方案是我针对目前系统设计的一些改进或者说"改动"(因为实际也带来了一些不方便和约束),去掉了涉及业务的细节,仅将能复用在其他一些较普遍应用的的大体思路提取出来,这个方案不会适用全部场景,但可以作为一种思路参考。
大型系统每天需要记录海量日志,以我目前服务的系统为例,大约每天忙时峰值就会记录200-300G日志,平时50-90G不等,忙/闲比大约1/4左右,而这些日志数据有时会被要求提供异地备份容灾的能力。
这么大量的数据采用通用的实时或者准实时备份方案,其最大的问题无疑在于log的同步成本上,并且每天这么大的disk消耗也使得磁盘紧缺和IO负载成为影响系统性能的重要因素。
根据需要,日志系统需要记录所有服务器发起的RMI操作以及这些操作得到的返回输出,这些输出99%都是基于XML的字符串,记录和记录之间结构相似度非常大。
下面是两种正交的思路:
1.对单条记录进行减肥,对XML采取重编码
由于所有的大尺寸的数据都是XML文本,所以可以考虑对XML进行瘦身,方式有二:
(1)直接压缩
之前的工程师尝试过在入库前对XML进行行压缩,但整体收效不大。因为大部分记录大小集中在1-2k,由于压缩需要保存一定容量的字典数据,小记录压缩反而得不偿失,大小在3,400字节以下的记录甚至会出现压缩后比原记录更大的情况,因此需要换别的思路进行改进。
(2)重编码
这个思路是对原始XML数据进行简单的数据替换,将长字符的tag替换成短tag。
XML的格式决定了XML的tag的冗余结构,因此可以考虑将XML转化成为JSON like的格式。需要注意的是,XML和JSON是否能完整无损的转化,这个是需要考虑的问题,比如namespace,node的attribute都需要考虑。
另外一种压缩途径是将XML中的tag长字符串替换成短的id字符串,然后关联到一个id-tag对应的map结构中,其具体思路如下图所示:
可以看到,其实这个思路本质上是类似数据仓库的星型模型的思想,对XML进行了重编码,抽取出dimension的词汇表,然后用字节更少的id来代替长的tag,所得到的是一个近似XML格式的非XML字符串(替换的部分已经不一定满足XML对tag的定义限制),而这个替换后的类XML串又可以转化成为冗余更少、尺寸更小的类JSON字符串。对简化后的JSON字符串如果再采取消除格式化所用的'\n'、'\t'、' ',然后再压缩则可以榨出最后一点空间。
编码的缺点在于需要编解码,词汇表需要在C和S端都必须可见。
对比RMI、CORBA与基于XML和HTTP协议的web Service调用,很容易发现,高效的RMI、CORBA因支持二进制层面的序列化导致性能的大幅度领先,而二进制流化也同时导致服务器和客户端都必须对于二进制的对象模型定义都必须同时理解可见,这是其缺点,但也可以说是其追求速度这一优点带来的副作用,这个方案的的局限性也比较类似,有得必有失。
如果考虑不同系统的互通,则词汇表和替换规则都需要统一管理,不能各自为政。这也会导致这个方案有相当的局限性。
2.列压缩
考虑到记录和记录之间相似度非常大,所以考虑采取按照列来压缩日志数据。
老的方案采用两个表log表和log_rest表,两个表都有operation和result的字段,两个表中 operation和result两个字段都为varchar类型,当operation或result数据长度超出varchar类型限制的4000时,会将超出部分放入log_rest表。
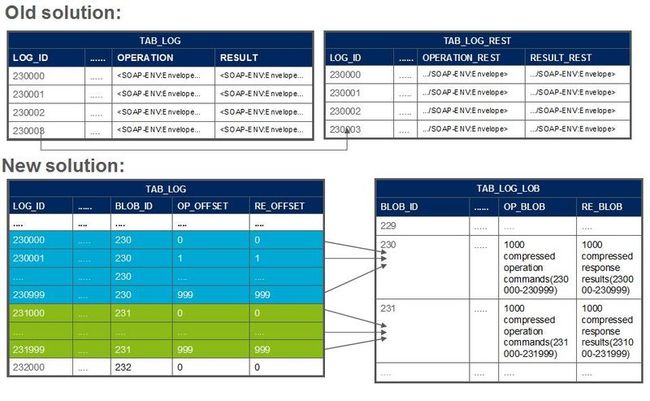
这个方案带来的副作用也是很明显的:
1.对基于SQL的ETL工具来说是个噩梦,解决方法,要么用非sql代码实现ETL,要么处理数据时转化成原始未压缩的临时表然后做ETL,做完再删除临时表。
2. 对于报表工具例如BO来说无法钻取到细节,因为这些工具还是以SQL为数据抓取手段,解决方法只能是自己做页面和数据钻取。
如果LOG功能本身就是以自实现的代码解决业务逻辑,不是完全依赖SQL,则这个方案会比较适用。
实际列压缩对于数字格式的列效果也通常很好,比如性能系统或者告警系统。
这些系统中列数据压缩比可以达到非常高,因为记录和记录之间冗余非常之大,而且这些系统往往是日产数据量极大的系统。
这些系统往往受限于磁盘消耗,只能保存1-2个月的历史数据,甚至大负载的系统只能保存10-20天的历史数据
每天的系统级备份和数据库热备以及类似dataguard这种同步备份使得磁盘消耗和IO负载都非常可观。
对于基于db实现的文件存储系统,列压缩同样可能非常有效,比如电子商务网站的图片,尤其是B2C和C2C的产品图片,相同商品的图片相似度非常高,还有不同商家同一商品的profile、名录这些数据,信息冗余程度很大。
这些数据在入库过程可以考虑通过相同的category信息,存入相同的chunk甚至数据块,这样可以最大限度将相似数据聚合在一起,使得压缩冗余数据的收益最大化。
因此如果没有特殊需求,可以通过这种列压缩极大降低db导致的系统磁盘消耗和IO负载,而带来的成本仅仅是日志处理系统的cpu消耗会提高,而这种会话无关的计算性纯cpu消耗是很容易通过简单的提供多点分布式服务扩缩来获得大量并行处理能力,做的更复杂就是提供独立的任务分发节点采用direct rooting方式进行任务分发。
简单的说,这是利用容易扩缩的cpu的并行能力来提升不易扩缩的db单点访问能力,通过同样大小的物理cache能提高几十倍的cache命中率,避免过多的随机IO寻道和磁盘IO吞吐。
对于那些基于sql的报表系统,则可以在钻取到最底层的fact表时,通过url携带下钻参数的方式定向到自实现的数据查询页面,而这个实现相对于分布式设计设计和存储消耗、调优成本来说并不大。
目前业余正在尝试使用这样的列压缩系统结合内存盘NoSQL与磁盘NoSQL组主备来管理国家级电信传输网Inventory数据,这样只需要G级的内存就能缓存千万到亿级的设备记录数提供实时Inventory 级联和拓扑分析服务,来替代网管系统传统靠数据库级的互相同步适配的方式来做集成。