本文为原创,转载请注明出处
1、两种自旋锁的实现:TAS和TTAS
1.1 TAS
class TasLock {
AtomicBoolean state = new AtomicBoolean(false);
void lock() {
while (state.getAndSet(true)) {
}
}
void unLock() {
state.set(false);
}
}
AtomicBoolean的getAndSet方法是原子的,TAS循环执行getAndSet方法,当发现原来的值为false,且设置新值为true成功后,则认为获取到了锁。
1.2 TTAS
class TtasLock{
AtomicBoolean state = new AtomicBoolean(false);
void lock() {
while(true){
while(state.get()){}
if(!state.getAndSet(true)){
return;
}
}
}
void unLock() {
state.set(false);
}
}
TTAS与TAS在功能的正确性上是一致的,但在实现手法上的区别在于,TTAS首先循环调用state.get()方法,只有当返回结果为false,即此时该锁还没有被其他线程占有时,才会再去调用getAndSet去获取锁
2、两种自旋锁的性能比较
基于TAS和TTAS设计锁,然后用多线程(10线程并发)累加一个公共的计数器。
public class MyTest {
//并发线程数
private final static int NTHREAD = 10;
//计数
private static volatile int count = 0;
//最大计数
private final static int MAX = 100000000;
//TAS锁
private static TASLock lock = new TASLock();
//TTAS锁
//private static TTASLock lock = new TTASLock();
public static void main(String[] args) throws InterruptedException {
final CountDownLatch endGate = new CountDownLatch(1);
final CountDownLatch startGate = new CountDownLatch(1);
ExecutorService e = Executors.newFixedThreadPool(NTHREAD);
for (int i = 0; i < NTHREAD; i++) {
e.execute(new Runnable() {
@Override
public void run() {
try {
startGate.await();
while (true) {
lock.lock();
if (count < MAX) {
count++;
lock.unLock();
continue;
}
lock.unLock();
break;
}
endGate.countDown();
} catch (InterruptedException ignored) {
}
}
});
}
long start = System.currentTimeMillis();
startGate.countDown();
endGate.await();
long end = System.currentTimeMillis();
long time = end - start;
e.shutdown();
System.out.print(time);
}
} 说明:采用了闭锁CountDownLatch,以便让10个并发线程同时开始计数
在我的机器上(4核)运行多次,统计得到的大致结果对比如下:
|
|
第一次 |
第二次 |
第三次 |
第四次 |
第五次 |
平均耗时(ms) |
| TAS |
27473 |
28288 |
28288 |
26151 |
26595 |
27359 |
| TTAS |
25587 |
26115 |
26115 |
26063 |
25182 |
25812.4 |
| 单线程 |
1594 |
1598 |
1592 |
1601 |
1597 |
1596.4 |
分析:
可以看出无论是TAS还是TTAS,性能均远远差于单线程的版本,这是合理的,因为并行是否能带来性能的提升,关键取决于执行的任务中串行任务所占的比例。而本例中,由于锁的存在,使得串行所占整个任务的比例为100%,因此即使线程再多,也只能串行执行,而多线程带来的上下文切换又会消耗一定的时间,所以多线程的性能更差。
但是,为什么TTAS会比TAS的性能要好呢?TTAS是循环执行state.get()方法,TAS是循环执行state.getAndSet(true)方法,这两种实现手法带来的本质区别是什么?要解释这一点,就必须先了解现代多处理器的缓存架构
3、现代多处理器缓存架构
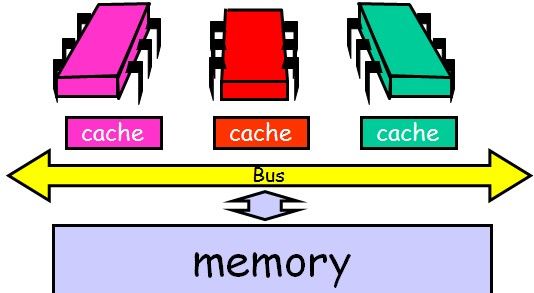
所有的处理器共享一个主存(memory),主存的访问速度很慢,需要消耗50~100个cycles,每个处理器都需要通过同一个bus同memory和其他处理器通信,而同一时刻只允许一个处理器通过bus发送消息(但memory和所有的处理器都能同时监听过bus的消息)。由于memory访问速度慢,而且还可能会等待,所以每个处理器都有自己的局部缓存(cache)。cache的访问速度很快,只需要消耗1~2个cycles,而且不会出现等待。
MESI协议将Cache line分为四种状态:
Modified:该cache line已经被修改,且只被一个处理器的cache缓存,最终必须写回主存;
Exclusive:该cache line 只被一个处理器的cache缓存,未被修改,与主存中的数据一致。
Shared:该cache line被多个处理器的cache缓存,未被修改,与主存中的数据一致
Invalid:该cache line已经失效
下面以一个图例解释MESI协议的执行:
a) 处理器A在bus上发出读取地址a处的数据的消息。由于只有主存有该数据,所以主存监听到该消息后,将地址a处的数据给处理器A,处理器A将数据缓存到自己的cache中,cache line的状态为Exclusive;
b) 处理器B在bus上发出读取同样地址a处的数据,处理器A监听到了该消息,将之前缓存的地址a处的数据给处理器B。此时,cache line的状态都变为Shared;
c) 处理器B修改地址a处的数据,将自己cache中的cache line的状态修改为Modified。同时,在bus上发出地址a处的数据被修改的消息,处理器A监听到该消息,将自己cache中cache line的状态修改为Invalid;
d) 处理器A在bus上发出重新读取地址a处的数据的消息,处理器B监听到该消息后,将修改后的数据同时发给处理器A和主存。处理器A和B的cache中的cache line的状态都变为Shared。
4、TTAS为什么比TAS要快
在TAS中,每次执行锁的getAndSet(true)方法,会独占bus以发送锁的state变量被修改的消息,导致其他处理器执行getAndSet(true)时都需要等待,出现了串行。更重要的是,有可能此时占有锁的处理器正准备执行set(false)方法以释放锁,但由于bus一直被执行getAndSet(true)方法的处理器占用着,导致释放锁也被延迟。
而在TTAS中,只有当get()方法返回false的情况下,才会执行getAndSet(true)方法。只要state没有被修改,处理器都在各自的cache中局部自旋着,不会占用bus,因此不会造成锁的释放被延迟。
当然,TTAS也不是最完美的,当处理器释放锁执行set(false)方法后,所有其他处理器的cache都会被失效,无法再继续局部自旋,调用get()方法都会占用bus,出现串行。当get()方法返回false后,此时,可能就会有多个处理器正试图同时执行getAndSet(true)方法,又导致了和TAS一样的情况出现。这一轮过后,各处理器又会在各自的cache中局部自旋,直到锁再次被释放。
现在的问题焦点是:只要执行了一次无效的getAndSet(true)方法,都会导致所有处理器的cache被失效,失效后get()方法的调用就会占用bus,有可能导致处理器释放锁被延迟。如果能降低无效的调用次数,则能提升TTAS的速度。假设在第一轮中,有3个处理器同时执行getAndSet(true)方法,那么只有一个处理器能够获取到锁,另外的两个处理器又会重新恢复到TTAS的局部自旋中。当第一个处理器将锁释放后,这两个处理器又可能会同时执行getAndSet(true)方法,那么不可避免的又会存在一个处理器执行一次无效的getAndSet(true)方法调用。如果每个处理器在每次执行无效的getAndSet(true)方法调用后,都休眠一段随机的时间,再进入到TTAS的局部自旋中,则多个处理器同时执行getAndSet(true)方法调用的概率就能被降低。