一个简单的语言的语法(三):做些小调整,并将生成目标换到CSharp2
系列链接:
一个简单的语言的语法(一):用ANTLR描述语法
一个简单的语言的语法(二):ANTLR的重写规则
一个简单的语言的语法(三):做些小调整,并将生成目标换到CSharp2
为了后面的tree grammar更简洁,本篇对 上一篇的树重写规则和一些语法细节做了些调整。并且,将生成的lexer和parser的源码目标换到了CSharp2,以便后面能使用一些.NET的库。
要使用CSharp2的目标,需要从官网下载相应的运行时库。当前的最新版是3.1.1,可以从 这里获取。CSharp/CSharp2目标的详细情况,可以查阅 官网上的文档。以 上一篇的语法为基础,要换到CSharp2目标只要把几个嵌入动作里的System.out.println换成Console.WriteLine,把toStringTree换成ToStringTree,把clear换成Clear就可以了。编译的时候至少需要引用Antlr3.Runtime.dll。
那么除去更换生成目标带来的影响,这次做了些怎样的修改呢?
首先,语法做了些细微的调整。例如说,program规则从原本允许没有语句到现在要求至少有一条语句;blockStatement为空block写了条专门的分支;expressionStatement也添加了一个EXPR_STMT的虚构token为根节点,等等。
变化最大的还是variableDeclaration及相关规则。上一篇里这条规则的重写规则并不区分有初始化与无初始化、简单类型与数组类型的区别;本篇里则将这两个区别都明确的写在了重写规则里,以不同的虚构token来作为生成的树的根节点。这样,到写后面的tree grammar的时候,需要的lookahead数就可以减少。
ANTLR所生成的AST,以深度优先的方式遍历,可以看做一个一维的流:每一层父子关系都可以表示为:
root -> "down" -> element1 -> element2 -> ... -> elementN -> "up" -> ...
其中"down"和"up"是ANTLR插入的虚构token,用于指定树的层次。
这样,后面使用tree grammar来遍历AST时,实际上遍历的就是这样一个一维的流(CommonTreeNodeStream)。所以我们也可以把tree grammar看做是隐含了"down"和"up"虚构token的普通parser grammar。那么,tree grammar中需要的lookahead个数的分析,也就跟parser grammar的一样。
看看下面的例子。对于上一篇variableDeclaration的重写规则中出现的变量声明的类型,可以用这样的tree grammar来匹配:
树语法的^( ... )就隐含了"down"和"up"这两个虚构token。实际上这条规则匹配的是:
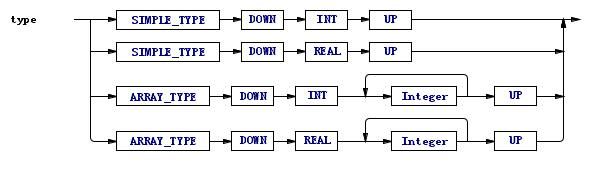
可以很清楚的看到"down"和"up"在规则中的位置。
在进入这条规则之后,需要多少个lookahead才足以判断应该选择哪条分支呢?
向前看一位:只能排除掉两个分支,还有两个,不够;
向前看两位:第二位是什么呢?四个分支里第二位都是"down"节点,对判断分支没帮助,还是不够用;
向前看三位:SIMPLE和ARRAY、INT和REAL都能分开了,足够。
那么对这条规则而言,需要3个lookahead。阅读ANTLR生成的源码,可以看到input.LA(3)这样的调用,表示向前看第三位的token。每多一个lookahead,生成的代码就得多以层嵌套的if-else,很是麻烦。
如果能调整一下parser这边生成的AST的结构,让tree grammar那边能写成:
那么这两条规则都只需要1个lookahead就足以判断分支了,比原本的写法要简单,也会稍微快一些。写了个Ruby脚本来检查生成的源码里用的lookahead的个数(*):
明白了这个道理,就应该尽量将重写规则中的各个根节点设计成能直接区分的。
实际上不只是树的语法,在编程语言的源码的语法设计上也是一样:最容易解析的语法是每条规则都以特殊的token开头的语法,例如说声明变量就以 var关键字开头,声明函数就以 function关键字开头等。这样能保证语法只需要1个lookahead。而类似C的语法对解析器来说实在算不上友善……|||
(*:ANTLR在遇到比较复杂的判断条件时不会直接在规则对应的方法里调用input.LA(n),而是会生成一个DFA类来计算应该走的分支。上面的Ruby脚本不检查这个状况。)
其次,所有虚构token都添加了一些信息在后面。例如说原本一元负号的规则是:
则UNARY_MINUS这个虚构token将不包含任何文字、位置信息。因为MINUS原本携带的位置信息已经丢失了,所以如果后续处理中需要知道这个表达式的位置就没办法得到。
改写为这样:
则使得UNARY_MINUS继承MINUS匹配时的文字、位置等属性,解决了前面的问题。
除此之外,原本写在program规则里的嵌入动作也去掉了。之前写在那里主要是为了在parser内输出AST的字符串表示,只是演示用。
修改后的完整语法如下:
同上一篇一样,也写一个启动lexer和parser的程序。这次是用C#来写:
因为使用了DOTTreeGenerator,编译时记得在引用Antlr3.Runtime.dll之外,还需要引用Antlr3.Utility.dll与StringTemplate.dll。
继续使用前两篇用过的Jerry代码为例子:
通过上面的程序,可以得到这样的AST:

(点击放大)
上面的程序生成的是.dot文件(输出到标准输出流上)。使用Graphviz的dot,将这个文件以
这样的命令来转换,就能得到PNG图像。
本篇就到这里。下一篇看看遍历AST用的基本tree grammar。
一个简单的语言的语法(一):用ANTLR描述语法
一个简单的语言的语法(二):ANTLR的重写规则
一个简单的语言的语法(三):做些小调整,并将生成目标换到CSharp2
为了后面的tree grammar更简洁,本篇对 上一篇的树重写规则和一些语法细节做了些调整。并且,将生成的lexer和parser的源码目标换到了CSharp2,以便后面能使用一些.NET的库。
要使用CSharp2的目标,需要从官网下载相应的运行时库。当前的最新版是3.1.1,可以从 这里获取。CSharp/CSharp2目标的详细情况,可以查阅 官网上的文档。以 上一篇的语法为基础,要换到CSharp2目标只要把几个嵌入动作里的System.out.println换成Console.WriteLine,把toStringTree换成ToStringTree,把clear换成Clear就可以了。编译的时候至少需要引用Antlr3.Runtime.dll。
那么除去更换生成目标带来的影响,这次做了些怎样的修改呢?
首先,语法做了些细微的调整。例如说,program规则从原本允许没有语句到现在要求至少有一条语句;blockStatement为空block写了条专门的分支;expressionStatement也添加了一个EXPR_STMT的虚构token为根节点,等等。
变化最大的还是variableDeclaration及相关规则。上一篇里这条规则的重写规则并不区分有初始化与无初始化、简单类型与数组类型的区别;本篇里则将这两个区别都明确的写在了重写规则里,以不同的虚构token来作为生成的树的根节点。这样,到写后面的tree grammar的时候,需要的lookahead数就可以减少。
ANTLR所生成的AST,以深度优先的方式遍历,可以看做一个一维的流:每一层父子关系都可以表示为:
root -> "down" -> element1 -> element2 -> ... -> elementN -> "up" -> ...
其中"down"和"up"是ANTLR插入的虚构token,用于指定树的层次。
这样,后面使用tree grammar来遍历AST时,实际上遍历的就是这样一个一维的流(CommonTreeNodeStream)。所以我们也可以把tree grammar看做是隐含了"down"和"up"虚构token的普通parser grammar。那么,tree grammar中需要的lookahead个数的分析,也就跟parser grammar的一样。
看看下面的例子。对于上一篇variableDeclaration的重写规则中出现的变量声明的类型,可以用这样的tree grammar来匹配:
type : ^( SIMPLE_TYPE INT ) | ^( SIMPLE_TYPE REAL ) | ^( ARRAY_TYPE INT Integer+ ) | ^( ARRAY_TYPE REAL Integer+ ) ;
树语法的^( ... )就隐含了"down"和"up"这两个虚构token。实际上这条规则匹配的是:
可以很清楚的看到"down"和"up"在规则中的位置。
在进入这条规则之后,需要多少个lookahead才足以判断应该选择哪条分支呢?
向前看一位:只能排除掉两个分支,还有两个,不够;
向前看两位:第二位是什么呢?四个分支里第二位都是"down"节点,对判断分支没帮助,还是不够用;
向前看三位:SIMPLE和ARRAY、INT和REAL都能分开了,足够。
那么对这条规则而言,需要3个lookahead。阅读ANTLR生成的源码,可以看到input.LA(3)这样的调用,表示向前看第三位的token。每多一个lookahead,生成的代码就得多以层嵌套的if-else,很是麻烦。
如果能调整一下parser这边生成的AST的结构,让tree grammar那边能写成:
simpleType : INT | REAL ; arrayType : ^( INT Integer+ ) | ^( REAL Integer+ ) ;
那么这两条规则都只需要1个lookahead就足以判断分支了,比原本的写法要简单,也会稍微快一些。写了个Ruby脚本来检查生成的源码里用的lookahead的个数(*):
def check_lookaheads(file)
lookaheads = open file, 'r' do |f|
ret = []
f.readlines.grep(/^\s+(.+\.la\((\d+)\).+)$/i) do
ret << "#{$2}: #{$1}"
end
ret
end
end
if __FILE__ == $0
la = check_lookaheads ARGV[0] || 'JerryParser.cs'
puts 'Lookaheads:', la, ''
puts "Non-LL(1)'s:", la.select { |l| ?1 != l[0] }
end
明白了这个道理,就应该尽量将重写规则中的各个根节点设计成能直接区分的。
实际上不只是树的语法,在编程语言的源码的语法设计上也是一样:最容易解析的语法是每条规则都以特殊的token开头的语法,例如说声明变量就以 var关键字开头,声明函数就以 function关键字开头等。这样能保证语法只需要1个lookahead。而类似C的语法对解析器来说实在算不上友善……|||
(*:ANTLR在遇到比较复杂的判断条件时不会直接在规则对应的方法里调用input.LA(n),而是会生成一个DFA类来计算应该走的分支。上面的Ruby脚本不检查这个状况。)
其次,所有虚构token都添加了一些信息在后面。例如说原本一元负号的规则是:
MINUS primaryExpression -> ^( UNARY_MINUS primaryExpression )
则UNARY_MINUS这个虚构token将不包含任何文字、位置信息。因为MINUS原本携带的位置信息已经丢失了,所以如果后续处理中需要知道这个表达式的位置就没办法得到。
改写为这样:
MINUS primaryExpression -> ^( UNARY_MINUS[$MINUS] primaryExpression )
则使得UNARY_MINUS继承MINUS匹配时的文字、位置等属性,解决了前面的问题。
除此之外,原本写在program规则里的嵌入动作也去掉了。之前写在那里主要是为了在parser内输出AST的字符串表示,只是演示用。
修改后的完整语法如下:
grammar Jerry;
options {
language = CSharp2;
output = AST;
ASTLabelType = CommonTree;
}
tokens {
// imaginary tokens
SIMPLE_VAR_DECL;
SIMPLE_VAR_DECL_INIT;
ARRAY_VAR_DECL;
ARRAY_VAR_DECL_INIT;
ARRAY_LITERAL;
SIMPLE_VAR_ACCESS;
ARRAY_VAR_ACCESS;
UNARY_MINUS;
BLOCK;
EMPTY_BLOCK;
EXPR_STMT;
}
// parser rules
program : statement+ EOF!
;
statement
: expressionStatement
| variableDeclaration
| blockStatement
| ifStatement
| whileStatement
| breakStatement
| readStatement
| writeStatement
;
expressionStatement
: expression SEMICOLON
-> ^( EXPR_STMT[$expression.start, "ExprStmt"] expression )
;
variableDeclaration
: typeSpecifier
( id1=Identifier
( ( -> ^( SIMPLE_VAR_DECL[$id1, "VarDecl"] ^( typeSpecifier ) $id1 ) )
| ( EQ expression
-> ^( SIMPLE_VAR_DECL_INIT[$id1, "VarDeclInit"] ^( typeSpecifier ) $id1 expression ) )
| ( ( LBRACK Integer RBRACK )+
-> ^( ARRAY_VAR_DECL[$id1, "VarDecl"] ^( typeSpecifier Integer+ ) $id1 ) )
| ( ( LBRACK Integer RBRACK )+ EQ arrayLiteral
-> ^( ARRAY_VAR_DECL_INIT[$id1, "VarDeclInit"] ^( typeSpecifier Integer+ ) $id1 arrayLiteral ) )
)
)
( COMMA id2=Identifier
( ( -> $variableDeclaration ^( SIMPLE_VAR_DECL[$id2, "VarDecl"] ^( typeSpecifier) $id2 ) )
| ( EQ exp=expression
-> $variableDeclaration ^( SIMPLE_VAR_DECL_INIT[$id2, "VarDeclInit"] ^( typeSpecifier ) $id2 $exp ) )
| ( ( LBRACK dim1+=Integer RBRACK )+
-> $variableDeclaration ^( ARRAY_VAR_DECL[$id2, "VarDecl"] ^( typeSpecifier $dim1+ ) $id2 ) )
| ( ( LBRACK dim2+=Integer RBRACK )+ EQ al=arrayLiteral
-> $variableDeclaration ^( ARRAY_VAR_DECL_INIT[$id2, "VarDeclInit"] ^( typeSpecifier $dim2+ ) $id2 $al ) )
)
{ if (null != $dim1) $dim1.Clear(); if (null != $dim2) $dim2.Clear(); }
)*
SEMICOLON
;
typeSpecifier
: INT | REAL
;
arrayLiteral
: LBRACE
arrayLiteralElement ( COMMA arrayLiteralElement )*
RBRACE
-> ^( ARRAY_LITERAL[$LBRACE, "Array"] arrayLiteralElement+ )
;
arrayLiteralElement
: expression
| arrayLiteral
;
blockStatement
: LBRACE statement+ RBRACE
-> ^( BLOCK[$LBRACE, "Block"] statement+ )
| LBRACE RBRACE // empty block
-> EMPTY_BLOCK[$LBRACE, "EmptyBlock"]
;
ifStatement
: IF^ LPAREN! expression RPAREN! statement ( ELSE! statement )?
;
whileStatement
: WHILE^ LPAREN! expression RPAREN! statement
;
breakStatement
: BREAK SEMICOLON!
;
readStatement
: READ^ variableAccess SEMICOLON!
;
writeStatement
: WRITE^ expression SEMICOLON!
;
variableAccess
: Identifier
( -> ^( SIMPLE_VAR_ACCESS[$Identifier, "VarAccess"] Identifier )
| ( LBRACK Integer RBRACK )+
-> ^( ARRAY_VAR_ACCESS[$Identifier, "VarAccess"] Identifier Integer+ )
)
;
expression
: assignmentExpression
| logicalOrExpression
;
assignmentExpression
: variableAccess EQ^ expression
;
logicalOrExpression
: logicalAndExpression ( OROR^ logicalAndExpression )*
;
logicalAndExpression
: relationalExpression ( ANDAND^ relationalExpression )*
;
relationalExpression
: additiveExpression ( relationalOperator^ additiveExpression )?
| BANG^ relationalExpression
;
additiveExpression
: multiplicativeExpression ( additiveOperator^ multiplicativeExpression )*
;
multiplicativeExpression
: primaryExpression ( multiplicativeOperator^ primaryExpression )*
;
primaryExpression
: variableAccess
| Integer
| RealNumber
| LPAREN! expression RPAREN!
| MINUS primaryExpression
-> ^( UNARY_MINUS[$MINUS] primaryExpression )
;
relationalOperator
: LT | GT | EQEQ | LE | GE | NE
;
additiveOperator
: PLUS | MINUS
;
multiplicativeOperator
: MUL | DIV
;
// lexer rules
LPAREN : '('
;
RPAREN : ')'
;
LBRACK : '['
;
RBRACK : ']'
;
LBRACE : '{'
;
RBRACE : '}'
;
COMMA : ','
;
SEMICOLON
: ';'
;
PLUS : '+'
;
MINUS : '-'
;
MUL : '*'
;
DIV : '/'
;
EQEQ : '=='
;
NE : '!='
;
LT : '<'
;
LE : '<='
;
GT : '>'
;
GE : '>='
;
BANG : '!'
;
ANDAND : '&&'
;
OROR : '||'
;
EQ : '='
;
IF : 'if'
;
ELSE : 'else'
;
WHILE : 'while'
;
BREAK : 'break'
;
READ : 'read'
;
WRITE : 'write'
;
INT : 'int'
;
REAL : 'real'
;
Identifier
: LetterOrUnderscore ( LetterOrUnderscore | Digit )*
;
Integer : Digit+
;
RealNumber
: Digit+ '.' Digit+
;
fragment
Digit : '0'..'9'
;
fragment
LetterOrUnderscore
: Letter | '_'
;
fragment
Letter : ( 'a'..'z' | 'A'..'Z' )
;
WS : ( ' ' | '\t' | '\r' | '\n' )+ { $channel = HIDDEN; }
;
Comment
: '/*' ( options { greedy = false; } : . )* '*/' { $channel = HIDDEN; }
;
LineComment
: '//' ~('\n'|'\r')* '\r'? '\n' { $channel = HIDDEN; }
;
同上一篇一样,也写一个启动lexer和parser的程序。这次是用C#来写:
using System;
using System.IO;
using Antlr.Runtime; // Antlr3.Runtime.dll
using Antlr.Runtime.Tree;
using Antlr.Utility.Tree; // Antlr3.Utility.dll
sealed class TestJerryAst {
static void PrintUsage( ) {
Console.WriteLine( "Usage: TestJerryAst [-dot] <source file>" );
}
static void Main( string[] args ) {
bool generateDot = false;
string srcFile;
switch ( args.Length ) {
case 0:
PrintUsage( );
return;
case 1:
if ( !File.Exists( args[ 0 ] ) ) goto case 0;
srcFile = args[ 0 ];
break;
default:
if ( "-dot" == args[ 0 ] ) {
generateDot = true;
if ( !File.Exists( args[ 1 ] ) ) goto case 0;
srcFile = args[ 1 ];
} else {
goto case 1;
}
break;
}
var input = new ANTLRReaderStream( File.OpenText( srcFile ) );
var lexer = new JerryLexer( input );
var tokens = new CommonTokenStream( lexer );
var parser = new JerryParser( tokens );
var programReturn = parser.program();
var ast = ( CommonTree ) programReturn.Tree;
// Generate DOT diagram if -dot option is given
if ( generateDot ) {
var dotgen = new DOTTreeGenerator( );
var astDot = dotgen.ToDOT( ast );
Console.WriteLine( astDot );
} else {
Console.WriteLine( ast.ToStringTree( ) );
}
}
}
因为使用了DOTTreeGenerator,编译时记得在引用Antlr3.Runtime.dll之外,还需要引用Antlr3.Utility.dll与StringTemplate.dll。
继续使用前两篇用过的Jerry代码为例子:
// line comment
// declare variables with/without initializers
int i = 1, j;
int x = i + 2 * 3 - 4 / ( 6 - - 7 );
int array[2][3] = {
{ 0, 1, 2 },
{ 3, 4, 6 }
};
/*
block comment
*/
while (i < 10) i = i + 1;
while (!x > 0 && i < 10) {
x = x - 1;
if (i < 5) break;
else read i;
}
write x - j;
通过上面的程序,可以得到这样的AST:
(点击放大)
上面的程序生成的是.dot文件(输出到标准输出流上)。使用Graphviz的dot,将这个文件以
dot JerrySample.dot -Tpng -o JerrySample.png
这样的命令来转换,就能得到PNG图像。
本篇就到这里。下一篇看看遍历AST用的基本tree grammar。