讲解jdk源码中List接口之前我们先来看一个模式,迭代器设计模式。
迭代器设计模式主要是为了对容器提供统一的遍历接口,对于不同的数据结构的遍历方式由不同的iterator实现类所实现,而且也对原始数据进行了封装,不至于在用户使用时暴漏内部细节,类图如下。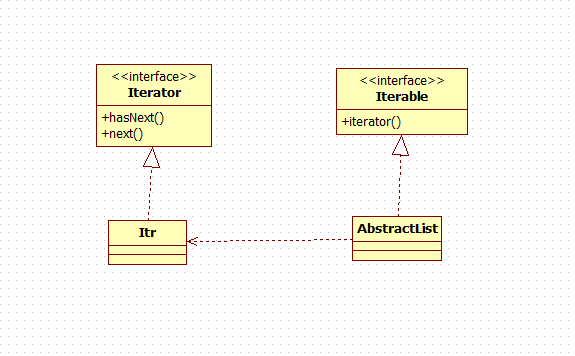
上面图中的各个类其实就是jdk中Collection容器对迭代器设计模式的一个实现,Itr是AbstractList的一个内部类,内部类的好处就是它可以直接访问AbstractList中的数据,Itr类实现了对元数据的遍历,部分代码如下。
public boolean hasNext() {
return cursor != size();
}
public E next() {
checkForComodification();
try {
E next = get(cursor);
lastRet = cursor++;
return next;
} catch (IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
java中的List接口以及实现类,类图如下: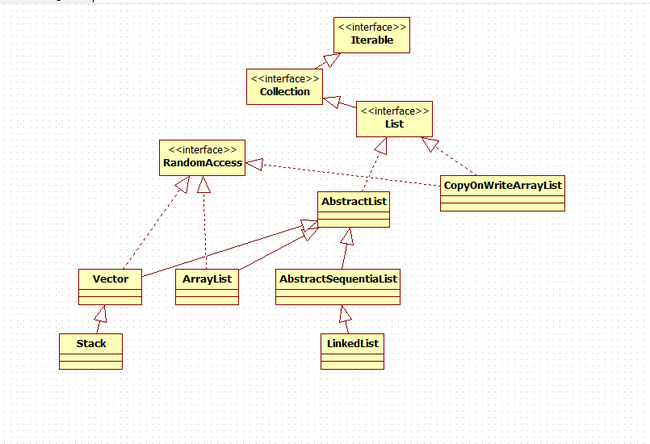
List中主要有2种数据结构的实现,一种是数组,另一种是链表。
数组的实现有ArrayList、Vector、Stack、CopyOnWriteArrayList他们都继承了AbstractList,AbstractList实现了List中的部分接口,并且实现了数组结构的遍历,也就是上边说到的迭代器设计模式中Iterator部分,Stack实现了一个LIFO,Vector实现了线程安全,CopyOnWriteArrayList则是线程安全的一个变体,读的操作没有锁性能会更好,而写的时候存在锁并且在写的时候copy元数据,在新的数据上做修改,然后在同步回元数据,从而实现了在遍历的时候可以对其进行修改而不会抛出CurrentModificationException异常。基于数组实现的容器都实现了RandomAccess接口,这是一个空接口,实现了这个接口的类代表支持随机访问,而支持随机访问的类在遍历时正如RandomAccess类中描述的那样,上面的遍历方式性能会好于下面的遍历方式如下:
* <pre>
* for (int i=0, n=list.size(); i < n; i++)
* list.get(i);
* </pre>
* runs faster than this loop:
* <pre>
* for (Iterator i=list.iterator(); i.hasNext(); )
* i.next();
* </pre>
链表的实现只有LinkedList。
这里我们主要讲解ArrayList和LinkedList,首先看ArrayList,它的类声明如下:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
他实现了RandomAccess支持随机访问,因为底层是数组嘛,知道下标访问速度是非常快的哈,并且实现了Serializable接口,代表这个类可以序列化以及反序列化,Cloneable则代表这个类可以被克隆,这个克隆啊又涉及到原型设计模式,原型涉及模式分为深克隆和浅克隆,有兴趣的朋友可以自己了解下本节不做讲解。
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer.
*/
private transient Object[] elementData;
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
ArrayList中只有这2个成员变量,elementData则是用来存放具体数据的,size则用来标记数组实际大小,但是这里elementData为什么被transient修饰呢,被transient修饰则代表在序列化时会忽略elementData,难道elementData就不序列化了吗,并不是,而是ArrayList重写了writeObject方法,因为elementData每次满的时候都会扩充,会存在NULL没有使用的元素,所以重写了writeObject方法在序列化时只写入elementData的0到size实际使用的的数据。
public boolean add(E e) {
ensureCapacity(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
add添加元素时首先调用了ensureCapacity方法,这个方法会进行判断当前数组容量是否小于size+1,如果小于则扩充,扩充是调用的system.arraycopy的native方法来将数组copy到另一个扩充之后的数组中,然后把要添加的数据存放在elementData中。其余的方法和类都比较简单类似就不在说了。
LinkedList底层使用Entry类来存放数据元素。
private static class Entry<E> {
E element;
Entry<E> next;
Entry<E> previous;
Entry(E element, Entry<E> next, Entry<E> previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
}
链表,就是手拉手,通过一个元素可以知道上一个元素和下一个元素,这个链表不了解的话可以先学习下数据结构这里就不在多说了,链表的遍历方式实现和数组是不一样的,
private class ListItr implements ListIterator<E> {
private Entry<E> lastReturned = header;
private Entry<E> next;
private int nextIndex;
private int expectedModCount = modCount;
ListItr(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
if (index < (size >> 1)) {
next = header.next;
for (nextIndex=0; nextIndex<index; nextIndex++)
next = next.next;
} else {
next = header;
for (nextIndex=size; nextIndex>index; nextIndex--)
next = next.previous;
}
}
public boolean hasNext() {
return nextIndex != size;
}
public E next() {
checkForComodification();
if (nextIndex == size)
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.element;
}
构造方法中初始化了next的值,if(int < (size >> 1))这里介绍下>>和>>>符号,>>代表向右移位,例如3>>1则代表二进制0011向右移动1位则是0001最终结果就是1,8>>>3代表8除以2的3次方最终结果则是1。
这里的if(int < (size >> 1))主要是为了判断这个元素时在前半段还是在后半段size >> 1相当于size/2,主要是为了更快的定位链表中第index元素的位置,不用从头遍历,这就是迭代器设计模式的好处,隐藏了内部实现的细节,对不同的数据结构提供了统一的迭代接口,就到这吧!