Java 基础 - 正则表达式 Regex
Text Symbol
1. The special text symbol - Meta Characters
a. [ ] \ ^ $ . | ? * + ( ) those characters are remaining for Regex engine of some special usage.
b. If you want to use those special text symbol as the normal text symbol, you need to added the escape/convert character '\'.
Example , if you want to match the text '1+1=2', you need to use the regex "1\+1=2".
2. None display text symbol
"\t" represents Tab(0x09) symbol
"\r" represents Carriage Return(0x0D) symbol
"\n" represents Line Break(0x0A) symbol
That Windows adopt "\r\n" to end with one line but Linux using "\n"
Regex Charset
The regex charset is a group of chars around in regex "[]"
1. [abc] and [a-z]
[abc] means matching with one character that is a or b or c
[a-z] means matching with any one of the characters from a to z.
2. Negative charset '^'
a. syntax - right after '[', follows a '^' means to fetch the other character string against with the regex charset specified.
Example ,
1. '[^a]+' matches on "abacad", return "bcd", to retrieve the other character string against with 'a'.
2. "[^abc]+" matches on "abcde", the results should be "de", against character string 'abc'
b. First focus that, '^' can match with the '\r' or '\n'
c. Second focus on that, '^' must to match with one charater.
Example , "q[^u]" means it will match a sub-charset start with q and ending with a non-"u" character must, so it will not match "Iraq", but it will match "Iraq is a country".
d. Last focus on that,
Only '^' is right after '[' of one charset, it means the Negative charset
Else if it not, like this '[a^b]+', here '^' means a normal regex charset. it will match "a^b"
3. The Abbreviation
"\d" represents with "[0-9]"
"\w" represents represents with [a-zA-z0-9]
"\s" represents with "Empty Char", it always includes Tab and '\r\n' or '\n'
Revert ,
"\D" represents with "[^\d]"
"\W" represents with "[^\w]"
"\S" represents with "[^\s]"
Examples,
a. "\s\d" matches a sub-charset heading with Empty chars right after with a Number
b. "[\s\d]" matches one character if it was a Empty char or a Number.
Regex Engine
1. text-directed
Abbreviation as DFA, I do not want to deeply metioned it due to I only focus on Java Regex Engine.
2. regex-directed
Abbreviation as NFA, most popular engine currently.
Features
1). Greeding quantifiers Mechanism- Always return leftmost matched one
Example:
a. Uses regex "regex|regex not" to match with literal "regex not"
it will return "regex", cause it will return the leftmost matched one not the most perfect matched one
b. Uses regex "cat" to match with "He captured a catfish for his cat" ( Not Global Search )
it will return "catfish" not the "cat", cause it will return the leftmost matched one
2). Lazy quantifiers Mechanism
- At least to reuse the predefined one regex formula to match
3). How to distinguish Greeding quantifiers with Lazy quantifiers mechanism
Example belows,
Using regex "<.+>" to match with "This is a <EM>first</EM> test" to find out all HTML Nodes. So the expected results should be "<EM>" and </EM>.
But we got "<EM>first</EM>" back due to Greeding matching mechansim
1. The process of Greeding matching Mechanism
a. Uses the first regex formula "<" matched with "<"
b. Uses the next regex formula "<.+" to match all the remain characeter string "<EM>first</EM> test", then it failed at the End boundary. (Now, the matched stream is "<EM>first</EM> test".
c. Uses the next "<.+>" to match with the whole stream "<EM>first</EM> test" but not matched with the regex, then do backtrace (Backtrace - one index of the mathced stream back as the result of "<EM>first</EM> tes" , regex expression remain as it is "<.+>") --> "<EM>first</EM> tes" still not matched with the regex --> ..... --> until the "<EM>first</EM>" matched with "<.+>".
d. Then return the matched result <EM>first</EM>
Conclusion: it always to reuse the predefined one regex formula to do process match
the same with ".+", the "?*" is also Greeding Mechansim
2. The process of Lazy matching Mechanism
If want to using Lazy matching, need to change the formula from "<.+>" to <.+?> , "?*" to <?*? > to enable we have use Lazy Matching
a. Uses the start regex formula "<" matched with "<"
b. Uses the next regex formula "<.+" matched with "<E", now matched "<E"
c. Uses the next regex formula "<.+>" to match next char "<EM", but failed, then backtrace
( Backtrace - remain the current index, regex expression backtrace one as to be "<.+ " - compare with the Greeding Mechanism )
d. Uses the former regex formula ".+" to match current char "M", now matched <EM
e. Uses the next regex formula ">" matched with the next char ">"
f. return "<EM> "
g. continue process a --> f, then will matched "</EM> "
Conclusion: it alaways at least to reuse the former one regex formula to do match
But the performance with Lazy Mechansim is not well
3. The alternative to replace using Lazy Matching Mechansim
We can use "<[^>]+>" to replace the formula "<.+>", the reason for using this is we do not need traceback
3. How to distinguish text-directed Engine and regex-directed Engine
Uses regex "regex|regex not" to match with literal "regex not"
If it returned "regex", it is regex-directed Engine. If not, it is text-directed Engine
Repeatly Matching Character
1. "?" means matches zero time or one time
2. "+" means matches one time or more time
3. "*" means matches zero time or more time
4. {min,max} means matches repeatly from min times to max times
{0, } == *, {1, } == +
Mostly Common Used Regex Character "."
1. "." can matches any character, but one Exception belows can not matched,
2. Exception character - Line Break and Line seed Character
Here is caused by the history, in the earlier time, the old computer only support line by line to read the file stream. so "." represents as the regex charset "[^\r\n]" or "^[\n]"
3. How to enable "." to match with the '\r\n' or '\n'
- In java, the default Pattern.complie(regex) is not support '.' to match with "[^\r\n]" or "^[\n]"
- Then we can use Pattern.complie(regex, Pattern.DOTALL) to enable this ability.
The Anchors
1. Notion
Anchors have some different with the regex formula, it can not matches with any character, it only represent start point and the ending point of one charset.
2. Simle Examples
"^\d+$" -- to check the user input should be all numbers.
"^\s*" -- to check the pre-defined blank-spaces char.
3. Multiple-Line Support/unSupport
Suppose we have the stream "first line \n\rsecond line "
1) simple one line
"^" represents the start point before "f "
"$" represents the end point after "e "
2) Multiple lines
"^" represents 2 start points , first one before "f ", 2nd one between "\n\r" and "r"
"$" represents 2 end points , first one between "e " and "\n\r"
3) Practice in Java 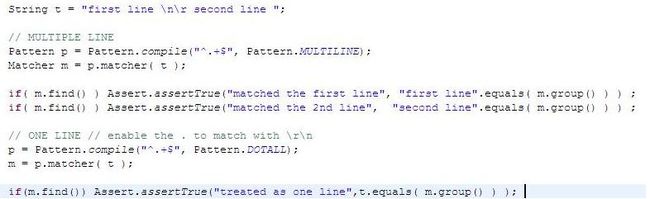
The Matching Mode
1. "/i" -- ignore cases
2. "/s" -- activate the single line mode
3. "/" -- activate the multiple line mode
4. how to activate the modes in the regex expression
insert the mode expression into your regex expression, then it start to activate from where you specified. "(?i)" -- ignore cases; "(?-i)" -- not ignore cases
Example
regex "(?i)te(?-i)st " matched with "TEst" but not matched with "TEST" or "teST".
Word Boundary Charset
1. Notion
"\b " represents the Word Boundary anchor
Three places specified as the Word Boundaries,
a. The beginning point of one character string
b. The ending point of one character string
c. The point between un-word character and word character, the un-word character just right after the word character or just before it
2. Example
"\b4\b" can matches " 4 " but can not matches " 44 ".
Selector Charset
1. Notion
"|", Uses the selector to match one of the possiblities.
The Selector has the lowest priority, it told regex machine that to matched the left one or right one.
2. Example
If you want to match a character string with "cat" or "dog", you can use "cat|dog"
If you want to match a word only with "cat" or "dot", "\b(cat|dog)\b"
3. The Greeding quantifiers and how to manipulation
(also, "()" is specified as the group will be mentioned later)
Suppose we have String Character "get getValue set setValue",
a. regex "\b(set|setValue)\b" , regex machine will return "set " first cause the Greeding feature.
The problem is that we want to find the best one "setValue "
b. so we can easily exchange the order like this "\b(setValue|set)\b"
But the writting style not so good
4. "()" to indentify one regex - ( "()" indicated as Group will be mentioned later )
"()" - tell the regex machine to treat it as a individual regex expression
so the example shows in #3 can be simply changed as "\bset(Value){1}\b"
a. (Value) will be treated as one individual regex expression
b. {1} indicates that must matches it one time.
----> So we have the best match.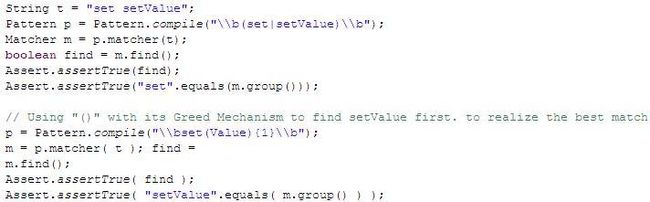
Group and its Backward Reference
1. Group
A charsets surrounding by "()" formula indicates this is a Group.
- Regex Machine will caches the matched results according with the pattern expression in "()"
- In the first one "() " we call it as first group, so in the second one "() " we call it as 2nd group..
- If want to reference the results cached, using "\1 " refer to the result of 1st group, so as "\2 ".
- Focus that, "\0 " reference itself - the entire orignial regex expression
- "?:" indicate that not to cache the Group value for backward reference. such as "set(?:Value)"
2. Example
Example-1:
Assume that we have character string "<B>This is a test</B>"
what we needed is to find out the contents of each Note
Clues:
1) regex pattern expression "<([A-Z]+?)>.*</\\1>"
2) "([A-z]+?)" as the first group --- ( The group value is "B " after matched )
3) "\\1" specified as a group reference index to reference the result of Group 1 "B "
4) Finally, "<([A-Z]+?)>.*</\\1>" converted as "<B>.*</B>". 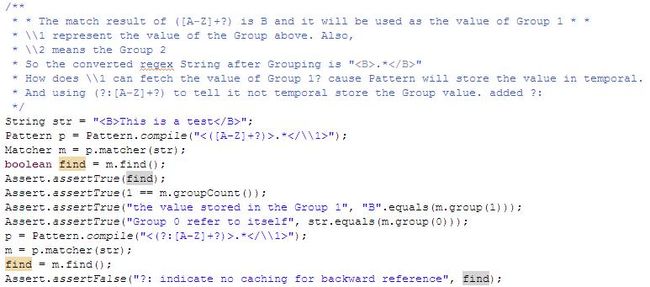
Example-2
To remove the repeative words for the careless typing.
Suppose that we have character string "the the world is beautiful"
clues:
1) Regex string "\b(\w+)\b\s+\b\1\b "
2) then we can use some replacement strategy to replace the matched contents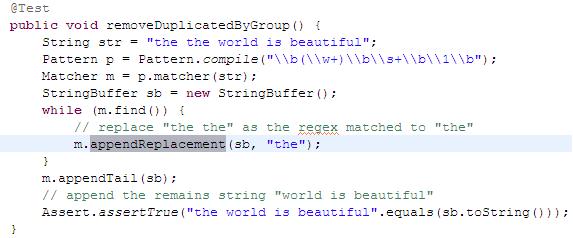
3. Cache Strategy
Cache Strategy - The temporal memory of regex machine only store the latest matched one for one Group
1) "([abc]+)=\1 " will match "cab=cab"
2) "([abc])+=\1 " not match "cab=cab" but matched with "cab=b", cause the latest matched for Group 1 ([abc])+ is "b ".
Meta-Group and Avoding the Backtrace
In some special situation, the Backtrace might leads to the performance disasters of the regex mechine, furture more, it may crash the regex matchine -- So we need to avoiding backtrace by Meta-Group
... in progress
Looking forward/backward
Focus - Javascript only support Looking forward
1. Affirmably/Negatively forward looking
Syntax
Affirmably forward looking - " (?=)"
Negatively forward looking - "(?!)"
Example
Negatively forward looking
we want to check that there is no character "u" right follows up character "q"
So the regex expression like "q(?!=u)"
---- So the same with Affirmably forward looking
Furture understood
Forward looking will not cache the matched results for backward references, but if you want the backward references, using "(?=(regex) )"
2. Affirmably/Negatively backward looking
Syntax
Affirmably backward looking - "(?=<)"
Negatively backward looking - "(?!<)"
( Additonly <> arrouding the value than forward looking )
Example
3. Deeply into forward/backward looking
..... in progress
Reference Links
CSDN: http://dragon.cnblogs.com/archive/2006/05/08/394078.html