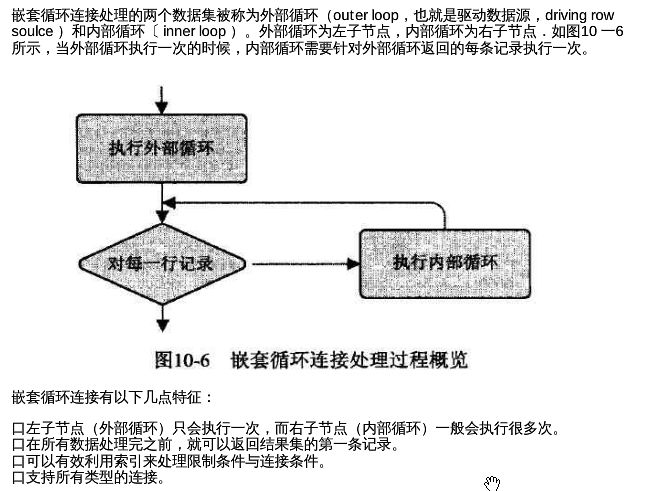
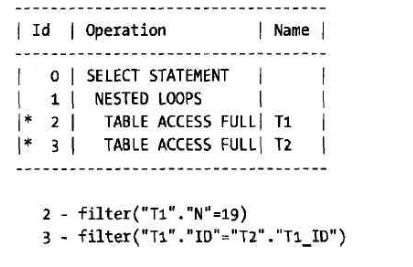
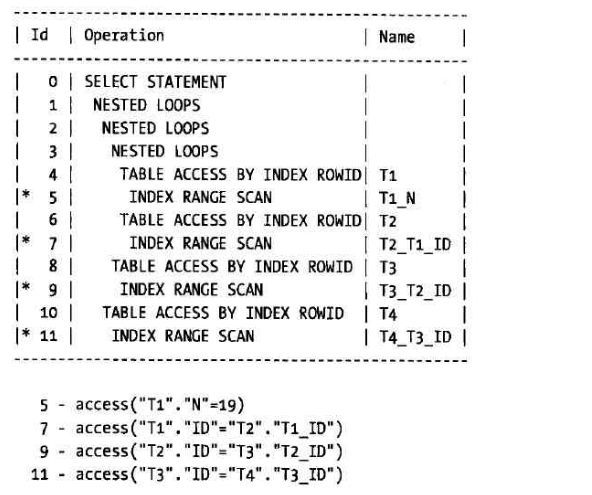
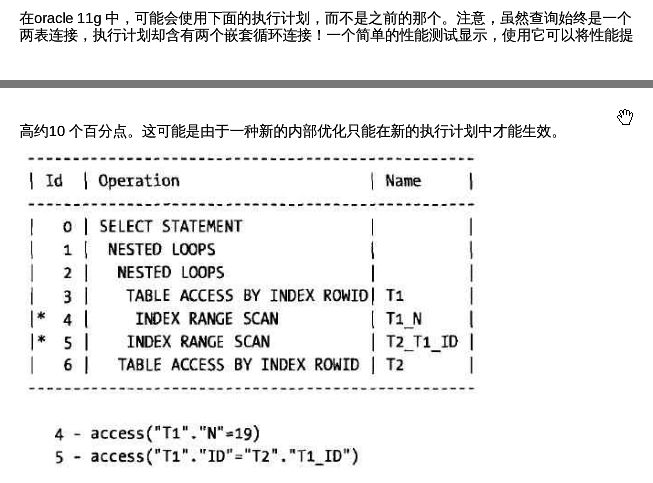
- YashanDB异构数据库链接配置
数据库
异构数据库链接配置异构数据库链接指从YashanDB创建到其他非YashanDB的远程链接(DBLINK)。对于从YashanDB到Oracle数据库的链接,系统存在如下前置要求:YashanDB服务端已安装plugin插件包。要求在安装YashanDB服务端时,指定plugin插件包。YashanDB服务端安装完成后,无法单独安装该插件包。YashanDB服务端已下载和安装OracleInsta
- Linux---sqlite3数据库
磨十三
数据库linuxsqlite
一、数据库分类1.按数据关系分类类型特点代表产品关系型数据库-使用SQL(结构化查询语言)-数据以行列形式存储,支持事务和复杂查询MySQL、Oracle、SQLite非关系型数据库-无固定表结构(如键值对、文档、图)-高扩展性,适合非结构化数据MongoDB、Redis2.按功能规模分类类型特点代表产品大型数据库高并发、高可用性,支持企业级应用Oracle、DB2中型数据库适用于中小型企业,跨平
- mysql、oracle、SQLserver之间的区别和优势
噔噔噔噔@
mysqloraclesqlserver
MySQL、Oracle和SQLServer都是常见的关系型数据库管理系统(RDBMS),它们在某些方面有一些区别和优势。MySQL:MySQL是一种开源的RDBMS,由Oracle公司开发和维护。它具有快速、稳定和易于使用的特点。MySQL适用于中小型应用和网站,它在处理大量简单的查询时表现较好。MySQL对于开发者来说是免费的,但也有商业版提供更多高级功能。Oracle:Oracle是一种商业
- 基于oracle linux的 DBI/DBD 标准化安装文档
linux
一、安装DBIDBI(DatabaseInterface)是perl连接数据库的接口。其是perl连接数据库的最优方法,他支持包括Orcale,Sybase,mysql,db2等绝大多数的数据库,下面将简要介绍其安装方法。1.1解压tar-zxvfDBI-1.616_901.tar.gz1.2安装依赖yuminstallperl-ExtUtils-CBuilderperl-ExtUtils-Mak
- Oracle数据库面试题-11
编织幻境的妖
oracle数据库
21.解释序列(Sequence)在Oracle中的作用。序列(Sequence)在Oracle数据库中是一种用来生成连续数字序列的数据库对象。它经常被用来生成主键值,因为数据库表中的每一行都需要一个唯一的键值,而序列可以保证这一点。序列的作用:1.生成唯一的数字序列序列可以保证每次调用时返回一个唯一的数字,这在需要生成唯一键值的场景下非常有用,如主键。2.实现自动递增序列可以配置为自动递增,这意
- oracle pl/sql desc+表名 无效sql的问题
dept123
Oracle
在pl/sql的sqlwindow里面写descschema.表名-->无效sql语句要换成commandwindow然后descshema.表名;
- oracle ar 税率,EBS(Oracle ERP) AR AP TAX 税信息 区别 转
袁大岛
oraclear税率
从前台税信息展示及后台税信息存储方面对比下APAR中税信息区别:1、前台界面:AP发票行中有税行的显示;而AR发票行中没有税行的显示,但其实AR发票行表是有存储税行的。2、AP发票行表中存储的税信息是非税行(后面简称item行)产生的且按税率汇总后的税信息,而不是非税行(后面简称item行)产生的税明细信息,明细信息需要从税模块中提取;而AR发票行表中存储的税信息就是非税行(后面简称line行)产
- MySQL 数据库简介
机智的三三
MySQL数据库mysql
文章目录MySQL数据库简介一、MySQL的历史1.MySQL发展历史详情2.MySQL的发布历史MySQL数据库简介MySQL是由瑞典公司MySQLAB开发、现隶属于Oracle的开源关系型数据库管理系统(RDBMS),支持多用户、多线程访问及事务处理(ACID特性),其核心存储引擎InnoDB提供行级锁、崩溃恢复等能力,适用于高并发OLTP场景。MySQL基于GNUGPL协议开源,兼具高性能与
- Mysql在oracle的安装与配置(怕忘)
薛定谔的码*
mysqloracle数据库
1、获取iso安装oracle:https://mirrors.tuna.tsinghua.edu.cn/openeuler/openEuler-24.03-LTS/ISO/x86_64/openEuler-24.03-LTS-x86_64-dvd.isoopenEuler-22.03-LTS-x86_64-dvd.iso2、安装os手动设置固定IP,建议大家网卡vmnet8网关:x.x.x.2D
- Oracle/MySQL/PostgreSQL 到信创数据库数据同步简介
笑远
数据库数据同步详解数据库pythonetl
Oracle/MySQL/PostgreSQL数据库同步到信创数据库的处理方案、注意事项及工具介绍在当前信息化快速发展的背景下,企业面临着多样化的数据库管理需求。尤其是将现有的Oracle、MySQL、PostgreSQL等主流数据库数据迁移或同步到国产信创(国产自主创新)数据库系统,如华为的GaussDB、达梦(Dameng)、人大金仓(Kingbase)等,成为了许多企业的实际需求。本文将详细
- MySQL 8.4 版本(LTS) 发布,一睹为快
m0_74823683
面试学习路线阿里巴巴mysqladbandroid
前言Oracle前几天发布了MySQL8.4版本(LTS),该版本是创新版的第一个长期支持版本。详细规划,请移步技术译文|一文了解MySQL全新版本模型关于MySQL的版本发布规划OracleMySQL官方开发团队推出的新版本将过渡到新的MySQL版本模型。MySQL8.1.0是第一个创新版本,8.0.34+将只进行错误修复,直到8.0生命周期结束(EOL,定于2026年4月)。MySQL8.x版
- Oracle数据库深度优化实战指南:从SQL到架构的全维度调优
AAEllisonPang
jvm
目录性能优化方法论1.1性能优化黄金三角(SQL/实例/架构)1.2常用诊断工具全景图(AWR/ASH/SQLMonitor)SQL语句调优实战2.1执行计划深度解析2.2全表扫描灾难案例2.3绑定变量陷阱解决方案索引优化策略3.1索引失效七大场景3.2函数索引实战应用实例参数优化4.1内存管理核心参数4.2连接风暴抑制方案架构设计优化5.1分区表设计陷阱5.2物化视图加速案例统计信息管理6.1统
- 使用MySQL Yum 源在Linux上安装MySQL
Run Out Of Brain
mysqllinux数据库
OracleLinux、RedHatEnterpriseLinux、CentOS和Fedora的MySQLYum源提供了RPM安装包,用于安装MySQL服务器、客户端、MySQLWorkbench、MySQL实用程序、MySQL路由器、MySQLShell、连接器/ODBC、连接器/Python等在你开始之前作为一种流行的开源软件,MySQL以其原始或重新打包的形式被广泛安装在来自各种来源的许多系
- 目前使用ORACLE EBS的公司列表
又是两个大汉堡
(相关文章:目前使用SAP的公司列表)1摩托罗拉2LG电子3济南钢铁4长安福特5百度6伊利7亚信8佳通9移动10电信11湘钢12韶钢13三角轮胎14广州铁道车辆厂15美的集团16青岛啤酒17珠江啤酒18德赛集团19大唐电力20云南白药21白沙集团22万家乐集团23华为24松下电工25华润涂料26广西柳工机械股份有限公司27天津中新药业集团28浦东机场29涟源钢铁集团30衡阳钢管厂31顺达电脑,32
- Oracle创建表空间、删除、状态、重命名、修改、增加、移动
水煮白菜王
Oracleoracle数据库
目录Oracle基本学习笔记创建表空间1.表空间创建格式3.表空间状态属性4.重命名表空间5.修改表空间数据文件的大小6.删除表空间的数据文件7.修改表空间中数据文件的状态8.表空间中数据文件的移动Oracle基本学习笔记创建表空间需要使用CREATETABLESPACE语句。其基本语法如下:CREATE[TEMPORARYIUNDO]TABLESPACEtablespacename[DATAFI
- 这给我干哪来了,MySQL都9.2了
赵师的工作日
mysql数据库
作者:赵师的工作日(赵明中)现役OracleACE、MySQL8.0ocp、TiDBPCTA\PCTP、ElasticsearchCertifiedEngineer微信号:mzzhao23微信公众号:赵师的工作日墨天轮社区:赵师的工作日CSND:赵师的工作日MySQL9.2都来了确实有时间没上MySQL官网(www.mysql.com),MySQL都出9.2版本了。现在业内大头都是8.x版本,少部
- MySQL-关于如何保存“大数据”
赵师的工作日
mysql大数据数据库
作者:赵师的工作日(赵明中)现役OracleACE、MySQL8.0ocp、TiDBPCTA\PCTP、ElasticsearchCertifiedEngineer微信号:mzzhao23微信公众号:赵师的工作日墨天轮社区:赵师的工作日CSND:赵师的工作日数据库的种类有很多,各类数据库充分发挥各自的优势从而保证业务稳定运行,mysql轻量级、关键数据,redis缓存、快,ES搜索,Mongodb
- 如何监控和诊断JVM堆内和堆外内存使用?
嗯哼唉、
Java
专栏的上一篇文章介绍了JVM内存区域的划分,总结了相关的一些概念,今天的专栏将结合JVM参数、工具等方面,进一步分析JVM内存结构,包括外部资料相对较少的堆外部分。今天我想要大家的问题是:如何监控和诊断JVM堆内和堆外内存使用?概述了解JVM内存方法有很多,具体能力范围也有区别,简单总结如下:可以使用综合性的图形化工具,如JConsole、VisualVM(注意,从OracleJDK9开始,Vis
- oracle date类型如何比较
&loopy&
oracle数据库
在Oracle数据库中,DATE类型用于存储日期和时间信息,精确到秒。当你需要比较两个DATE类型的值时,可以使用标准的SQL比较运算符,如=、和>=。以下是一些示例,说明如何在Oracle中比较DATE类型的值:1.等于(=)检查两个日期是否相等:sql复制代码SELECT*FROMyour_tableWHEREyour_date_column=TO_DATE('2023-10-23','YYY
- java 连接oracle 字符集_Java连接Oracle数据库,编码格式转换
东京客
java连接oracle字符集
学习东西不忘记下笔记:dbhelper类,各种数据库都合适。publicclassDBHelper{//mysql数据库//publicstaticfinalStringurl="jdbc:mysql://127.0.0.1:3306/test";//publicstaticfinalStringname="com.mysql.jdbc.Driver";//publicstaticfinalStr
- oracle字符时间比较,Oracle字符和时间比较
七娃爸爸
oracle字符时间比较
数据库中的字段2017-07-1113:37:51类型是char或者varchar要进件与'20170625'比较,格式不一致,需要将他转换成:yyyyMMdd字符串1、先to_dateto_date(create_date,'yyyy-mm-dd,hh24:mi:ss')格式一定要与create_date一致2、转字符串to_char(sysdate,'yyyymmdd')例:下面将create
- oracle字符类型
牛尚小又何妨
Oraclestudyoracle字符类型不同字符类型的比较
1、字符类型的种类有三种:varchar、varchar2、nvarchar2,并没有nvarchar这种类型2、不同类型的字符进行比较是否有风险测试--测试createtabletest002(fstring001varchar(200),fstring002varchar2(200),fstring004nvarchar2(200));--插入数据insertintotest002(fstri
- 数据处理领域有OLTP和OLAP两大类型
驭风少年56
每日知识分享学习
OLTP全称OnlineTransactionProcessing联机事务处理系统存储的是业务数据,记录某类业务事件的发生,suchas:下单,注册,支付等等。典型代表有Mysql,Oracle等数据库,对应的网站,系统应用后端数据库应用比较简单,数据量相对较少,是GB级别的,面向业务开发人员。OLAP全称是OnlineAnalyticalProcessing联机分析处理系统存储多业务历史数据,支
- Windows下安装kafka
计算机软件程序设计
环境搭建windowskafka分布式
在Windows系统下安装Kafka可以按照以下步骤进行:1.安装Java环境Kafka是基于Java开发的,因此需要先安装Java环境。下载Java:访问OracleJava下载页面或OpenJDK下载页面,选择适合你系统的Java版本(建议Java8及以上)进行下载。安装Java:运行下载的安装程序,按照提示完成安装。配置环境变量:右键点击“此电脑”,选择“属性”。点击“高级系统设置”,在弹出
- Ubuntu 12.04(32位)安装Oracle 11g(32位)全过程以及几乎所有问题的解决办法
cs294639693
linux
这两天在Ubuntu上安装Oracle把人折腾毁了,即使照着网上的教程来,还是出了很多问题。好在最后终于搞定了。写出来总结一下,免得以后忘了。标题注明32位是因为网上教程几乎全是以64位安装为例的,32位系统下照着做是绝对会安装失败的。出现的问题主要有两方面,一个是安装过程中出现的,另一个是安装完成后出现的。安装过程(主要过程就直接copy别人的教程了)及问题:1.将系统更新到最新:sudoapt
- linux 查 oracle进程,通过linux进程号(pid)查找Oracle的session中都执行那些sql
啟潍
linux查oracle进程
1、在以上图中使用系统进程PID查询对应的物理地址SELECTv.addr,v.*FROMv$processvWHEREv.SPID=‘’5256;2、通过该物理地址查找对应的SQL_IDSELECTt.SQL_ID,t.*FROMv$sessiontWHEREt.paddr=‘000000025C5EB9F8‘;3、通过SQL_ID来查找对应的SQL语句SELECTsql_textFROMv$s
- MySQL与Oracle对比及区别
web18285482512
面试学习路线阿里巴巴mysqloracle数据库
一、比较1、MySQL的特点性能卓越,服务稳定,很少出现异常宕机;开放源代码无版本制约,自主性及使用成本低;历史悠久,社区和用户非常活跃,遇到问题及时寻求帮助;软件体积小,安装使用简单且易于维护,维护成本低;品牌口碑效应;支持多种OS,提供多种API接口,支持多种开发语言,对流行的PHP,Java很好的支持2、Oracle的特点兼容性:Oracle产品采用标准SQL,并经过美国u构架标准技术所(N
- Oracle DB运维常用的SQL语句
小小不董
OracleDB管理及运维数据库oracle运维服务器dba
Listitem本文介绍一些OracleDB日常运维最常用到(使用频率很高)的SQL语句。1、查看表空间的名称及大小selectt.tablespace_name,round(sum(bytes/(1024*1024)),0)ts_sizefromdba_tablespacest,dba_data_filesdwheret.tablespace_name=d.tablespace_namegrou
- Oracle 12c多租户架构总结
weixin_34235135
数据库python
2019独角兽企业重金招聘Python工程师标准>>>Oracle数据库12c的一大创新即是其采用的多租户架构。对于多租户这项新功能,业内的评价褒贬不一。有的声音认为,这项功能的用处不是特别大,但在某些场景或特定的环境下,多租户依然有它的用处。其最大的用处就在于整合数据库。在一些小的系统环境中,多租户的特点就可以显现出来,其可以进行有效的整合,这样可以减少成本、降低管理的复杂度。多租户架构通过对不
- Oracle 12.2多租户架构中监听器监听到的数据库服务
msdnchina
PostgreSQLOracleDB12c新特性pdbautomaticstartupcdb
[oracle@db12cr2~]$lsnrctlstatusLSNRCTLforLinux:Version12.2.0.1.0-Productionon08-MAR-201701:50:44Copyright(c)1991,2016,Oracle.Allrightsreserved.Connectingto(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=db1
- sql统计相同项个数并按名次显示
朱辉辉33
javaoracle
现在有如下这样一个表:
A表
ID Name time
------------------------------
0001 aaa 2006-11-18
0002 ccc 2006-11-18
0003 eee 2006-11-18
0004 aaa 2006-11-18
0005 eee 2006-11-18
0004 aaa 2006-11-18
0002 ccc 20
- Android+Jquery Mobile学习系列-目录
白糖_
JQuery Mobile
最近在研究学习基于Android的移动应用开发,准备给家里人做一个应用程序用用。向公司手机移动团队咨询了下,觉得使用Android的WebView上手最快,因为WebView等于是一个内置浏览器,可以基于html页面开发,不用去学习Android自带的七七八八的控件。然后加上Jquery mobile的样式渲染和事件等,就能非常方便的做动态应用了。
从现在起,往后一段时间,我打算
- 如何给线程池命名
daysinsun
线程池
在系统运行后,在线程快照里总是看到线程池的名字为pool-xx,这样导致很不好定位,怎么给线程池一个有意义的名字呢。参照ThreadPoolExecutor类的ThreadFactory,自己实现ThreadFactory接口,重写newThread方法即可。参考代码如下:
public class Named
- IE 中"HTML Parsing Error:Unable to modify the parent container element before the
周凡杨
html解析errorreadyState
错误: IE 中"HTML Parsing Error:Unable to modify the parent container element before the child element is closed"
现象: 同事之间几个IE 测试情况下,有的报这个错,有的不报。经查询资料后,可归纳以下原因。
- java上传
g21121
java
我们在做web项目中通常会遇到上传文件的情况,用struts等框架的会直接用的自带的标签和组件,今天说的是利用servlet来完成上传。
我们这里利用到commons-fileupload组件,相关jar包可以取apache官网下载:http://commons.apache.org/
下面是servlet的代码:
//定义一个磁盘文件工厂
DiskFileItemFactory fact
- SpringMVC配置学习
510888780
springmvc
spring MVC配置详解
现在主流的Web MVC框架除了Struts这个主力 外,其次就是Spring MVC了,因此这也是作为一名程序员需要掌握的主流框架,框架选择多了,应对多变的需求和业务时,可实行的方案自然就多了。不过要想灵活运用Spring MVC来应对大多数的Web开发,就必须要掌握它的配置及原理。
一、Spring MVC环境搭建:(Spring 2.5.6 + Hi
- spring mvc-jfreeChart 柱图(1)
布衣凌宇
jfreechart
第一步:下载jfreeChart包,注意是jfreeChart文件lib目录下的,jcommon-1.0.23.jar和jfreechart-1.0.19.jar两个包即可;
第二步:配置web.xml;
web.xml代码如下
<servlet>
<servlet-name>jfreechart</servlet-nam
- 我的spring学习笔记13-容器扩展点之PropertyPlaceholderConfigurer
aijuans
Spring3
PropertyPlaceholderConfigurer是个bean工厂后置处理器的实现,也就是BeanFactoryPostProcessor接口的一个实现。关于BeanFactoryPostProcessor和BeanPostProcessor类似。我会在其他地方介绍。PropertyPlaceholderConfigurer可以将上下文(配置文件)中的属性值放在另一个单独的标准java P
- java 线程池使用 Runnable&Callable&Future
antlove
javathreadRunnablecallablefuture
1. 创建线程池
ExecutorService executorService = Executors.newCachedThreadPool();
2. 执行一次线程,调用Runnable接口实现
Future<?> future = executorService.submit(new DefaultRunnable());
System.out.prin
- XML语法元素结构的总结
百合不是茶
xml树结构
1.XML介绍1969年 gml (主要目的是要在不同的机器进行通信的数据规范)1985年 sgml standard generralized markup language1993年 html(www网)1998年 xml extensible markup language
- 改变eclipse编码格式
bijian1013
eclipse编码格式
1.改变整个工作空间的编码格式
改变整个工作空间的编码格式,这样以后新建的文件也是新设置的编码格式。
Eclipse->window->preferences->General->workspace-
- javascript中return的设计缺陷
bijian1013
JavaScriptAngularJS
代码1:
<script>
var gisService = (function(window)
{
return
{
name:function ()
{
alert(1);
}
};
})(this);
gisService.name();
&l
- 【持久化框架MyBatis3八】Spring集成MyBatis3
bit1129
Mybatis3
pom.xml配置
Maven的pom中主要包括:
MyBatis
MyBatis-Spring
Spring
MySQL-Connector-Java
Druid
applicationContext.xml配置
<?xml version="1.0" encoding="UTF-8"?>
&
- java web项目启动时自动加载自定义properties文件
bitray
javaWeb监听器相对路径
创建一个类
public class ContextInitListener implements ServletContextListener
使得该类成为一个监听器。用于监听整个容器生命周期的,主要是初始化和销毁的。
类创建后要在web.xml配置文件中增加一个简单的监听器配置,即刚才我们定义的类。
<listener>
<des
- 用nginx区分文件大小做出不同响应
ronin47
昨晚和前21v的同事聊天,说到我离职后一些技术上的更新。其中有个给某大客户(游戏下载类)的特殊需求设计,因为文件大小差距很大——估计是大版本和补丁的区别——又走的是同一个域名,而squid在响应比较大的文件时,尤其是初次下载的时候,性能比较差,所以拆成两组服务器,squid服务于较小的文件,通过pull方式从peer层获取,nginx服务于较大的文件,通过push方式由peer层分发同步。外部发布
- java-67-扑克牌的顺子.从扑克牌中随机抽5张牌,判断是不是一个顺子,即这5张牌是不是连续的.2-10为数字本身,A为1,J为11,Q为12,K为13,而大
bylijinnan
java
package com.ljn.base;
import java.util.Arrays;
import java.util.Random;
public class ContinuousPoker {
/**
* Q67 扑克牌的顺子 从扑克牌中随机抽5张牌,判断是不是一个顺子,即这5张牌是不是连续的。
* 2-10为数字本身,A为1,J为1
- 翟鸿燊老师语录
ccii
翟鸿燊
一、国学应用智慧TAT之亮剑精神A
1. 角色就是人格
就像你一回家的时候,你一进屋里面,你已经是儿子,是姑娘啦,给老爸老妈倒怀水吧,你还觉得你是老总呢?还拿派呢?就像今天一样,你们往这儿一坐,你们之间是什么,同学,是朋友。
还有下属最忌讳的就是领导向他询问情况的时候,什么我不知道,我不清楚,该你知道的你凭什么不知道
- [光速与宇宙]进行光速飞行的一些问题
comsci
问题
在人类整体进入宇宙时代,即将开展深空宇宙探索之前,我有几个猜想想告诉大家
仅仅是猜想。。。未经官方证实
1:要在宇宙中进行光速飞行,必须首先获得宇宙中的航行通行证,而这个航行通行证并不是我们平常认为的那种带钢印的证书,是什么呢? 下面我来告诉
- oracle undo解析
cwqcwqmax9
oracle
oracle undo解析2012-09-24 09:02:01 我来说两句 作者:虫师收藏 我要投稿
Undo是干嘛用的? &nb
- java中各种集合的详细介绍
dashuaifu
java集合
一,java中各种集合的关系图 Collection 接口的接口 对象的集合 ├ List 子接口 &n
- 卸载windows服务的方法
dcj3sjt126com
windowsservice
卸载Windows服务的方法
在Windows中,有一类程序称为服务,在操作系统内核加载完成后就开始加载。这里程序往往运行在操作系统的底层,因此资源占用比较大、执行效率比较高,比较有代表性的就是杀毒软件。但是一旦因为特殊原因不能正确卸载这些程序了,其加载在Windows内的服务就不容易删除了。即便是删除注册表中的相 应项目,虽然不启动了,但是系统中仍然存在此项服务,只是没有加载而已。如果安装其他
- Warning: The Copy Bundle Resources build phase contains this target's Info.plist
dcj3sjt126com
iosxcode
http://developer.apple.com/iphone/library/qa/qa2009/qa1649.html
Excerpt:
You are getting this warning because you probably added your Info.plist file to your Copy Bundle
- 2014之C++学习笔记(一)
Etwo
C++EtwoEtwoiterator迭代器
已经有很长一段时间没有写博客了,可能大家已经淡忘了Etwo这个人的存在,这一年多以来,本人从事了AS的相关开发工作,但最近一段时间,AS在天朝的没落,相信有很多码农也都清楚,现在的页游基本上达到饱和,手机上的游戏基本被unity3D与cocos占据,AS基本没有容身之处。so。。。最近我并不打算直接转型
- js跨越获取数据问题记录
haifengwuch
jsonpjsonAjax
js的跨越问题,普通的ajax无法获取服务器返回的值。
第一种解决方案,通过getson,后台配合方式,实现。
Java后台代码:
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
String ca
- 蓝色jQuery导航条
ini
JavaScripthtmljqueryWebhtml5
效果体验:http://keleyi.com/keleyi/phtml/jqtexiao/39.htmHTML文件代码:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>jQuery鼠标悬停上下滑动导航条 - 柯乐义<
- linux部署jdk,tomcat,mysql
kerryg
jdktomcatlinuxmysql
1、安装java环境jdk:
一般系统都会默认自带的JDK,但是不太好用,都会卸载了,然后重新安装。
1.1)、卸载:
(rpm -qa :查询已经安装哪些软件包;
rmp -q 软件包:查询指定包是否已
- DOMContentLoaded VS onload VS onreadystatechange
mutongwu
jqueryjs
1. DOMContentLoaded 在页面html、script、style加载完毕即可触发,无需等待所有资源(image/iframe)加载完毕。(IE9+)
2. onload是最早支持的事件,要求所有资源加载完毕触发。
3. onreadystatechange 开始在IE引入,后来其它浏览器也有一定的实现。涉及以下 document , applet, embed, fra
- sql批量插入数据
qifeifei
批量插入
hi,
自己在做工程的时候,遇到批量插入数据的数据修复场景。我的思路是在插入前准备一个临时表,临时表的整理就看当时的选择条件了,临时表就是要插入的数据集,最后再批量插入到数据库中。
WITH tempT AS (
SELECT
item_id AS combo_id,
item_id,
now() AS create_date
FROM
a
- log4j打印日志文件 如何实现相对路径到 项目工程下
thinkfreer
Weblog4j应用服务器日志
最近为了实现统计一个网站的访问量,记录用户的登录信息,以方便站长实时了解自己网站的访问情况,选择了Apache 的log4j,但是在选择相对路径那块 卡主了,X度了好多方法(其实大多都是一样的内用,还一个字都不差的),都没有能解决问题,无奈搞了2天终于解决了,与大家分享一下
需求:
用户登录该网站时,把用户的登录名,ip,时间。统计到一个txt文档里,以方便其他系统调用此txt。项目名
- linux下mysql-5.6.23.tar.gz安装与配置
笑我痴狂
mysqllinuxunix
1.卸载系统默认的mysql
[root@localhost ~]# rpm -qa | grep mysql
mysql-libs-5.1.66-2.el6_3.x86_64
mysql-devel-5.1.66-2.el6_3.x86_64
mysql-5.1.66-2.el6_3.x86_64
[root@localhost ~]# rpm -e mysql-libs-5.1