什么是异常,我们为什么要关心它?
什么是异常,我们为什么要关心它?
单词“exception”是短语“exceptional event(异常事件)”的缩写,它定义如下:
定义:异常是程序在执行时发生的事件,它会打断指令的正常流程。
许多种类的错误将触发异常,这些问题从像硬盘(crash)坠毁这样的严重硬件错误,到尝试访问越界数组元素这样的简单程序错误,像这样的错误如果在java函数中发生,函数将创建一个异常对象并把他抛出到运行时系统(runtime system)。异常对象包含异常的信息,包括异常的类型,异常发生时程序的状态。运行时系统则有责任找到一些代码处理这个错误。在java技术词典中,创建一个异常对象并把它抛给运行时系统叫做:抛出异常(throwing an exception)。
当某个函数抛出一个异常后,运行时系统跳入了这样一个动作,就是找到一些人(译者注:其实是代码)来处理这个异常。要找的处理异常的可能的人(代码)的集合(set)是:在发生异常的方法的调用堆栈(call stack)中的方法的集合(set)。运行时系统向后搜寻调用堆栈,从错误发生的函数,一直到找到一个包括合适的异常处理器(exception handler)的函数。一个异常处理器是否合适取决于抛出的异常是否和异常处理器处理的异常是同一种类型。因而异常向后寻找整个调用堆栈,直到一个合格的异常处理器被找到,调用函数处理这个异常。异常处理器的选择被叫做:捕获异常(catch the exception)。
如果运行时系统搜寻整个调用堆栈都没有找到合适的异常处理器,运行时系统将结束,随之java程序也将结束。
使用异常来管理错误,比传统的错误管理技术有如下优势:
1. 将错误处理代码于正常的代码分开。
2. 沿着调用堆栈向上传递错误。
3. 将错误分作,并区分错误类型。
1. 将错误处理代码于正常的代码分开。
在传统的程序种,错误侦测,报告,和处理,经常导致令人迷惑的意大利面条式(spaghetti)的代码。例如,假设你要写一个将这个文件读到内存种的函数,用伪代码描述,你的函数应该是这个样子的:
readFile{
open the file; //打开文件
determine its size; //取得文件的大小
allocate that much memory; //分配内存
read the file into memory; //读文件内容到内存中
close the file; //关闭文件
}
匆匆一看,这个版本是足够的简单,但是它忽略了所有潜在的问题:
· 文件不能打开将发生什么?
· 文件大小不能取得将发生什么?
· 没有足够的内存分配将发生什么?
· 读取失败将发生什么?
· 文件不能关闭将发生什么?
为了在read_file函数中回答这些错误,你不得不加大量的代码进行错误侦测,报告和处理,你的函数最后将看起来像这个样子:
errorCodeType readFile {
initialize errorCode = 0;
open the file;
if (theFileIsOpen) {
determine the length of the file;
if (gotTheFileLength) {
allocate that much memory;
if (gotEnoughMemory) {
read the file into memory;
if (readFailed) {
errorCode = -1;
}
} else {
errorCode = -2;
}
} else {
errorCode = -3;
}
close the file;
if (theFileDidntClose && errorCode == 0) {
errorCode = -4;
} else {
errorCode = errorCode and -4;
}
} else {
errorCode = -5;
}
return errorCode;
}
随着错误侦测的建立,你的最初的7行代码(粗体)已经迅速的膨胀到了29行-几乎400%的膨胀率。更糟糕的是有这样的错误侦测,报告和错误返回值,使得最初有意义的7行代码淹没在混乱之中,代码的逻辑流程也被淹没。很难回答代码是否做的正确的事情:如果函数分配内容失败,文件真的将被关闭吗?更难确定当你在三个月后再次修改代码,它是否还能够正确的执行。许多程序员“解决”这个问题的方法是简单的忽略它,那样错误将以死机来报告自己。
对于错误管理,Java提供一种优雅的解决方案:异常。异常可以使你代码中的主流程和处理异常情况的代码分开。如果你用异常代替传统的错误管理技术,readFile函数将像这个样子:
readFile {
try {
open the file;
determine its size;
allocate that much memory;
read the file into memory;
close the file;
} catch (fileOpenFailed) {
doSomething;
} catch (sizeDeterminationFailed) {
doSomething;
} catch (memoryAllocationFailed) {
doSomething;
} catch (readFailed) {
doSomething;
} catch (fileCloseFailed) {
doSomething;
}
}
注意:异常并不能节省你侦测,报告和处理错误的努力。异常提供给你的是:当一些不正常的事情发生时,将所有蹩脚(grungy)的细节,从你的程序主逻辑流程中分开。
另外,异常错误管理的膨胀系数大概是250%,比传统的错误处理技术的400%少的多。
2. 沿着调用堆栈向上传递错误。
异常的第二个优势是,可以沿着函数的调用堆栈向上报告错误。设想,readFile函数是一系列嵌套调用函数中的第四个函数:method1调用method2, method2 调用method3,最后method3调用readFile。
method1 {
call method2;
}
method2 {
call method3;
}
method3 {
call readFile;
}
如果只有method1对发生在readFile中的错误感兴趣。传统的错误通知技术迫使mothed2和mothed3沿着调用堆栈向上传递readFile的错误代码,直到到达对错误感兴趣的mothed1。
method1 {
errorCodeType error;
error = call method2;
if (error)
doErrorProcessing;
else
proceed;
}
errorCodeType method2 {
errorCodeType error;
error = call method3;
if (error)
return error;
else
proceed;
}
errorCodeType method3 {
errorCodeType error;
error = call readFile;
if (error)
return error;
else
proceed;
}
就像前面所了解到的,java运行时系统向后(baskward,也就是向上)搜寻调用堆栈,找到对处理这个异常感兴趣的函数。Java函数可以“躲开(duck)”任何在函数中抛出的异常,因此,允许函数穿越过调用堆栈捕获它。那个唯一对错误感兴趣的函数method1,将负责(worry about)侦测错误。
method1 {
try {
call method2;
} catch (exception) {
doErrorProcessing;
}
}
method2 throws exception {
call method3;
}
method3 throws exception {
call readFile;
}
然而,就像你在伪代码中看到的,在“中间人(中间的函数methoed2和method3)”忽略异常需要受到影响,一个函数如果要抛出一个异常,必须在函数的公共接口声明中使用throws关键字指定。因此,一个函数可以通知它的调用者自己会抛出什么样的异常,这样调用者就可以有意识的决定对这些异常做些什么。
再一次注意异常和传统错误处理方式,在膨胀系数和迷惑系数的区别。使用异常的代码更简洁,更容易理解。
3. 将错误分作,并区分错误类型。
异常(们)经常被划分成类别或组。例如,你可以想象一组异常,它们中每一个都表示关于数组操作的的特殊的异常:索引超出数组的范围,要插入的元素是错误的类型,要查找的元素不在数组中。而且,你能想象一些函数将处理所有这类的异常(关于数组的异常),其它一些函数将处理特殊异常(仅仅是无效索引异常)。
由于在java程序中所有的异常首先是一个对象,异常的分组和分类成为类继承自然而然的结果。Java异常必须是Throwable或者是Throwable子类的实例。就像你可以从其它java类继承一样,你也可以创建Thowable的子类,或者孙子类(从Thowable子类继承)。每个叶子节点(没有子类的类),代表一种特殊类型的异常,每个节点(node)(有一个或者更多子类的类)代表一组有关联的异常。
例如,在下列图表中,ArrayException是Exception的子类(Throwable的一个子类),它有三个子类。
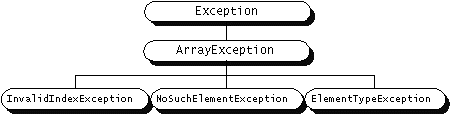
InvalidIndexException, ElementTypeException,和NoSuchElementException都是叶子类,它们都是在操作数组时发生的错误。捕获异常的一种方法是仅仅捕捉那些叶子类的实例。例如,一个异常控制器仅仅捕捉无效索引异常,它的代码像这个样子:
catcatch (InvalidIndexException e) { . . .}ArrayExecption是节点(node)类,代表你在操作数组时发生的任何错误,包括特定代表一个错误的所有子类中的任何一个。如果一个函数要一组或者一类异常,只要在在cathc语句中指定这些异常的超类(superclass)。例如,要捕捉所有数组异常而不指定具体类型,异常控制器将捕捉ArrayException:
catch (ArrayException e) { . . .}这个异常控制器将捕捉所有数组异常,包括InvalidIndexException, ElementTypeException, 和 NoSuchElementException。你可以在异常控制器的参数e中找到异常的精确的类型。你甚至可以建立这样的异常控制器,它处理所有的Exception。
catch (Exception e) { . . .}上面出示的异常控制器实在时太通用了,这样做使你的代码处理太多的错误,需要处理许多你不希望处理的异常,因而不能正确的处理异常。通常我们不推荐写通用的异常处理器。
就像你看到的,你能创建一组异常,并处理这些异常以通用的方式;你也能指定异常类型去区分异常,并处理异常以精确的方式。
What’s Next?
现在你能懂得在java程序中使用异常的好处,现在到了学习怎样去用它们的时候了。
转载自:the java tutorial