集合初探--集合中的设计模式之Iterator模式
1. Iterator模式
·标准定义:提供一种统一的方法顺序访问一个聚合对象中各个元素,而又不需要暴露对象的内部表示。

·其本质体现了面向对象单一职责原则:一个聚合对象提供两个职责,一是组织管理数据对象,二是提供遍历算法。遍历算法会变,那么就隔离变化,抽象为一个迭代器,从而使得聚合对象职责单一。
2. 集合中的Iterator模式
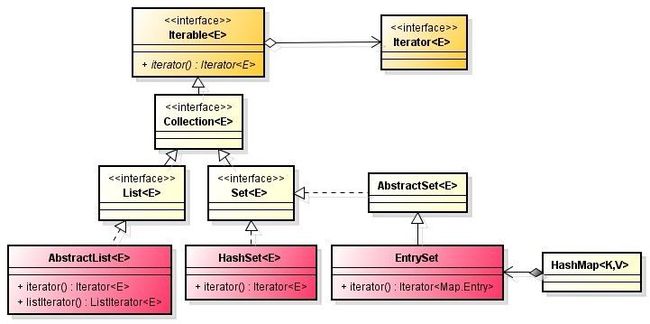
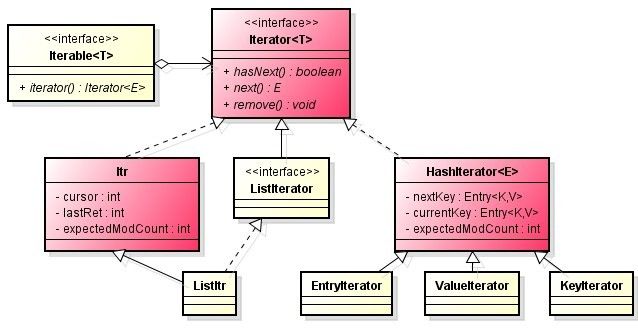
·Iterator模式是用于遍历集合类的标准访问方法。它可以把访问逻辑从不同类型的集合类中抽象出来,从而避免向客户端暴露集合的内部结构。
例如,如果没有使用Iterator,遍历一个数组的方法是使用索引:
而访问一个链表(LinkedList)又必须使用while循环:
·以上两种方法客户端都必须事先知道集合的内部结构,访问代码和集合本身是紧耦合,无法将访问逻辑从集合类和客户端代码中分离出来,每一种集合对应一种遍历方法,客户端代码无法复用。
·如果以后需要把ArrayList更换为LinkedList,则原来的客户端代码必须全部重写。
·为解决以上问题,Iterator模式总是用同一种逻辑来遍历集合:
·客户端自身不维护遍历集合的信息,所有的内部状态(如当前元素位置,是否有下一个元素)都由Iterator来维护,而这个Iterator由集合类通过工厂方法生成,因此,它知道如何遍历整个集合。
·客户端从不直接和集合类打交道,它总是控制Iterator,向它发送"向前","向后","取当前元素"的命令,就可以间接遍历整个集合。客户端不关心到底是哪种Iterator,它只需要获得这个Iterator接口即可,这就是面向抽象的威力。
3. Iterator源码剖析
·首先看看java.util.Iterator接口的定义:
·再来看看AbstracyList如何创建Iterator。首先AbstractList定义了一个内部类(inner class,以便能访问集合属性):
而iterator()方法的定义是:
因此客户端不知道它通过Iterator it = a.iterator();所获得的Iterator的真正类型。
·那么private的Itr类是如何实现遍历AbstractList的?
·Itr类依靠3个int变量来实现遍历,cursor是下一次next()调用时元素的位置,第一次调用next()将返回索引为0的元素。lastRet记录上一次游标所在位置,因此它总是比cursor少1。
·变量cursor和集合的元素个数决定hasNext():
·方法next()返回的是索引为cursor的元素,然后修改cursor和lastRet的值:
·其他集合Iterator的遍历方式类似,不在细说。
·标准定义:提供一种统一的方法顺序访问一个聚合对象中各个元素,而又不需要暴露对象的内部表示。
·其本质体现了面向对象单一职责原则:一个聚合对象提供两个职责,一是组织管理数据对象,二是提供遍历算法。遍历算法会变,那么就隔离变化,抽象为一个迭代器,从而使得聚合对象职责单一。
2. 集合中的Iterator模式
·Iterator模式是用于遍历集合类的标准访问方法。它可以把访问逻辑从不同类型的集合类中抽象出来,从而避免向客户端暴露集合的内部结构。
例如,如果没有使用Iterator,遍历一个数组的方法是使用索引:
for(int i=0; i<array.size(); i++) { ... get(i) ... }
而访问一个链表(LinkedList)又必须使用while循环:
while((e=e.next())!=null) { ... e.data() ... }
·以上两种方法客户端都必须事先知道集合的内部结构,访问代码和集合本身是紧耦合,无法将访问逻辑从集合类和客户端代码中分离出来,每一种集合对应一种遍历方法,客户端代码无法复用。
·如果以后需要把ArrayList更换为LinkedList,则原来的客户端代码必须全部重写。
·为解决以上问题,Iterator模式总是用同一种逻辑来遍历集合:
for(Iterator it = c.iterater(); it.hasNext(); ) {
Object o = it.next();
// 对o的操作...
}
·客户端自身不维护遍历集合的信息,所有的内部状态(如当前元素位置,是否有下一个元素)都由Iterator来维护,而这个Iterator由集合类通过工厂方法生成,因此,它知道如何遍历整个集合。
·客户端从不直接和集合类打交道,它总是控制Iterator,向它发送"向前","向后","取当前元素"的命令,就可以间接遍历整个集合。客户端不关心到底是哪种Iterator,它只需要获得这个Iterator接口即可,这就是面向抽象的威力。
3. Iterator源码剖析
·首先看看java.util.Iterator接口的定义:
public interface Iterator {
boolean hasNext();
Object next();
void remove();
}
·再来看看AbstracyList如何创建Iterator。首先AbstractList定义了一个内部类(inner class,以便能访问集合属性):
private class Itr implements Iterator {
...
}
而iterator()方法的定义是:
public Iterator iterator() {
return new Itr();
}
因此客户端不知道它通过Iterator it = a.iterator();所获得的Iterator的真正类型。
·那么private的Itr类是如何实现遍历AbstractList的?
private class Itr implements Iterator {
int cursor = 0;
int lastRet = -1;
int expectedModCount = modCount;
}
·Itr类依靠3个int变量来实现遍历,cursor是下一次next()调用时元素的位置,第一次调用next()将返回索引为0的元素。lastRet记录上一次游标所在位置,因此它总是比cursor少1。
·变量cursor和集合的元素个数决定hasNext():
public boolean hasNext() {
return cursor != size(); //下一个元素位置不等于集合的大小
}
·方法next()返回的是索引为cursor的元素,然后修改cursor和lastRet的值:
public Object next() {
checkForComodification();
try {
Object next = get(cursor);
lastRet = cursor++;
return next;
} catch(IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
·其他集合Iterator的遍历方式类似,不在细说。