实现类用Lucene PrefixQuery 来实现 Google Suggest 的功能的一种简单方法
开场白:
在我们上google或者baidu的时候,在输入框中输入关键字,然后就有建议的提示来让用户选择。如下图:
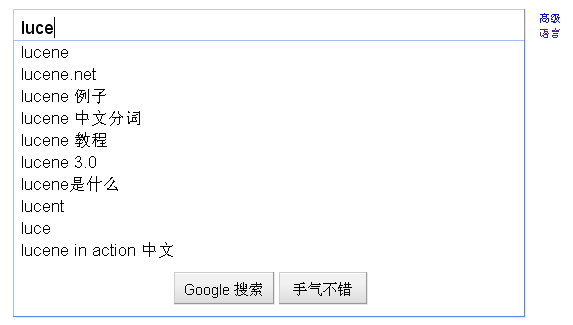
可以看到,输入了前面的关键字就能全部匹配了关键出来了。但有人会问,直接用BooleanQuery与TermQuery组合起来即可以实现这样的结果了。可是这里有点不同的是首先用户输入的每一个字母并不一定是分词器可以分出来的,同时,大家可以发现返回的结果都是一定先以用户输入的为前匹配的,所以如果单纯用普通的分词是不能实现这样的效果的。
如何做:
但如果我们理解了Term在Lucene中的应用后,就很容易实现这个效果了。用公司名称来举例子,现在我们需要用户输入公司名称中的某部分,用户每输入一个字,则需要每次返回全包含这些关键字的结果,比如:
用户输入了“电力工程”,用户会匹配出
广州市 电力工程制造有限公司
广州市天河区 电力工程有限公司
广州市白云区 电力工程生产有限公司
。。。。。
而不能搜索出这样的结果,因为它不是全匹配
广东省 电力电子 设备公司
江门市 电力用品 设备公司
为了实现这样的效果,我们在建立索引的时候需要注意了。
平时我们建立索引都是通过
来建立的,而这样把 add了Field索引后,其实是已经通过了建立IndexWriter时的传入的那个分词器作了分词了。
所以我们手动的不使用IndexWriter的分词了。
对一个公司名的字段作了以下的方式建立索引。
其实这样使用公司名称在索引中建立了以下的 Term 保存到索引里面
广州市电气设备制造有限公司
州市电气设备制造有限公司
市电气设备制造有限公司
电气设备制造有限公司
气设备制造有限公司
设备制造有限公司
备制造有限公司
制造有限公司
。。。。。。
司
注意思了,这里都没有作任何的分词的,或者大家可以通过调用 toString()方法 查看 这个Document 里面的Term情况就明白了。
OK,基本完成了。在搜索的时候,我们只需要
按用户输入的关键字
这样Lucene就会以[Query:companyName 电气*] 这样的前匹配搜索了,大家可以看到,无论用户输入的字是否能分词也匹配上了上面那个公司名称了。同时也是全匹配的。
结束语:
这里有人会提出使用FuzzyQuery或者wildcardQuery等。类正则表达式的搜索方法,当然这个如果是非中文当然可以的,如果是中文的话,还是不支持的。
欢迎大家指出本文章的错误之处。欢迎在博客上留言。欢迎转载,请注明出处:
http://kernaling-wong.iteye.com/blog/694711
在我们上google或者baidu的时候,在输入框中输入关键字,然后就有建议的提示来让用户选择。如下图:
可以看到,输入了前面的关键字就能全部匹配了关键出来了。但有人会问,直接用BooleanQuery与TermQuery组合起来即可以实现这样的结果了。可是这里有点不同的是首先用户输入的每一个字母并不一定是分词器可以分出来的,同时,大家可以发现返回的结果都是一定先以用户输入的为前匹配的,所以如果单纯用普通的分词是不能实现这样的效果的。
如何做:
但如果我们理解了Term在Lucene中的应用后,就很容易实现这个效果了。用公司名称来举例子,现在我们需要用户输入公司名称中的某部分,用户每输入一个字,则需要每次返回全包含这些关键字的结果,比如:
用户输入了“电力工程”,用户会匹配出
广州市 电力工程制造有限公司
广州市天河区 电力工程有限公司
广州市白云区 电力工程生产有限公司
。。。。。
而不能搜索出这样的结果,因为它不是全匹配
广东省 电力电子 设备公司
江门市 电力用品 设备公司
为了实现这样的效果,我们在建立索引的时候需要注意了。
平时我们建立索引都是通过
Doceume doc = new Document();
doc.add(new Field("CompanyName","广州市电气设备制造有限公司",Index.ANALYZED,Store.NO));
来建立的,而这样把 add了Field索引后,其实是已经通过了建立IndexWriter时的传入的那个分词器作了分词了。
所以我们手动的不使用IndexWriter的分词了。
对一个公司名的字段作了以下的方式建立索引。
String companyName = "广州市电气设备制造有限公司";
int len = companyName.length();
for(int i=0;i<len;i++){
String value = companyName.subString(i,len);
indexWriter.add(new Field("CompanyName",value ,Index.NOT_ANALYZED,Store.NO));
|
其实这样使用公司名称在索引中建立了以下的 Term 保存到索引里面
广州市电气设备制造有限公司
州市电气设备制造有限公司
市电气设备制造有限公司
电气设备制造有限公司
气设备制造有限公司
设备制造有限公司
备制造有限公司
制造有限公司
。。。。。。
司
注意思了,这里都没有作任何的分词的,或者大家可以通过调用 toString()方法 查看 这个Document 里面的Term情况就明白了。
OK,基本完成了。在搜索的时候,我们只需要
按用户输入的关键字
String keyWord = "电气";
PrefixQuery pg = new PrefixQuery(new Term("CompanyName",keyWord ));
这样Lucene就会以[Query:companyName 电气*] 这样的前匹配搜索了,大家可以看到,无论用户输入的字是否能分词也匹配上了上面那个公司名称了。同时也是全匹配的。
结束语:
这里有人会提出使用FuzzyQuery或者wildcardQuery等。类正则表达式的搜索方法,当然这个如果是非中文当然可以的,如果是中文的话,还是不支持的。
欢迎大家指出本文章的错误之处。欢迎在博客上留言。欢迎转载,请注明出处:
http://kernaling-wong.iteye.com/blog/694711