1 概念和地位:
是Hadoop领域的数据库,(类比于 hive在Hadoop领域文件系统的更高层抽象使用和封装)
高可靠性、高性能、面向列、可伸缩的分布式存储系统,(可伸缩:非常容易增加节点让计算和存储能力得到提升 面向列是hbase的一大特点)
利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群
HBase利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,因此hbase是建立在hadoop基础上的。
利用Zookeeper作为协调工具。
2 行式存储和列式存储区别:
行式存储:
代表: mysql oracle sqlserver等老牌关系型数据库
几个特点:
a)
关系型数据库在产生的时候就在单机上做的,因此有时代局限性,
以前会分库,当这个单机数据库容量不够时,需要在另一台单机中存储,
这时候需要让客户端代码明确知道哪些数据在哪个机器上,
虽然现在也有mysql oracle主从搭建,但是操作不方便,部署麻烦
关系数据库是按行存储数据(物理存储方式),一行紧挨着一行,当一个表数据在几百万下没问题,
如果表很大(记录条数多 或者 列比较多) 比如电信上的宽表,一个表通常在100+个字段上,
这种表字段多好处在于避免多表连接查询
b)
关系型数据库在建表时,一下就把表字段 类型 类型占用长度指明,这样就把一行的空间给确定下来,
这样在查询的时候,
会根据长度(c语言指针)来去找对应位置下存储的数据,即使只获取100个字段的5个字段,也会将100个字段读取到后加载到内存然后将需要的5个字段获取到还给用户,这样耗内存和IO
c)
同时,在关系型数据库表中插入字段时,并不是所有字段都有值,好多都为null,
这些null在磁盘占用空间会预留出来以备后续插入数值,这样磁盘利用率降低
d) 非常适用于小规模数据, 几百几千M的
列式存储:
0) 产生背景: 互联网大潮下,计算的复杂度(比如递归 天气预报计算)是无限的,产生的数据是无限多的,但是单机的计算能力和资源是有限的,因此大数据下hbase因用而生。
a) 特点: 表的字段按照业务查询频率分别分开,存在不同列(文件中)
一个表的不同字段 可能会被分到不同的列中, 不同的列被存储在不同文件中(本质还是存在文件中),
如果仅查询某些字段正好在这个文件中,那么打开此文件即可。
如果列值为Null 那么不会占用磁盘空间、
b) 哪些列应该放在一起?
综合业务中哪些常用到,就把这些常用到的拿出来放在一起,
不同列存在在不同文件下如何对应呢? hbase会在存储时做对应关系记录
c) 适合于: 数据过 XXG的规模 ,大宽表, 如果小规模下处理速度是低于关系型数据库的
d) 项目中,传统数据库到列式数据库的切换:
往往项目中仅仅是一个或者某个表变得很大,运行起来很慢,此时仅需要将这几张表移植到hbase中,
切换后对应的代码需要大改。
关于hbase结构介绍和与zk结合下操作细节 待续 目前没搞明白 ............................................
4 hbase列族简介图:

5 hbase 逻辑结构 物理结构 存储结构
5.1) 逻辑模型
表
行
列簇,是列的集合。
列,是不能脱离列簇而独立存在的。
行键,类似于主键。
时间戳,数据插入到HBase表的时间;是天然存在的。
5.2) 物理模型
HBase数据在进行存储时,是按照行键存储的。
列簇,是单独存储一系列列的文件
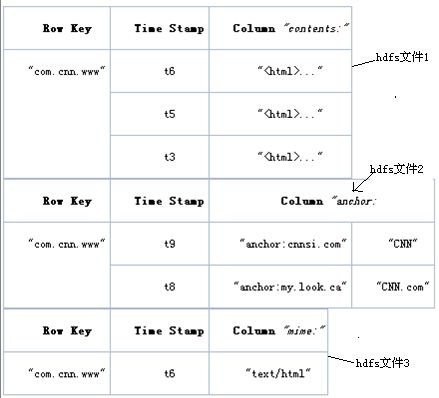
5.3) 存储模型
HBase表是纵向划分为很多的列簇,每个列簇都对应一个hdfs文件。
HBase表是横向划分为很多region的,region是存放在不同的region server的。
当列簇对应的hdfs文件过大时,打开时会很慢,影响并发量。
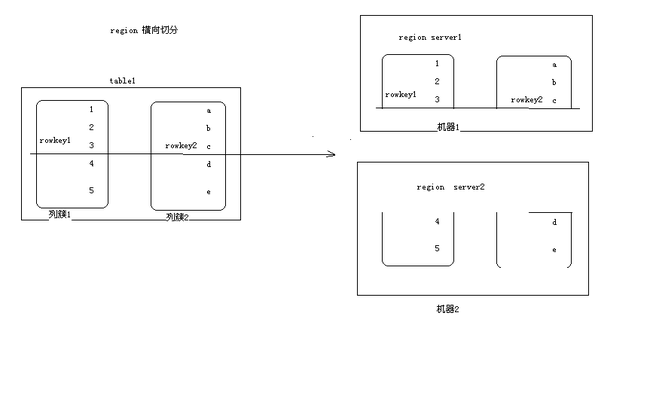
将表中所有数据(即将hdfs文件拆分成多份)横向切分为多个region,后将每个region存放在不同的region server上,
比如前10000的数据放在server1 第10001-2000的放在server2 根据负载均衡 用户请求的在哪个范围内则调整到对应机器上执行
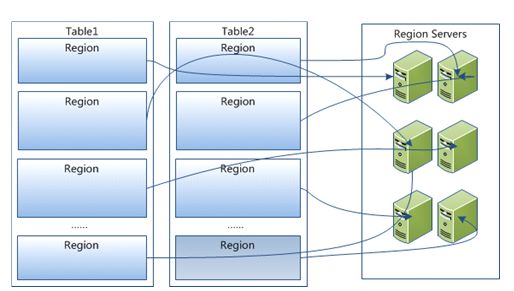
5.4) 体系结构
主从式结构,主节点称作master,从节点称作region server。
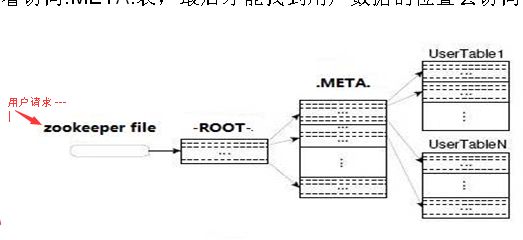
master接收到用户查询请求后 通过映射 转换,最后定位查询到region server
master映射机制:依靠如下表
-ROOT-和.META.是系统内部表。
集群安装如下:
5.搭建hbase集群(master作为主节点,sliver103和sliver104作为从节点)
5.1 在master上解压缩
[root@master local]# tar -zxvf hbase-0.94.7-security.tar.gz
重命名为hbase:
[root@master local]# mv hbase-0.94.7-security hbase
5.2 编辑文件conf/hbase-env.sh 修改内容
export JAVA_HOME=/usr/local/jdk
export HBASE_MANAGES_ZK=false
5.3 编辑文件conf/hbase-site.xml 修改内容
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,sliver103,sliver104</value>
</property>
5.4 编辑文件conf/regionservers 修改内容
sliver103
sliver104
5.5 复制hbase到sliver103、sliver104节点
[root@master local]# scp -r hbase sliver103:/usr/local/
[root@master local]# scp -r hbase sliver104:/usr/local/
5.6 启动hbase之前,要检查hadoop的hdfs、zookeeper集群是否正常运行
在hadoop0上执行bin/start-hbase.sh如下:
[root@master bin]# start-hbase.sh
starting master, logging to /usr/local/hbase/bin/../logs/hbase-root-master-master.out
sliver103: starting regionserver, logging to /usr/local/hbase/bin/../logs/hbase-root-regionserver-sliver103.out
sliver104: starting regionserver, logging to /usr/local/hbase/bin/../logs/hbase-root-regionserver-sliver104.out
[root@master bin]# jps
9800 JobTracker
13967 QuorumPeerMain
9572 NameNode
25416 Jps
25238 HMaster
9721 SecondaryNameNode
sliver103:
[root@sliver103 local]# jps
13136 Jps
17065 DataNode
17174 TaskTracker
16343 QuorumPeerMain
12830 HRegionServer
sliver104:
[root@sliver104 network-scripts]# jps
21667 HRegionServer
28596 QuorumPeerMain
20799 TaskTracker
21898 Jps
5.7 检查,执行jps命令,在hadoop0上看到1个新的java进程,分别是HMaster
查看http://master:60010
如下截图:
