对于cache entry发生add/remove/update/flush等操作时触发;
- CacheGroupEvent:类似,只是对象变成了cache entry group,而不是cache entry;
- CacheMapAccessEvent:访问cache map时触发;
- CachePatternEvent:当cache匹配到某种模式(使用key.indexOf(pattern)判断是否匹配)时进行flush的时候触发;
- CachewideEvent:当cache flushAll的时候触发;
- ScopeEvent:仅在ServletCache出现flush时触发。
持久化
PersistenceListener接口定义了remove、retrieve和store等用于缓存持久化的方法,抽象实现类AbstractDiskPersistenceListener下,有两个子类:DiskPersistenceListener和HashDiskPersistenceListener,后者给文件名做了md5散列,并根据散列结果,将文件分散存储到多个文件夹内,以提高文件数量太大时,文件和文件夹访问的性能(操作系统文件夹内文件数量有限制):
StringBuffer filename = new StringBuffer(hexDigest.length() + 2 * DIR_LEVELS);
for (int i=0; i < DIR_LEVELS; i++) {
filename.append(hexDigest.charAt(i)).append(File.separator);
}
filename.append(hexDigest);
不过,这样的文件名、文件夹名和文件夹划分是不具备业务语义的,不容易理解,使用时可以定义自己的持久化监听器以改善存储。
对于集群节点下持久化文件的存储,可能造成名字冲突的问题,OSCache给出的解决办法是文件名组成上增加一个serverName。
集群
LifecycleAware接口提供了Cache的初始化和终结方法接口,AbstractBroadcastingListener在缓存flush发生时通知到其他节点,通知的方式由不同的子类实现。
最常用的是JGroupBroadcastingListener,使用JGroup通信(多播消息),但是JGroup并不是一个少惹麻烦的主,曾经有同事遇到过集群Cache过多导致JGroup通信时节点累积的NAKACK数量过大的问题,消耗大量内存,请在使用前考察清楚。
web支持
先上一张典型的基于OSCache的web请求缓存方案:
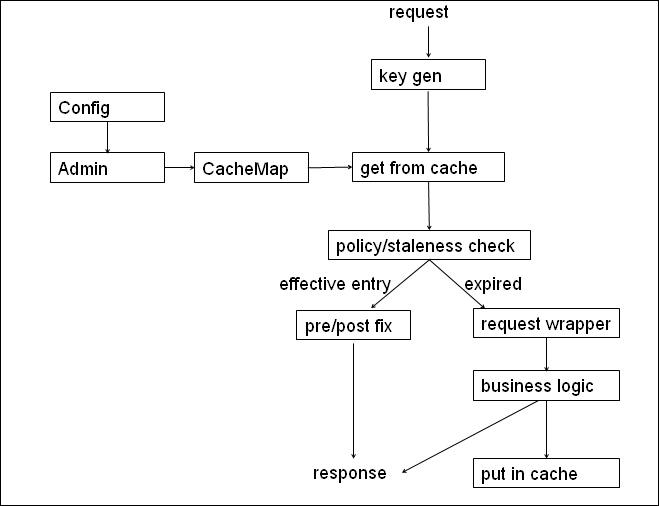
- 每次目标请求到达,生成相应的key后,调用getFromCache尝试获取缓存信息:
- 如果成功取得缓存对象,从缓存中取得content并做一定修正后输出到response;
- 如果NeedsRefreshException抛出,缓存过期,这里用一点小技巧,给response包装一层,让后面逻辑写入response时,既写入原生HttpServletResponse中,也写入拟造出来的一个fake response流中,这样原生response可以顺利返回页面,而虚拟response则存放到CacheEntry中,甚至持久化到磁盘。
这个捕获请求的介质就是CacheFilter,包装后的response就是CacheHttpServletResponseWrapper,它包含一个SplitServletOutputStream,这样在后面的逻辑中,如果要获取output stream的时候,获取到的就是它了。
这个特殊的stream在写入时,既写入原生response,也写入一个fake response流——ByteArrayOutputStream,代码如下:
public class SplitServletOutputStream extends ServletOutputStream {
OutputStream captureStream = null;
OutputStream passThroughStream = null;
public void write(int value) throws IOException {
captureStream.write(value);
passThroughStream.write(value);
}
......
}
另外,在web缓存生效,输出读取的缓存内容时,CacheFilter给response头部增加“Last-Modified”、“Expires”、“If-Modified-Since”和“Cache-Control”这些帮助浏览器实现客户端缓存的头。
tag子包提供了一组可供模板页面上使用的缓存标签集合,以实现页面不同区域不同缓存生命周期的精确控制。如:
<oscache:cache key="sth" scope="application" time="-1" groups="groupA" >
//page template code
</oscache:cache>
到此,不妨来基于OSCache做一个小小的思考,OSCache于我来说,可以说出这样一些内容:
- 可以缓存任意对象,但是缺少对存储对象类型的约束力(我见过一个缓存框架,使用JDK的范型来实现,效果很好);
- 代码虽然不复杂,但是可扩展性做得比较出色,进行业务定制也很容易;
- 丑陋的NeedsRefreshException,容易死锁,bug丛生,用源代码注释中的话来说,“代码的坏味道”(我觉得,好的设计符合两个特点:1、简单;2、美。看看Cache类里面的逻辑,逻辑比较复杂,把逻辑理一理成图,混乱,而且丑陋);
- 不支持分布式,不支持异步缓存,不提供批量缓存条目的接口,或许,功能上真的是太简单了。
PS:对于缓存有兴趣的同学,不妨关注一下JSR107,从编号上就可以看出,这个规范提得很早,但是这么重要的东西,直到现在也没有搞定(这是JDK令人费解的地方之一),看看投票的人里面,Doug Lea也在里面。或许在Java 7中能够看到它的实现(当然,现在已经可以下载得到它的代码了,代码主要是Greg Luck和Yannis Cosmadopoulos写的)。
文章系本人原创,转载请注明作者和出处