Rethinking architecture with CQRS
这是axonframework的作者Allard Buijze写的文章,用CQRS来审视架构
banq也做过翻译http://www.jdon.com/jivejdon/thread/37891
Many applications use some form of persistent storage to store its state. However, important information about this state is lost: why is the state as it currently is. Furthermore, a single model is used to store information that is retrieved for many different purposes, often resulting in extremely complex and bog-slow SQL queries.
Command Query Responsibility Segregation (CQRS) is an architectural style that makes a clear distinction between commands that change the application state and queries that expose the application state.
Background
My interest in CQRS was triggered when I saw Greg Young explain “State Transitions in Domain-Driven Design” on InfoQ. In this interview, Greg explains how he sees that application would benefit from using separate models for state validation and transition on one side and maintaining a view on the current state on the other.
One of the problems that Greg describes is the fact that a single model is often used for different purposes. It is nicely illustrated by the SQL query below. It shows how the model chosen in the application is not suited for the purpose of providing certain information (messages between users, in this case).
queryBuilder.append( "m.*, " + "m.origin_participant_id as message_origin_participant_id, " + "po.first_name as message_origin_participant_first_name, " + "po.avatar as message_origin_participant_avatar, " + "po_ua.username as message_origin_participant_username, " + "CASE WHEN !isnull(po.fieldworker_project_id) THEN 'fieldworker' WHEN !isnull(po_ap.project_id) THEN 'fundraiser' ELSE 'player' END AS message_origin_participant_type, " + "po.city as message_origin_participant_city, " + "c.name as message_origin_participant_country, " + "pd.first_name as message_destination_participant_first_name, " + "pd.avatar as message_destination_participant_avatar, " + "pd_ua.username as message_destination_participant_username, " + "CASE WHEN !isnull(pd.fieldworker_project_id) THEN 'fieldworker' WHEN !isnull(pd_ap.project_id) THEN 'fundraiser' ELSE 'player' END AS message_destination_participant_type, " + "m.destination_participant_id as message_destination_participant_id " + "from internal_message m " + "left join player po on m.origin_participant_id = po.id " + "left join (select player_id, project_id from ambassador_project where enabled = true group by player_id) po_ap on po_ap.player_id = po.id " + "left join user_account po_ua on po.user_account_id = po_ua.id " + "left join country c on po.country_id = c.id " + "left join player pd on m.destination_participant_id = pd.id " + "left join (select player_id, project_id from ambassador_project where enabled = true group by player_id) pd_ap on pd_ap.player_id = pd.id " + "inner join user_account pd_ua on pd.user_account_id = pd_ua.id " + "where m.destination_participant_id = ? " );
Wouldn’t it be a lot nice to have a query such as the one below instead?
SELECT * FROM messages WHERE receiving_participant = ?
Achieving such queries is very easy, but doing so without making your model impossible to use for maintaining state integrity and guarding invariants is a lot harder. Well, unless you apply CQRS.
Architecture
The diagram below shows an overview of a typical CQRS architecture.
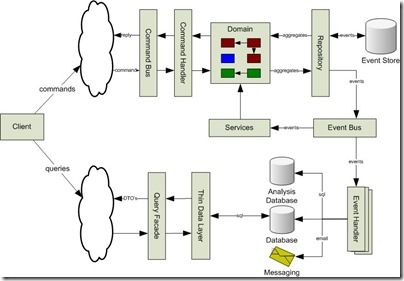
When a command comes in, it will load an aggregate from the repository and execute certain operations on it. As a result of these operations, the aggregate produces events, which are picked up for storage by the repository and for dispatching by the event bus. The event bus will dispatch each event to all (interested) event handlers. Some of these event handlers will perform actions on other (related) aggregates, some others will update the database tables they manage.
Having handlers update the data in the database means that your tables do not have to be normalized anymore. Instead, CQRS allows you to optimize your tables for the way you want to query them. This makes the data layer processing your queries really simple, and maintainable.
Furthermore, since all state changes are initiated by events, these events become a reliable source for an audit trail. By storing these events, you have an audit trail that you can use to replay the entire application history. Instead of just seeing “current application state” only, you can see all the changes that have led to the current state, providing valuable information trying to find bugs or deal with customer complaints.
Benefits
Matches the natural language used
At first glance, such an architecture might look very complex and over-engineered. However, after taking the first implementation steps, it felt pretty natural. In fact, when you explain the behavior of an application, you use a style that fits CQRS quite nicely: “when an order is approved, we send a confirmation email to the customer”.
Extensibility
Imagine an order management application. With CQRS, you could have an “OrderApproved” event, which is caught by a database updating event handler as well as one that sends an email to the customer with order information. If you later on decide to store the order information in an accounting tool as well, all it takes is adding an event handler that does the accounting integration. And since you can reload historic events as well, you can even reconstruct historic information to put in the accounting table.
Reliable audit trail
As I said above [see section Architecture], the model that is used to process command will generate events. These events are the sole source of state changes for the domain classes. If you want to load an aggregate from persistent storage, it will actually load all the past events of that aggregate. This process is called Event Sourcing. When events become too numerous, you can combine a number of historic events into a single snapshot event. The events that have been combined can then be archived for auditing purposes.
Event Sourcing turns your event storage into an extremely reliable audit trail. The events do no only show what happened and when, but they will also reveal the intention a user had. Not only is it an audit trail that will never move out-of-sync with your application, you can use the audit trail to actually replay all actions in the application. Events are not just a notification of state change, they are also the source of state change.
Transparent distributed processing
When using events as the trigger for state changes, you can easily distribute your application over multiple processing units (servers, JVM’s, whatever). Events can easily be serialized and sent from one server to another over JMS, via the file system or even email. The Spring Integration framework –a messaging framework – fits nicely with the event processing concept.
You could even let certain types of aggregates live on dedicated machines. This allows you to choose different SLA’s for different parts of you application, such as giving order creation a higher priority than sales reporting.
Performance and Scalability
Since event handling is done asynchronously, a user does not have to wait for all changes to be applied. Especially when integrating with external systems, this can improve liveness of an application significantly.
Another aspect of CQRS is that it heavily builds upon BASE (Basic Availability, Soft-state, Eventual consistency) transactions. Although the “eventual” part scares a lot of customers and developers, the price of distributed ACID transactions is one that customer typically resent. In most cases “eventual” is just a matter of several milliseconds. But you’re free to make that seconds, minutes or even hours if your SLA permits it (think of management reports that are only read once a week or month).
Asynchronous analysis
When you build a CQRS style application, all activity in your application is processed using events. This makes it easy to catch these events and monitor them for inconsistent behavior. Event analysis tools like Esper allow you to monitor event streams for patterns that indicate possible fraud.
For example, when you detect that a sudden large number of users has an increased amount of failed login attempts, you could decide to block these accounts for a small period of time. In one of our projects, we use RSA Adaptive Authentication to increase the level of authentication required when someone tries to login on an account that might be the subject of dictionary attacks.