Quartz 进行作业调度
简介:
Quartz 是个开放源码项目,提供了丰富的作业调度集。在这篇文章中,软件工程师 Michael Lipton 和 IT 架构师 Soobaek Jang 对 Quartz API 进行了介绍,从对框架的一般概述开始,并以一系列展示 Quart 基本特性的代码示例作为结束。在阅读完本文并看过代码示例后,您应当能够把 Quartz 的基本特性应用到任何 Java™ 应用程序中。
现代的 Web 应用程序框架在范围和复杂性方面都有所发展,应用程序的每个底层组件也必须相应地发展。作业调度是现代系统中对 Java 应用程序的一般要求,而且也是对 Java 开发人员一贯的要求。虽然目前的调度技术比起原始的数据库触发器标志和独立的调度器线程来说,已经发展了许多,但是作业调度仍然不是个小问题。对这个问题最合适的解决方案就是来自 OpenSymphony 的 Quartz API。
Quartz 是个开源的作业调度框架,为在 Java 应用程序中进行作业调度提供了简单却强大的机制。Quartz 允许开发人员根据时间间隔(或天)来调度作业。它实现了作业和触发器的多对多关系,还能把多个作业与不同的触发器关联。整合了 Quartz 的应用程序可以重用来自不同事件的作业,还可以为一个事件组合多个作业。虽然可以通过属性文件(在属性文件中可以指定 JDBC 事务的数据源、全局作业和/或触发器侦听器、插件、线程池,以及更多)配置 Quartz,但它根本没有与应用程序服务器的上下文或引用集成在一起。结果就是作业不能访问 Web 服务器的内部函数;例如,在使用 WebSphere 应用服务器时,由 Quartz 调度的作业并不能影响服务器的动态缓存和数据源。
本文使用一系列代码示例介绍 Quartz API,演示它的机制,例如作业、触发器、作业仓库和属性。
入门
要开始使用 Quartz,需要用 Quartz API 对项目进行配置。步骤如下:
下载 Quartz API。
http://www.opensymphony.com/quartz/download.action
解压缩并把 quartz-x.x.x.jar 放在项目文件夹内,或者把文件放在项目的类路径中。
把 core 和/或 optional 文件夹中的 jar 文件放在项目的文件夹或项目的类路径中。
如果使用 JDBCJobStore,把所有的 JDBC jar 文件放在项目的文件夹或项目的类路径中。
为了方便读者,我已经把所有必要的文件,包括 DB2 JDBC 文件,编译到一个 zip 文件中。请参阅 下载 小节下载代码。
现在来看一下 Quartz API 的主要组件。
作业和触发器
Quartz 调度包的两个基本单元是作业和触发器。作业 是能够调度的可执行任务,触发器 提供了对作业的调度。虽然这两个实体很容易合在一起,但在 Quartz 中将它们分离开来是有原因的,而且也很有益处。
通过把要执行的工作与它的调度分开,Quartz 允许在不丢失作业本身或作业的上下文的情况下,修改调度触发器。而且,任何单个的作业都可以有多个触发器与其关联。
示例 1:作业
通过实现 org.quartz.job 接口,可以使 Java 类变成可执行的。清单 1 提供了 Quartz 作业的一个示例。这个类用一条非常简单的输出语句覆盖了 execute(JobExecutionContext context) 方法。这个方法可以包含我们想要执行的任何代码(所有的代码示例都基于 Quartz 1.5.2,它是编写这篇文章时的稳定发行版)。
清单 1. SimpleQuartzJob.java
package com.ibm.developerworks.quartz;
import java.util.Date;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
public class SimpleQuartzJob implements Job {
public SimpleQuartzJob() {
}
public void execute(JobExecutionContext context) throws JobExecutionException {
System.out.println("In SimpleQuartzJob - executing its JOB at "
+ new Date() + " by " + context.getTrigger().getName());
}
}
请注意,execute 方法接受一个 JobExecutionContext 对象作为参数。这个对象提供了作业实例的运行时上下文。特别地,它提供了对调度器和触发器的访问,这两者协作来启动作业以及作业的 JobDetail 对象的执行。Quartz 通过把作业的状态放在 JobDetail 对象中并让 JobDetail 构造函数启动一个作业的实例,分离了作业的执行和作业周围的状态。JobDetail 对象储存作业的侦听器、群组、数据映射、描述以及作业的其他属性。
示例 2:简单触发器
触发器可以实现对任务执行的调度。Quartz 提供了几种不同的触发器,复杂程度各不相同。清单 2 中的 SimpleTrigger 展示了触发器的基础:
清单 2. SimpleTriggerRunner.java
public void task() throws SchedulerException
{
// Initiate a Schedule Factory
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
// Retrieve a scheduler from schedule factory
Scheduler scheduler = schedulerFactory.getScheduler();
// current time
long ctime = System.currentTimeMillis();
// Initiate JobDetail with job name, job group, and executable job class
JobDetail jobDetail =
new JobDetail("jobDetail-s1", "jobDetailGroup-s1", SimpleQuartzJob.class);
// Initiate SimpleTrigger with its name and group name
SimpleTrigger simpleTrigger =
new SimpleTrigger("simpleTrigger", "triggerGroup-s1");
// set its start up time
simpleTrigger.setStartTime(new Date(ctime));
// set the interval, how often the job should run (10 seconds here)
simpleTrigger.setRepeatInterval(10000);
// set the number of execution of this job, set to 10 times.
// It will run 10 time and exhaust.
simpleTrigger.setRepeatCount(100);
// set the ending time of this job.
// We set it for 60 seconds from its startup time here
// Even if we set its repeat count to 10,
// this will stop its process after 6 repeats as it gets it endtime by then.
//simpleTrigger.setEndTime(new Date(ctime + 60000L));
// set priority of trigger. If not set, the default is 5
//simpleTrigger.setPriority(10);
// schedule a job with JobDetail and Trigger
scheduler.scheduleJob(jobDetail, simpleTrigger);
// start the scheduler
scheduler.start();
}
清单 2 开始时实例化一个 SchedulerFactory,获得此调度器。就像前面讨论过的,创建 JobDetail 对象时,它的构造函数要接受一个 Job 作为参数。顾名思义,SimpleTrigger 实例相当原始。在创建对象之后,设置几个基本属性以立即调度任务,然后每 10 秒重复一次,直到作业被执行 100 次。
还有其他许多方式可以操纵 SimpleTrigger。除了指定重复次数和重复间隔,还可以指定作业在特定日历时间执行,只需给定执行的最长时间或者优先级(稍后讨论)。执行的最长时间可以覆盖指定的重复次数,从而确保作业的运行不会超过最长时间。
示例 3: Cron 触发器
CronTrigger 支持比 SimpleTrigger 更具体的调度,而且也不是很复杂。基于 cron 表达式,CronTrigger 支持类似日历的重复间隔,而不是单一的时间间隔 —— 这相对 SimpleTrigger 而言是一大改进。
Cron 表达式包括以下 7 个字段:
秒
分
小时
月内日期
月
周内日期
年(可选字段)
特殊字符
Cron 触发器利用一系列特殊字符,如下所示:
反斜线(/)字符表示增量值。例如,在秒字段中“5/15”代表从第 5 秒开始,每 15 秒一次。
问号(?)字符和字母 L 字符只有在月内日期和周内日期字段中可用。问号表示这个字段不包含具体值。所以,如果指定月内日期,可以在周内日期字段中插入“?”,表示周内日期值无关紧要。字母 L 字符是 last 的缩写。放在月内日期字段中,表示安排在当月最后一天执行。在周内日期字段中,如果“L”单独存在,就等于“7”,否则代表当月内周内日期的最后一个实例。所以“0L”表示安排在当月的最后一个星期日执行。
在月内日期字段中的字母(W)字符把执行安排在最靠近指定值的工作日。把“1W”放在月内日期字段中,表示把执行安排在当月的第一个工作日内。
井号(#)字符为给定月份指定具体的工作日实例。把“MON#2”放在周内日期字段中,表示把任务安排在当月的第二个星期一。
星号(*)字符是通配字符,表示该字段可以接受任何可能的值。
所有这些定义看起来可能有些吓人,但是只要几分钟练习之后,cron 表达式就会显得十分简单。
清单 3 显示了 CronTrigger 的一个示例。请注意 SchedulerFactory、Scheduler 和 JobDetail 的实例化,与 SimpleTrigger 示例中的实例化是相同的。在这个示例中,只是修改了触发器。这里指定的 cron 表达式(“0/5 * * * * ?”)安排任务每 5 秒执行一次。
清单 3. CronTriggerRunner.java
public void task() throws SchedulerException
{
// Initiate a Schedule Factory
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
// Retrieve a scheduler from schedule factory
Scheduler scheduler = schedulerFactory.getScheduler();
// current time
long ctime = System.currentTimeMillis();
// Initiate JobDetail with job name, job group, and executable job class
JobDetail jobDetail =
new JobDetail("jobDetail2", "jobDetailGroup2", SimpleQuartzJob.class);
// Initiate CronTrigger with its name and group name
CronTrigger cronTrigger = new CronTrigger("cronTrigger", "triggerGroup2");
try {
// setup CronExpression
CronExpression cexp = new CronExpression("0/5 * * * * ?");
// Assign the CronExpression to CronTrigger
cronTrigger.setCronExpression(cexp);
} catch (Exception e) {
e.printStackTrace();
}
// schedule a job with JobDetail and Trigger
scheduler.scheduleJob(jobDetail, cronTrigger);
// start the scheduler
scheduler.start();
}
高级 Quartz
如上所示,只用作业和触发器,就能访问大量的功能。但是,Quartz 是个丰富而灵活的调度包,对于愿意研究它的人来说,它还提供了更多功能。下一节讨论 Quartz 的一些高级特性。
作业仓库
Quartz 提供了两种不同的方式用来把与作业和触发器有关的数据保存在内存或数据库中。第一种方式是 RAMJobStore 类的实例,这是默认设置。这个作业仓库最易使用,而且提供了最佳性能,因为所有数据都保存在内存中。这个方法的主要不足是缺乏数据的持久性。因为数据保存在 RAM 中,所以应用程序或系统崩溃时,所有信息都会丢失。
为了修正这个问题,Quartz 提供了 JDBCJobStore。顾名思义,作业仓库通过 JDBC 把所有数据放在数据库中。数据持久性的代价就是性能降低和复杂性的提高。
设置 JDBCJobStore
在前面的示例中,已经看到了 RAMJobStore 实例的工作情况。因为它是默认的作业仓库,所以显然不需要额外设置就能使用它。但是,使用 JDBCJobStore 需要一些初始化。
在应用程序中设置使用 JDBCJobStore 需要两步:首先必须创建作业仓库使用的数据库表。 JDBCJobStore 与所有主流数据库都兼容,而且 Quartz 提供了一系列创建表的 SQL 脚本,能够简化设置过程。可以在 Quartz 发行包的 “docs/dbTables”目录中找到创建表的 SQL 脚本。第二,必须定义一些属性,如表 1 所示:
表 1. JDBCJobStore 属性
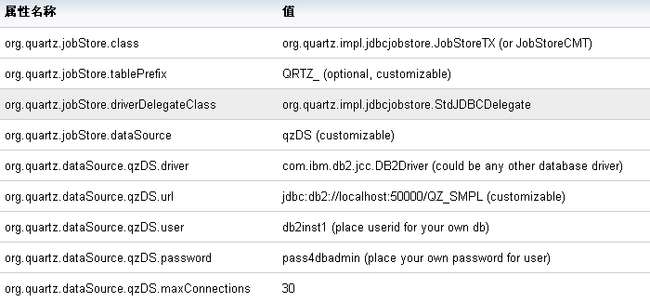
清单 4 展示了 JDBCJobStore 提供的数据持久性。就像在前面的示例中一样,先从初始化 SchedulerFactory 和 Scheduler 开始。然后,不再需要初始化作业和触发器,而是要获取触发器群组名称列表,之后对于每个群组名称,获取触发器名称列表。请注意,每个现有的作业都应当用 Scheduler.reschedule() 方法重新调度。仅仅重新初始化在先前的应用程序运行时终止的作业,不会正确地装载触发器的属性。
清单 4. JDBCJobStoreRunner.java
public void task() throws SchedulerException
{
// Initiate a Schedule Factory
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
// Retrieve a scheduler from schedule factory
Scheduler scheduler = schedulerFactory.getScheduler();
String[] triggerGroups;
String[] triggers;
triggerGroups = scheduler.getTriggerGroupNames();
for (int i = 0; i < triggerGroups.length; i++) {
triggers = scheduler.getTriggerNames(triggerGroups[i]);
for (int j = 0; j < triggers.length; j++) {
Trigger tg = scheduler.getTrigger(triggers[j], triggerGroups[i]);
if (tg instanceof SimpleTrigger && tg.getName().equals("simpleTrigger")) {
((SimpleTrigger)tg).setRepeatCount(100);
// reschedule the job
scheduler.rescheduleJob(triggers[j], triggerGroups[i], tg);
// unschedule the job
//scheduler.unscheduleJob(triggersInGroup[j], triggerGroups[i]);
}
}
}
// start the scheduler
scheduler.start();
}
运行 JDBCJobStore
在第一次运行示例时,触发器在数据库中初始化。图 1 显示了数据库在触发器初始化之后但尚未击发之前的情况。所以,基于 清单 4 中的 setRepeatCount() 方法,将 REPEAT_COUNT 设为 100,而 TIMES_TRIGGERED 是 0。在应用程序运行一段时间之后,应用程序停止。
图 1. 使用 JDBCJobStore 时数据库中的数据(运行前)

图 2 显示了数据库在应用程序停止后的情况。在这个图中,TIMES_TRIGGERED 被设为 19,表示作业运行的次数。
图 2. 同一数据在 19 次迭代之后

当再次启动应用程序时,REPEAT_COUNT 被更新。这在图 3 中很明显。在图 3 中可以看到 REPEAT_COUNT 被更新为 81,所以新的 REPEAT_COUNT 等于前面的 REPEAT_COUNT 值减去前面的 TIMES_TRIGGERED 值。而且,在图 3 中还看到新的 TIMES_TRIGGERED 值是 7,表示作业从应用程序重新启动以来,又触发了 7 次。
图 3. 第 2 次运行 7 次迭代之后的数据

当再次停止应用程序之后,REPEAT_COUNT 值再次更新。如图 4 所示,应用程序已经停止,还没有重新启动。同样,REPEAT_COUNT 值更新成前一个 REPEAT_COUNT 值减去前一个 TIMES_TRIGGERED 值。
图 4. 再次运行触发器之前的初始数据

使用属性
正如在使用 JDBCJobStore 时看到的,可以用许多属性来调整 Quartz 的行为。应当在 quartz.properties 文件中指定这些属性。请参阅 参考资料 获得可以配置的属性的列表。清单 5 显示了用于 JDBCJobStore 示例的属性:
清单 5. quartz.properties
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool org.quartz.threadPool.threadCount = 10 org.quartz.threadPool.threadPriority = 5 org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true # Using RAMJobStore ## if using RAMJobStore, please be sure that you comment out the following ## - org.quartz.jobStore.tablePrefix, ## - org.quartz.jobStore.driverDelegateClass, ## - org.quartz.jobStore.dataSource #org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore # Using JobStoreTX ## Be sure to run the appropriate script(under docs/dbTables) first to create tables org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX # Configuring JDBCJobStore with the Table Prefix org.quartz.jobStore.tablePrefix = QRTZ_ # Using DriverDelegate org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate # Using datasource org.quartz.jobStore.dataSource = qzDS # Define the datasource to use org.quartz.dataSource.qzDS.driver = com.ibm.db2.jcc.DB2Driver org.quartz.dataSource.qzDS.URL = jdbc:db2://localhost:50000/dbname org.quartz.dataSource.qzDS.user = dbuserid org.quartz.dataSource.qzDS.password = password org.quartz.dataSource.qzDS.maxConnections = 30
结束语
Quartz 作业调度框架所提供的 API 在两方面都表现极佳:既全面强大,又易于使用。Quartz 可以用于简单的作业触发,也可以用于复杂的 JDBC 持久的作业存储和执行。OpenSymphony 在开放源码世界中成功地填补了一个空白,过去繁琐的作业调度现在对开发人员来说不过是小菜一碟。