数据类型
varchar2 用于描述变长的字符型数据,长度<=4000字节
nchar 用来存储Unicode字符集的定长字符型数据,长度<=1000字节
nvarchar2 用来存储Unicode字符集的变长字符型数据,长度<=1000字节
number 用来存储整型或者浮点型数值
Date 用来存储日期数据
Long 用来存储最大长度为2GB的变长字符数据
Raw 用来存储非结构化数据的变长字符数据,长度<=2000字节
Long raw 用来存储非结构化数据的变长字符数据,长度<=2GB
rowid 用来存储表中列的物理地址的二进制数据,占用固定的10个字节
Blob 用来存储多达4GB的非结构化的二进制数据
Clob 用来存储多达4GB的字符数据
nclob 用来存储多达4GB的Unicode字符数据
Bfile 用来把非结构化的二进制数据存储在数据库以外的操作系统文件中
urowid 用来存储表示任何类型列地址的二进制数据
float 用来存储浮点数
1:登入
2:解锁
select p.spid,c.object_name,b.session_id,b.oracle_username,b.os_user_name from v$process p,v$session a, v$locked_object b,all_objects c where p.addr=a.paddr and a.process=b.process and c.object_id=b.object_id
解锁:
alter system kill session '146';(其中146为锁住的进程号)
3:创建同义词(别名)
4:创建自增字段
minvalue 1
maxvalue 999999999999999999999999999
start with 1
increment by 1
nocache;
查看自增
select * from user_sequences
查询所有的
select * from all_sequences
5:捕捉运行很久的sql (转,没有验证)
round(sofar*100/totalwork,0)||'%'as progress,
time_remaining,sql_text
from v$session_longops,v$sql
where time_remaining <>0
and sql_address=address
and sql_hash_value=hash_value;
6:查看表空间
from dba_free_space
group by tablespace_name;
select a.tablespace_name,a.bytes total,b.bytes used, c.bytes free,
(b.bytes*100)/a.bytes "% used",(c.bytes*100)/a.bytes "% free"
from sys.sm$ts_avail a,sys.sm$ts_used b,sys.sm$ts_free c
where a.tablespace_name=b.tablespace_name and a.tablespace_name=c.tablespace_name;
7:查看还没提交的事务
select * from v$transaction;
8:查看连接数
select username,count(username) from v$session where username is not null group by username #查看不同用户的连接数
select count(*) from v$session #连接数
Select count(*) from v$session where status='ACTIVE' #并发连接数
show parameter processes #最大连接
alter system set sessions=300 scope=spfile;
alter system set processes = value scope = spfile;重启数据库 #修改连接
/home/oracle9i/app/oracle9i/dbs/init.ora
/home/oracle9i/app/oracle9i/dbs/spfilexxx.ora ## open_cursor
查看连接占用内存
select min(pga_used_mem)/1024/1024 M from v$process where pga_used_mem>0;
9:使用正则查询
10:去重
11:使用结果集更新数据
表结构一致,其中的day做了加数运算,插入到12月06到08
便新字段
12:查看表结构
查看主键
from user_cons_columns a, user_constraints b
where a.constraint_name = b.constraint_name
and b.constraint_type = 'P'
and a.table_name = 'BANDWIDTH_AREA'
13 数据的导入导出
exp \'sys/口令 as sysdba\' file=a.dmp owner=导出用户 rows=N
imp \'sys/口令 as sysdba\' file=a.dmp fromuser=导出用户 touser=导入用户
windows下:
exp 'sys/口令 as sysdba' file=a.dmp owner=导出用户 rows=N
imp 'sys/口令 as sysdba' file=a.dmp fromuser=导出用户 touser=导入用户
rows=y表示数据和结构都导出
rows=n只导出结构,不导数据
解决乱码
t.parameter='NLS_CHARACTERSET'
或
select * from v$nls_parameters where
parameter='NLS_CHARACTERSET';
LINUX> export NLS_LANG=AMERICAN_AMERICA.AL32UTF8
14:查看表
select table_name from all_tables; //所有用户的表
select table_name from dba_tables; //包括系统表
select table_name from dba_tables where owner='用户名'
15:按时间分组,显示每个时间点的记录个数
16:视图(从表中抽出的逻辑相关的数据集合,只能用于查询,不能提高性能)
使用:select * from area_231203
修改:create or replace view area_231203 as select * from bandwidth_area where day=to_date('2013-12-03','yyyy-mm-dd')
删除:drop view area_231203
17:根据查询值返回不同结果(blood_test_flag字段为Y时返回yes;为N时返回no;为null时返回None;否则返回默认值Invalid)
DECODE(blood_test_flag,’Y’,’Yes’,’N’,’No’,NULL,’None’,’Invalid’)
FROM checkup;
18:oracle的启动与关闭
lsnrctl start --“打开监听”
sqlplus /nolog --“进入到sqlplus”
conn /as sysdba --“连接到sysdba”
startup --“启动数据库实例”
shutdown immediate --“关闭数据库实例”
lsnrctl stop --“关闭监听”
19:定时删除数据
create or replace procedure DeleteDataForJob_alarm_records is begin delete from alarm_records where alarm_time <sysdate - 20; end DeleteDataForJob_alarm_records;
begin dbms_job.submit(:jobno,'DeleteDataForJob_alarm_records;',sysdate,'SYSDATE');
commit;
end;
20:插入查询的结果集(字段要与select中的结束对应)
21:查找重复的记录(重复记录是按peopleld判断的)去重
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
22:删除重复记录(重复记录是按peopleld判断的,只留有rowid最小的记录)
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
23:多个字段重复记录(http://www.cnblogs.com/nvli/articles/2171194.html)
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
用一条sql语句查询出“每门”课程都大于80分的学生姓名
先查出低于80分的学生名单,然后再用姓名作为条件对比,排除刚才查到的学生
select [Name] from [表] where [fengshu]<=80
)
24:消除错误数据的存储过程
create or replace procedure bandwidth_all_erroredit
is
v_bandall_old bandwidth_all%rowtype; --上一条正确记录
v_bandall_this bandwidth_all%rowtype; --当前记录
CURSOR c1 IS SELECT * FROM bandwidth_all where day >=trunc(sysdate)-1 and day < sysdate FOR UPDATE; --得到两天的数据
BEGIN
select * into v_bandall_old from bandwidth_all where day =trunc(sysdate)-1-1/24/12;--old记录为上一天的最后一条
OPEN c1;
LOOP
FETCH c1 INTO v_bandall_this;
EXIT WHEN c1%NOTFOUND;
IF v_bandall_this.data > 0
THEN
IF (v_bandall_this.data-v_bandall_old.data)/v_bandall_old.data >=1 or (v_bandall_this.data-v_bandall_old.data)/v_bandall_old.data<=-0.5--两点之间的数据在高于1倍或底于1倍算不正常
THEN
--DBMS_output.put_line(to_char(v_bandall_this.day,'yyyymmdd hh24:mi:ss')||' '||(v_bandall_this.data-v_bandall_old.data)/v_bandall_old.data);
UPDATE bandwidth_all SET data = v_bandall_old.data
WHERE CURRENT OF c1;
else
v_bandall_old.data:=v_bandall_this.data; --只有不存在错误时才更新正确记录值
END IF;
IF (v_bandall_this.indata-v_bandall_old.indata)/v_bandall_old.indata >= 1 or (v_bandall_this.indata-v_bandall_old.indata)/v_bandall_old.indata<=-0.5
THEN
UPDATE bandwidth_all SET indata = v_bandall_old.indata
WHERE CURRENT OF c1;
else
v_bandall_old.indata:=v_bandall_this.indata;
END IF;
END IF;
END LOOP;
--rollback;
COMMIT; --提交已经修改的数据
CLOSE c1;
END;
表结构
create table BANDWIDTH_ALL ( DAY DATE not null, DATA NUMBER(18) default 0 not null, INDATA NUMBER(18) default 0 not null )
24:分页查询
25:分表分库
垂直划分
按照功能划分,把数据分别放到不同的数据库和服务器。
当一个网站开始刚刚创建时,可能只是考虑一天只有几十或者几百个人访问,数据库可能就个db,所有表都放一起,一台普通的服务器可能就够了,而且开发人员也非常高兴,而且信心十足,因为所有的表都在一个库中,这样查询语句就可以随便关联了,多美的一件事情。但是随着访问压力的增加,读写操作不断增加,数据库的压力绝对越来越大,可能接近极限,这时可能人们想到增加从服务器,做什么集群之类的,可是问题又来了,数据量也快速增长。
这时可以考虑对读写操作进行分离,按照业务把不同的数据放到不同的库中。其实在一个大型而且臃肿的数据库中表和表之间的数据很多是没有关系的,或者更加不需要(join)操作,理论上就应该把他们分别放到不同的服务器。例如用户的收藏夹的数据和博客的数据库就可以放到两个独立的服务器。这个就叫垂直划分(其实叫什么不重要)。
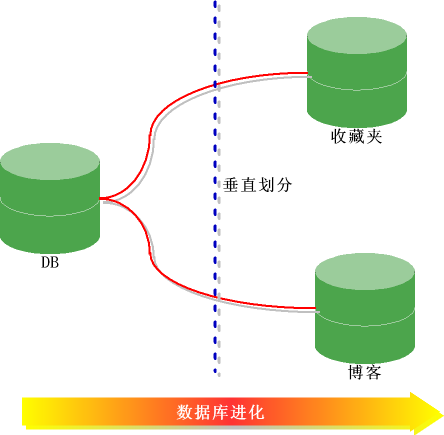
当博客或者收藏夹的数据不断增加后,应该怎么办,这样就引出了另外一个做法,叫水平划分。
水平划分
则把一个表的数据划分到不同的数据库,两个数据库的表结构一样。怎么划分,应该根据一定的规则,可以根据数据的产生者来做引导,上面的数据是由人产生的,可以根据人的id来划分数据库。然后再根据一定的规则,先获知数据在哪个数据库。
其实很多大型网站都经历了数据库垂直划分和水平的划分的阶段。其实这个可以根据经验来确定,不一定由某些硬性的规则。
以刚才的博客为例,数据可以根据userid的奇偶来确定数据的划分。把id为基数的放到A库,为偶数的放B库。
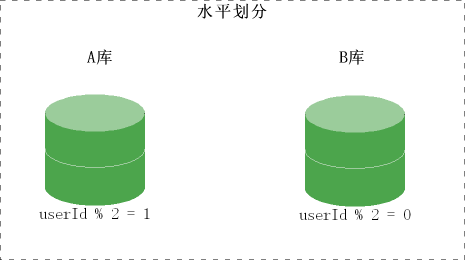
这样通过userId就可以知道用户的博客的数据在哪个数据库。其实可以根据userId%10来处理。还可以根据著名的HASH算法来处理。