简介
在前面的文章里曾经总结过最普通的java网络编程流程。在那里,我们通过一个简单的单进程server来处理一个个的客户端请求。这是一个简单的blocking IO模型,在实际中,我们可能要面对的是大量的客户端请求,我们更加具体实际的做法是该怎么办呢?这里,我针对常用的Blocking IO和Non-Blocking IO两种方式进行比较,结合一些经典的论文和材料,看看NIO的步骤和特点。
Blocking IO
先从这个开始讨论起,在前面的文章里,我们知道一个server端的程序要和一个客户端通信,它首先自己要绑定到一个端口,然后调用accept方法来接收一个客户端的请求并建立连接。这个accept返回的socket连接可以获取到双方通信的InputStream和OutputStream,这样双方就可以通过这两个Stream来互相发消息了。
当然,对于单独的一个server进程和一个client进程来说,这是一个典型的场景。但是如果对于有多个client的情况下,我们该怎么来处理呢?一种典型的思路就是,我们针对每一个client连接请求建立一个thread来处理。这种模式如下图:
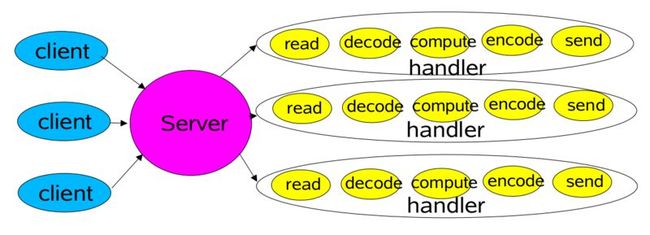
按照这种思路,针对每一个client,我们都有一个对应的handler来处理他们的业务逻辑。每个handler对应一个线程。我们也可以很容易得到一组如下的代码参考实现:
class Server implements Runnalbe {
public void run() {
try {
ServerSocket ss = new ServerSocket(PORT);
while(!Thread.interrupted())
new Thread(new Handler(ss.accept())).start();
// or, single-threaded, or a thread pool
} catch(IOException ex) { /* ... */ }
}
static class Handler implements Runnalbe {
final Socket socket;
Handler(Socket s) { socket = s; }
public void run() {
try {
byte[] input = new byte[MAX_INPUT];
socket.getInputStream().read(input);
byte[] output = process(input);
socket.getOutputStream().write(output);
} catch(IOException ex) { /* ... */ }
}
}
}
这里的代码很容易理解。我们针对每一个client建立一个连接,thread里首先通过InputStream读client的输入,然后处理,再通过OutputStream输出。在这个典型的过程里,每一个步骤都是同步的。比如说在server的accept方法返回结果前,我们的handler线程是什么都干不了的。handler里面读输入,处理,然后输出也都是一步接着一步,不会在一个还在做的时候就做别的事去了。
我们再想想,在有大量用户连接的情况下,server将针对所有连接client创建thread。如果有成千上万的连接的话,这将是一个很大的开销。由于系统资源实际的限制,可能会占用大量的资源甚至会导致资源被消耗光的情况。另外,这么多个线程连接需要处理,CPU需要在多个线程之间切换。在大量线程的情况下,切换的开销也很大。在这些情况下,请求量大的时候系统的性能和资源利用率都不高。那么我们有没有什么办法可以提高资源利用率和性能呢?
Non-Blocking IO
除了前面提到的blocking IO,其实还有一种io的方式,就是Non-Blocking IO。在详细讨论Non-Blocking IO之前,我们先看看原来blocking IO的一些不足。我们前面的每个连接一个线程的方式如下图所示:
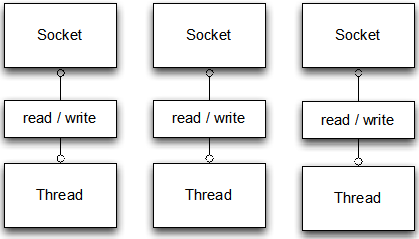
对于每一个连接的所有操作,从建立连接,准备数据,读取数据,编码,解码以及来回发送数据,都在一个线程里全包了。之所以会出现前面提到的资源利用率不高和系统性能受到影响,就是因为通过socket进行io的系统性能和系统本身进程性能本身是有大的差异的。一般来说,IO的性能比系统CPU的性能要差几个数量级。所以才会有大量线程要处理数据的时候,都卡在这里等IO了。这就是前面这种方式有问题的根源所在了。
那么,我们有没有什么办法可以改进一下呢?我们这个时候可以考虑一下异步程序执行的思路。一般对于异步程序执行来说,在调用某一个方法的时候,这个被调用的方法在另外的一个进程或者线程中执行。这个调用方法的进程并不等被调用的方法返回结果,而是继续执行自己后面的过程。可是,在调用的目标方法结束之后,我们怎么让这个调用方法的进程知道方法执行结束了并知道方法的结果呢?这个时候,我们很多时候会使用一种回调的机制。关于回调机制的思路,和我前面一篇讨论Observer模式的文章说的非常近似。笼统的来说,就是我这个调用方法的进程实现注册好了一个通知的机制,然后在被调用方法结束后,这个被调用的方法进程通过这个机制来通知我。
如果我们借鉴这个思路,比如说前面有一些客户端连接服务器端,它们只需要把要操作的目的资源,比如写某个文件之类的,针对哪个socket等等关联起来。等一旦socket连接准备好了再触发它们。这样就不需要开这么多个线程来等了。这些socket连接ready等行为相当于一个定义的一个事件被触发了。我们很多要被回调的方法都放在一个事件通知的队列里。这些回调事件的执行可以放到单独的一个线程里执行。这样也就不需要前面那么多的线程,也减少了线程间切换的开销。我们接着来看看这种思路的实现。
Reactor Pattern
Reactor pattern的模型结构如下图:
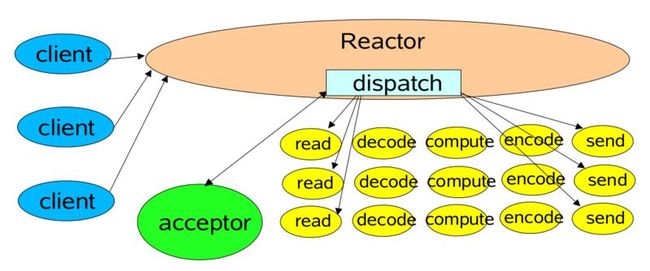
粗粗看来,这个模型不是很好懂。如果结合我们对observer pattern的一些理解来看会更加容易懂一些。 我们知道,在observer pattern里,要触发事件之前,事件是需要注册进去的。在某些时候还要将注册的事件注销。回想在我们的一些简单的实现里,就是通过一个list来保存注册的handler。然后事件发生后也就是便利这个list来回调这些方法。
这里的dispatcher就负责针对不同的事件注册不同的回调处理方法。和我们前面一些简单的observer pattern模型比较起来,这边关注的不仅仅是一个事件,而是有若干个。在一个事件里也许会有多个注册的回调方法。通过这个图中我们可以看到,我们常用的几个事件有read, compute, decode, encode, send等。另外,我们怎么知道某些事件被触发了呢?这里的reactor就是来提供这个的。通过它的select()方法,每次得到哪些事件被触发,这样我们就能去调用相应的回调方法。
结合reactor pattern,java nio里有一些对应的实现基础。我们在这里一一列举一下:
Channel: 和以往我们操作文件,socket等不同。以往是将io操作抽象到一个流式的结构里,而且读和写是分离的。这里是一个对文件或者socket的连接的抽象,我们可以对它进行非阻塞的操作。
Buffer: 可以通过Channel来直接对Buffer进行读写,一种类似于数组的对象。
Selector: 可以告诉我们哪一组channel有IO事件发生。这不正是我们前面图里的reactor吗?
SelectionKey: IO事件的状态和绑定的关系。比如我绑定的是一个什么事件对应什么操作。
针对刚才提出的这些概念,我们给出了一个参考的模型实现代码:
class Reactor implements Runnable {
final Selector selector;
final ServerSocketChannel serverSocket;
Reactor(int port) throws IOException {
selector = Selector.open();
serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(
new InetSocketAddress(port));
serverSocket.configureBlocking(false);
SelectionKey sk = serverSocket.register(
selector, SelectionKey.OP_ACCEPT);
sk.attach(new Acceptor());
}
public void run() {
try {
while(!Thread.interrupted()) {
selector.select();
Set selected = selector.selectedKeys();
Iterator it = selected.iterator();
while(it.hasNext())
dispatch((SelectionKey)(it.next()));
selected.clear();
}
} catch(IOException ex) { /* ... */ }
}
void dispatch(SelectionKey k) {
Runnable r = (Runnable) (k.attachment());
if(r != null)
r.run();
}
}
这里给出的一个典型实现比较有意思。首先我们看构造函数,这里的serverSocket注册了ACCEPT事件并在SelectionKey里添加了一个Acceptor对象。这一步是什么意思呢?这一步就相当于我们前面阻塞式操作里的socket.accept()方法。只不过这里是注册了ACCEPT这个事件,当真的有连接来了它就会被触发。SelectionKey里attach的这个Acceptor对象则相当于这个事件里附带的附件一样,在一开始只是被创建在那里,在后面的dispatch方法里,相当于事件发生了,我们则调用它们。关于Acceptor的实现我们先不详细讨论。我们目前可以将Acceptor对象当作一个后面事件处理的一个代理。
从前面构造函数里我们知道了绑定socket和accept事件,并将事件触发后要做什么都安排好了。这就是相当于安排好了回调的工作。有点前面图中Dispatcher的意思。我们再来看run方法。这里通过selector.select()方法来获取触发的事件。这部分正好对应前面图中Reactor的职责。它相当于一个单线程的无限循环,不停的收集触发的事件,一旦有某个事件发生,则通过dispatch方法去调用相关的事件处理机制。这里比较关键的是将Reactor实现成一个线程,可以让它单独来运行。
前面这一大堆代码相当于一个事件循环的基本架子,我们再看相关的Acceptor实现:
class Acceptor implements Runnalbe {
public void run() {
try {
SocketChannel c = serverSocket.accept();
if(c != null)
new Handler(selector, c);
} catch(IOException) { /* ... */ }
}
}
在这个实现里做了一些相对的简化。Acceptor也是作为单独的一个线程运行。它运行执行的时候创建了相关的Handler。参照前面部分的框架,整个的过程就是前面的事件循环注册了相关的Acceptor,当事件被触发的时候,Acceptor再创建对应的Handler来处理。因为我们注册事件都是针对某个资源,这里是Channel,然后某个事件进行绑定。所以Handler处理的时候可以根据channel和对应的事件来做对应的处理逻辑。
下面是一个参考的Handler实现:
final class Handler implements Runnable {
final SocketChannel socket;
final SelectionKey sk;
ByteBuffer input = ByteBuffer.allocate(MAXIN);
ByteBuffer output = ByteBuffer.allocate(MAXOUT);
static final int READING = 0, SENDING = 1;
int state = READING;
Handler(Selector sel, SocketChannel c) throws IOException {
socket = c;
c.configureBlocking(false);
sk = socket.register(sel, 0);
sk.attach(this);
sk.interestOps(SelectionKey.OP_READ);
sel.wakeup();
}
boolean inputIsComplete() { /* ... */ }
boolean outputIsComplete() { /* ... */ }
void process() { /* ... */ }
public void run() {
try {
if(state == READING) read();
else if(state == SENDING) send();
} catch(IOException ex) { /* ... */ }
}
void read() throw IOException {
socket.read(input);
if(inputIsComplete()) {
process();
state = SENDING;
sk.interestOps(SelectionKey.OP_WRITE);
}
}
void send() throws IOException {
socket.write(output);
if(outputIsComplete()) sk.cancel();
}
}
我们发现在构造函数里传入的selector和Channel都是通过Acceptor传递过来的。而这里又通过interestOps设置了OP_READ事件。有意思。这是什么意思?这里表示我们当accept到一个连接后,希望后面selector检查read事件是否就绪。如果可以的话我们可以根据本机设置的read状态读socketChannel。
而这里read方法里又设置了检查OP_WRITE,这里是表示当read操作执行完之后,我们希望能够让selector检查后续是否write事件就位。按照我们的通俗理解过程,既然读取完了客户端的请求后,我们该考虑写返回结果回去了,所以才设定为下一步对哪些事件感兴趣。这样我们不但保证了事件的触发而且还保证了事件的正常执行顺序。当然,我们根据需要可以自己设置不同的操作事件。
现在,在看完这个完整的过程之后,我们总结一下整个的过程。这里nio的主要步骤就是首先自己注册一个socketChannel的accept事件。为什么?因为我们所有的事件都是必须发生在channel上的,比如accept, read, write等。所以需要在它们上面注册,然后发生事件的时候由他们来通知。他们就相当于Observerable。然后我们有一个无限循环来通过Selector.select()找到是否有就绪的事件。这里主要就是针对该socket的accept事件。当有多个事件就绪的时候,就可能有某个回调事件去读,某个回调事件去写,这些都不冲突。accept事件处理完之后,相关的handler再根据情况去选择后面需要被触发的事件,它不是主动执行后面的逻辑,而是继续等事件循环到该期望的事件发生时,通过这个循环里触发的线程来调用他们。
因为我们要保证足够的吞吐量和性能,所以不能让这个事件循环的线程被阻塞。所以在代码的实现里就是通过将回调方法放到另外的一个线程里执行。这样,整个过程的思路就确定下来了。
前面的这个reactor pattern主要是针对单个reactor线程来设计的。如果只是一个线程不断的循环,然后在其他触发的事件里再不断的更新设置的事件,这里对于若干个事件的处理确实是够了的。可是现在我们的计算机基本上都是多核多cpu的结构。如果我们能够充分利用一下这些岂不是更好?
Multithreaded Design
结合前面的讨论,我们实际上可以做一些改进来进一步提升整体设计的性能和吞吐量。主要考虑有一下几个点:
1. 需要考虑多核的情况,怎么充分利用多核。
2. Reactor主要是事件循环和触发,我们必须让这个过程比较快。不能因为调用handler而拖慢速度。
3. 既然要用到多个线程,怎么来充分提升利用这些线程的效率和性能,是否可以考虑线程池?
实际上结合这些点的考虑,我们新的多线程设计方案有了这么些个增强:
1. 既然我们希望reactor跑的快,不能让它们被handler拖慢,可以将里面的事件做一些划分。reactor主要关注网络操作相关的读写,比如accept, read, write。而从前面代码里我们看到的那些业务逻辑相关的,比如数据怎么处理,可以单独放到另外的线程里去做。这样可以进一步减轻reactor的负担。我们这些单独分离出来的线程就可以称为worker thread。
2. 对于怎么有效利用这些线程,我们可以将worker thread组织成线程池,这样更好的提升效率。
3. 另外一个就是,我们也可以建多个reactor,充分利用起系统的资源来。这些reactor甚至也可以按照池的方式组织起来。
总的来说,这种多线程版优化的结构如下图:
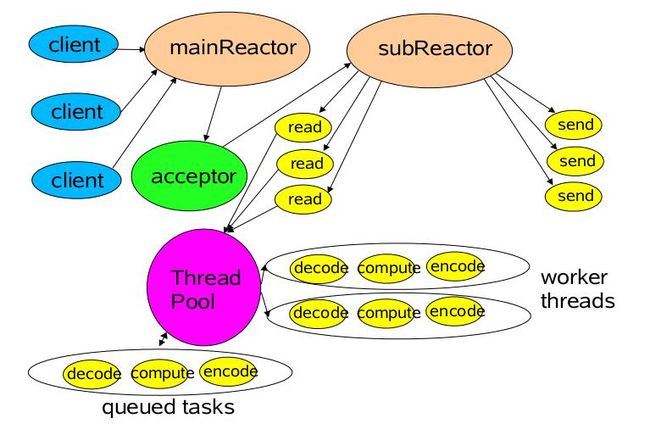
按照前面讨论的方式,如果我们handlers用线程池的话,则一部分示例代码需要修改成如下的样式:
final class Handler implements Runnable {
static PooledExecutor pool = new PooledExecutor(...);
static final int PROCESSING = 3;
//...
synchronized void read() throw IOException {
socket.read(input);
if(inputIsComplete()) {
state = PROCESSING;
pool.execute(new Processor());
}
}
synchronized void processAndHandOff() {
process();
state = SENDING;
sk.interest(SelectionKey.OP_WRITE);
}
class Processor implements Runnalbe {
public void run() { processAndHandOff(); }
}
}
我们可以看到一些必要的方法访问需要进行专门同步了。当然,对应的Acceptor也可能会修改成将连接分布到多个reactor中:
Selector[] selectors;
int next = 0;
class Acceptor implements Runnalbe {
public synchronized void run() {
try {
SocketChannel c = serverSocket.accept();
if(c != null)
new Handler(selector[next], c);
if(++next == selectors.length) next = 0;
} catch(IOException) { /* ... */ }
}
}
当然,很多其他地方也需要这么相应的变化。总的来说,这样的结构能够达到一个既能充分利用系统资源又能达到一个比较高性能的要求。
总结
Blocking IO和Non-Blocking IO一直是一个比较难理解的地方。Blocking IO主要是里面的方法操作步骤都是同步的,而Non-Blocking IO则不是。它是通过注册事件来触发对应的handler来执行。比起thread per connection的方式,它能更好的利用资源。因为回调的机制对于异步的通信方式来说减少了轮询或者其它强制同步机制的开销,效率算是比较理想的。最后我们得出的那个多线程的解决方案在一些告诉的网络通信框架比如netty里得到应用。它既保证了支持高并发量又充分利用了系统资源。可以说是一种异步+多线程的一个结合。
另外,在后面附件所带的源代码里有一个简单的nio client和server实现,我们可以结合代码来进一步理解nio。
参考资料
Reactor An object Behavioral Pattern for Demulplexing and Dispatching Handles for Synchronous Events
http://www.kegel.com/c10k.html