用户态多线程实现的基本原理
本文参考了用户态非抢占式线程库实现 一文以及GNU Pth 。前者是一种用户态线程库的简单实现,属于一个很好的demo,后者就是大家熟知的Pthread的用户态实现,比较完善。
Keywords: User-Space MultiThreading, Pth
所谓多线程,简单讲就是能够让几个不同的代码片段轮流执行。内核实现多线程的方法比较直观,在每次时钟中断到来时或者用户调用syscall陷入内核时进行上下文切换即可。用户态切换线程要解决两个问题:
1、时机,即何时切换线程?
2、方法,即怎样切换上下文?
为了决定切换时机,需要确定所设计的线程库是可剥夺(preemptive)的还是不可剥夺(non-preemptive)的。一般,用户态线程库都选择使用不可剥夺的设计方案,这么做的好处是将控制权交给用户,而用户最了解何时需要放弃执行权。这么做减少了系统切换次数,实现了最高的CPU利用率,非常适合用于科学计算环境。但是,另一方面这么做也存在缺点:其它线程的响应速度变慢,他们必须等到当前CPU放弃执行权后才能被执行。能不能将用户线程设计成可剥夺的呢?这应该也是可行的。每个用户线程运行一段时间后会被迫暂停执行,被动地将控制权交回给调度器。怎样才能“被迫暂停执行”?这是方法问题,下面就要讲到。
对于不可剥夺方式,需要用户编写程序的时候主动调用诸如thread_yeild(), thread_wai()之类的函数,这些函数会将当前用户线程的执行上下文保存起来,然后让调度器选择一个新的用户线程投入执行。底层操作系统提供了一些列的机制支持上下文的获得和切换,如setjmp,longjmp,getcontext,swapcontext等。用户态非抢占式线程库实现 一文使用了前面两个函数,GNU Pth 使用了后面两个函数。可剥夺方式的实现需要更多的操作系统支持,如可以利用alarm函数周期性地产生用户态中断,每次中断到来的时候线程库进行线程切换。
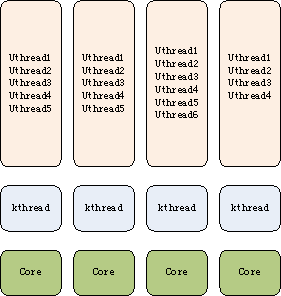
单纯的用户态线程库一般都是基于一个单线程进程实现的,一旦用户线程阻塞,这个进程就被阻塞,进而导致整个用户态线程组得不到CPU。基于单进程实现的用户态线程库在SMP/多CPU环境下性能很差,多出来的核无法被线程库利用,这跟当前的微处理器架构发展趋势十分不符。为了解决这个问题,可以考虑使用一种混合结构:在少量内核线程的基础上实现大量的用户线程。
最后思考一个问题:为什么用户态线程库比内核态线程库具有更高的性能呢?其实用户态线程库同样离不开进入内核态这一过程,以getcontext,swapcontex实现方式为例,getcontext要进出一次内核,swapcontex又要进出一次内核,而内核线程切换则只需要一次时钟中断,只进出内核一次即可。这么说来,用户态线程库的性能应该劣于内核态线程库。但是,注意到每次时钟中断所做的工作远远不止上下文切换这么简单,这应该是用户态线程库更优的原因吧。基于这个分析,如果应用需要创建的线程数并不多,二者应该性能相当。但是,一旦线程数巨大且切换频繁,用户态线程库的优势就能体现出来了。