http://blog.csdn.net/dm_vincent/article/details/40503685
利用Stream类型的“懒”操作
代码中的很多操作都是Eager的,比如在发生方法调用的时候,参数会立即被求值。总体而言,使用Eager方式让编码本身更加简单,然而使用Lazy的方式通常而言,即意味着更好的效率。
本篇文章就是为了展示Java 8中新特性是如何让我们能够更方便的写出Lazy方式代码。
延迟初始化
对于会消耗较多资源的对象,使用延迟初始化是比较好的选择。这不仅能够节省一些资源,同时也能够加快对象的创建速度,从而从整体上提升性能。
但是对一个对象实现延迟初始化时,需要注意的一点就是这些实现细节不应该暴露给用户,即用户能够按照正常的流程来使用该对象。
典型实现
public class Heavy {
public Heavy() { System.out.println("Heavy created"); }
public String toString() { return "quite heavy"; }
}
public class HolderNaive {
private Heavy heavy;
public HolderNaive() {
System.out.println("Holder created");
}
public Heavy getHeavy() {
if(heavy == null) {
heavy = new Heavy();
}
return heavy;
}
//...
}
利用以上的代码:
final HolderNaive holder = new HolderNaive();
System.out.println("deferring heavy creation...");
System.out.println(holder.getHeavy());
System.out.println(holder.getHeavy());
// Holder created
// deferring heavy creation...
// Heavy created
// quite heavy
// quite heavy
上述代码在单线程环境中能够正常工作,但是在多线程环境中就不尽然了。当多个线程同时调用getHeavy方法时,也许会发生竞态条件(Race Condition),导致有多个Heavy实例被创建,最直观的解决方案就是给该方法加上synchronized关键字:
public synchronized Heavy getHeavy() {
if(heavy == null) {
heavy = new Heavy();
}
return heavy;
}
这样虽然能够保证确实只有一个heavy实例被创建,但是弊端也很明显:每次调用getHeavy方法时,都需要进入代价高昂的synchronized代码区域。实际上,只有在第一次需要创建Heavy实例的时候,才需要保证线程安全。当该实例创建完毕之后,再使用synchronized来保证线程安全就没有必要了。
使用Lambda表达式
这里我们需要用到的是函数接口Supplier,其中定义了一个get方法用来得到需要的实例:
Supplier<Heavy> supplier = () -> new Heavy();
Supplier<Heavy> supplier = Heavy::new;
除了利用Lambda表达式来得到实例,还可以使用方法引用(引用的是构造函数)来完成同样的事情。
public class Holder {
private Supplier<Heavy> heavy = () -> createAndCacheHeavy();
public Holder() {
System.out.println("Holder created");
}
public Heavy getHeavy() {
return heavy.get();
}
//...
private synchronized Heavy createAndCacheHeavy() {
class HeavyFactory implements Supplier<Heavy> {
private final Heavy heavyInstance = new Heavy();
public Heavy get() { return heavyInstance; }
}
if(!HeavyFactory.class.isInstance(heavy)) {
heavy = new HeavyFactory();
}
return heavy.get();
}
}
当Holder的实例被创建时,其中的Heavy实例还没有被创建。下面我们假设有三个线程会调用getHeavy方法,其中前两个线程会同时调用,而第三个线程会在稍晚的时候调用。
当前两个线程调用该方法的时候,都会调用到createAndCacheHeavy方法,由于这个方法是同步的。因此第一个线程进入方法体,第二个线程开始等待。在方法体中会首先判断当前的heavy是否是HeavyInstance的一个实例。如果不是,就会将heavy对象替换成HeavyFactory类型的实例。显然,第一个线程执行判断的时候,heavy对象还只是一个Supplier的实例,所以heavy会被替换成为HeavyFactory的实例,此时Heavy实例会被真正的实例化。等到第二个线程进入执行该方法时,heavy已经是HeavyFactory的一个实例了,所以会立即返回。当第三个线程执行getHeavy方法时,由于此时的heavy对象已经是HeavyFactory的实例了,因此它会直接返回需要的实例,和同步方法createAndCacheHeavy没有任何关系了。
以上代码实际上实现了一个轻量级的虚拟代理模式(Virtual Proxy Pattern)。保证了懒加载在各种环境下的正确性。
延迟求值(Lazy Evaluation)
延迟求值的主要目的是减少需要执行的代码量来提高执行速度。
其实Java语言中有一些地方已经应用了延迟求值的概念,比如对逻辑表达式的求值:
在执行fn1() || fn2()时,当fn1()返回true的时候,fn2()是不会被执行的。同样地,在执行fn1() && fn2()时, 当fn1()返回false的时候,fn2()是不会被执行的。这就是大家熟知的“短路(Short-circuiting)操作”。
然而对于方法调用,在发生实际调用前所有传入的参数都会被求值,即使某些参数在方法中根本就没有被用到。因此这就造成了潜在的性能浪费,我们可以使用Lambda表达式来进行改进。
当参数列表中有Lambda表达式和方法引用时,这种类型的参数只有在真正地需要被使用时才会由Java编译器求值,我们可以利用这一点来实现延迟求值。Java 8中新添加的Stream类型的许多方法都实现了延迟求值。比如filter方法接受的Predicate函数接口,并不一定会被集合中的所有元素调用。因此,我们可以考虑将方法的参数冲构成函数接口来实现延迟求值。
Eager求值
public class Evaluation {
public static boolean evaluate(final int value) {
System.out.println("evaluating ..." + value);
simulateTimeConsumingOp(2000);
return value > 100;
}
public static void eagerEvaluator(
final boolean input1, final boolean input2) {
System.out.println("eagerEvaluator called...");
System.out.println("accept?: " + (input1 && input2));
}
//...
}
eagerEvaluator(evaluate(1), evaluate(2));
// evaluating ...1
// evaluating ...2
// eagerEvaluator called...
// accept?: false
以上的代码中,虽然希望使用短路操作来得到最后的结果(input1 && input2),但是已经晚了。在对参数进行求值的时候,input1和input2的值实际上就已经被确认了,从上面的输出可以看出这一点。这段代码会执行至少4秒,显然这不是最优的。
延迟求值的设计
如果我们知道方法中的某些参数可能不会被用到,那么就可以对它们进行重构,将它们替换成函数接口来实现延迟求值。比如上述代码中使用到了短路操作,说明input2的求值也许是不必要的,这时可以将它替换成Supplier接口:
public static void lazyEvaluator(
final Supplier<Boolean> input1, final Supplier<Boolean> input2) {
System.out.println("lazyEvaluator called...");
System.out.println("accept?: " + (input1.get() && input2.get()));
}
替换成Supplier类型的函数接口后,只有在调用它的get方法,才会真正执行求值操作。那么上述的短路操作就有意义了,当input1.get()返回的是false时,input2.get()根本就不会被调用:
lazyEvaluator(() -> evaluate(1), () -> evaluate(2));
// lazyEvaluator called...
// evaluating ...1
// accept?: false
此时的执行时间只有2秒多一点,比之前的4秒而言,性能提高了接近100%。 在某些参数不被需要的场合下,借助Lambda表达式或者方法引用来实现那些参数确实能够增加性能,但是也使得代码稍微的复杂了一点,但是为了性能的提升这些代价也是值得的。
利用Stream的“懒”
前文中已经对Stream类型进行了一些介绍,但是没有提到一点,就是Stream类型很“懒”。实际上正式由于这种“懒”,使得程序的性能能够提高。事实上,在前面使用Stream时,我们已经利用了它的“懒”,Stream只会在真的需要时才会执行求值操作。
中间和结束操作(Intermediate and Terminal Operation)
Stream类型有两种类型的方法:
- 中间操作(Intermediate Operation)
- 结束操作(Terminal Operation)
Stream之所以“懒”的秘密也在于每次在使用Stream时,都会连接多个中间操作,并在最后附上一个结束操作。 像map()和filter()这样的方法是中间操作,在调用它们时,会立即返回另一个Stream对象。而对于reduce()及findFirst()这样的方法,它们是结束操作,在调用它们时才会执行真正的操作来获取需要的值。
比如,当我们需要打印出第一个长度为3的大写名字时:
public class LazyStreams {
private static int length(final String name) {
System.out.println("getting length for " + name);
return name.length();
}
private static String toUpper(final String name ) {
System.out.println("converting to uppercase: " + name);
return name.toUpperCase();
}
//...
public static void main(final String[] args) {
List<String> names = Arrays.asList("Brad", "Kate", "Kim", "Jack", "Joe", "Mike", "Susan", "George", "Robert", "Julia", "Parker", "Benson");
final String firstNameWith3Letters = names.stream()
.filter(name -> length(name) == 3)
.map(name -> toUpper(name))
.findFirst()
.get();
System.out.println(firstNameWith3Letters);
}
}
你可能认为以上的代码会对names集合进行很多操作,比如首先遍历一次集合得到长度为3的所有名字,再遍历一次filter得到的集合,将名字转换为大写。最后再从大写名字的集合中找到第一个并返回。
可是实际情况并不是这样,不要忘了Stream可是非常“懒”的,它不会执行任何多余的操作。
方法求值顺序
对于Stream操作,更好的代码阅读顺序是从右到左,或者从下到上。每一个操作都只会做到恰到好处。如果以Eager的视角来阅读上述代码,它也许会执行15步操作:
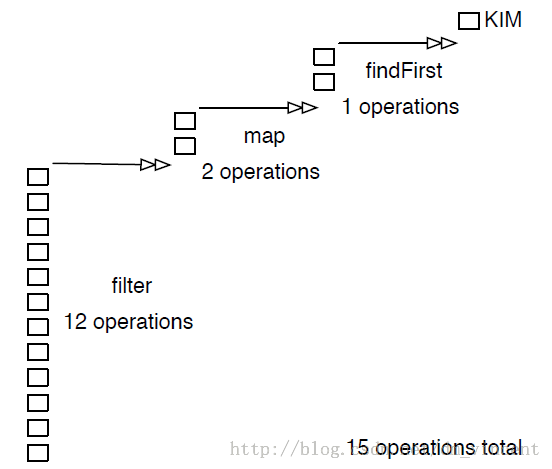
但是实际上,只有当findFirst方法被调用时,filter和map方法才会被真正触发。而filter也不会一口气对整个集合实现过滤,它会一个个的过滤,如果发现了符合条件的元素,会将该元素置入到下一个中间操作,也就是map方法中。因此,真正的执行顺序是这样的:
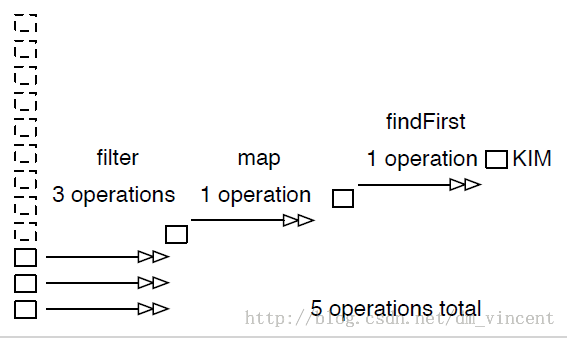 \
\
控制台的输出是这样的:
getting length for Brad
getting length for Kate
getting length for Kim
converting to uppercase: Kim
KIM
当结束操作获得了它需要的答案时,整个计算过程就结束了。如果没有获得到答案,那么它会要求中间操作对更多的集合元素进行计算,直到找到答案或者整个集合被处理完毕。
JDK会将所有的中间操作合并成一个,这个过程被称为熔断操作(Fusing Operation)。因此,在最坏的情况下(即集合中没有符合要求的元素),集合也只会被遍历一次,而不会像我们想象的那样执行了多次遍历。
为了看清楚在底层发生的事情,我们可以将以上对Stream的操作按照类型进行分割:
Stream<String> namesWith3Letters = names.stream()
.filter(name -> length(name) == 3)
.map(name -> toUpper(name));
System.out.println("Stream created, filtered, mapped...");
System.out.println("ready to call findFirst...");
final String firstNameWith3Letters = namesWith3Letters.findFirst().get();
System.out.println(firstNameWith3Letters);
// 输出结果
// Stream created, filtered, mapped...
// ready to call findFirst...
// getting length for Brad
// getting length for Kate
// getting length for Kim
// converting to uppercase: Kim
// KIM
根据输出的结果,我们可以发现在声明了Strema对象上的中间操作之后,中间操作并没有被执行。只有当真正发生了findFirst()调用之后,才会执行中间操作。
创建无限集合
Stream类型的另外一个特点是:它们可以是无限的。这一点和集合类型不一样,在Java中的集合类型必须是有限的。Stream之所以可以是无限的也是源于Stream“懒”的这一特点。
比如我们可以使用Stream类型来表达一串质数,首先我们需要一个工具方法来判断一个数是否是质数:
public static boolean isPrime(final int number) {
return number > 1 &&
IntStream.rangeClosed(2, (int) Math.sqrt(number))
.noneMatch(divisor -> number % divisor == 0);
}
这里又运用了IntStream的另一个特性,即rangeClosed方法用来得到表示某一个区间的IntStream对象。紧接着使用了Stream对象上的noneMatch方法,这个方法会接受一个Predicate类型的函数接口作为参数,只有当Stream上的所有元素都不满足该Predicate时,才会返回true。
所以我们可以任意指定一个起点,得到从该起点开始的所有质数集合:
public static List<Integer> primes(final int number) {
if(isPrime(number))
return concat(number, primes(number + 1));
else
return primes(number + 1);
}
在实现了concat方法后,如果你运行这段代码那么很快就会返回一个大大的StackOverflowError。这是因为Java的集合一定是有限的,而显然上述代码试图使用一个有限的集合来表示一串无穷的质数序列。这个StackOverflowError的产生原因就是有太多层递归调用了。
那为什么Stream能够代表一个无限的集合呢?这也同样源于Stream“懒”的特性。Stream只会返回你需要的元素,而不会一次性地将整个无限集合返回给你。
Stream接口中有一个静态方法iterate(),这个方法能够为你创建一个无限的Stream对象。它需要接受两个参数:
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)
seed表示的是这个无限序列的起点,而UnaryOperator则表示的是如何根据前一个元素来得到下一个元素,比如序列中的第二个元素可以这样决定:f.apply(seed)。
因此,根据一个起点和需要的质数数量,我们可以写出下面的代码:
public class Primes {
private static int primeAfter(final int number) {
if(isPrime(number + 1))
return number + 1;
else
return primeAfter(number + 1);
}
public static List<Integer> primes(final int fromNumber, final int count) {
return Stream.iterate(primeAfter(fromNumber - 1), Primes::primeAfter)
.limit(count).collect(Collectors.<Integer>toList());
}
//...
}
对于iterate和limit,它们只是中间操作,得到的对象仍然是Stream类型。 对于collect方法,它是一个结束操作,会触发中间操作来得到需要的结果。
调用primes方法也十分直观:
System.out.println("10 primes from 1: " + primes(1, 10));
System.out.println("5 primes from 100: " + primes(100, 5));
// 10 primes from 1: [2, 3, 5, 7, 11, 13, 17, 19, 23, 29]
// 5 primes from 100: [101, 103, 107, 109, 113]