Lucene + Hadoop
转 http://xuezhongfeicn.blog.163.com/blog/static/2246014120112383545321/
1、概述
不管程序性能有多高,机器处理能力有多强,都会有其极限。能够快速方便的横向与纵向扩展是Nut设计最重要的原则,以此原则形成以分布式并行计算为核心的架构设计。以分布式并行计算为核心的架构设计是Nut区别于Solr、Katta的地方。
Nut是一个Lucene+Hadoop分布式并行计算搜索框架,能对千G以上索引提供7*24小时搜索服务。在服务器资源足够的情况下能达到每秒处理100万次的搜索请求。
Nut开发环境:jdk1.6.0.23+lucene3.0.3+eclipse3.6.1+hadoop0.20.2+zookeeper3.3.2+hbase0.20.6+memcached+mongodb+linux
2、特新
a、热插拔
b、可扩展
c、高负载
d、易使用,与现有项目无缝集成
e、支持排序
f、7*24服务
g、失败转移
3、搜索流程
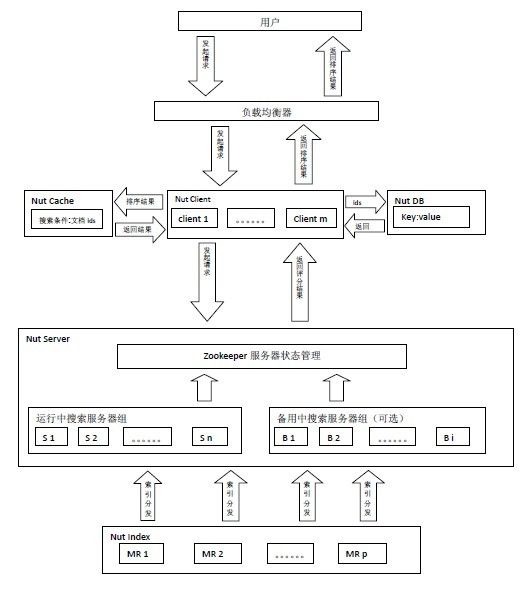
Nut由Index、Search、Client、Cache和DB五部分构成。(Cache实现了对memcached的支持,DB实现了对hbase,mongodb的支持)
Client处理用户请求和对搜索结果排序。Search对请求进行搜索,Search上只放索引,数据存储在DB中,Nut将索引和存储分离。 Cache缓存的是搜索条件和结果文档id。DB存储着数据,Client根据搜索排序结果,取出当前页中的文档id从DB上读取数据。
用 户发起搜索请求给由Nut Client构成的集群,由某个Nut Client根据搜索条件查询Cache服务器是否有该缓存,如果有缓存根据缓存的文档id直接从DB读取数据,如果没有缓存将随机选择一组搜索服务器组 (Search Group i),将查询条件同时发给该组搜索服务器组里的n台搜索服务器,搜索服务器将搜索结果返回给Nut Client由其排序,取出当前页文档id,将搜索条件和当前文档id缓存,同时从DB读取数据。
4、索引流程
Hadoop Mapper/Reducer 建立索引。再将索引从HDFS分发到各个索引服务器。
对索引的更新分为两种:删除和添加(更新分解为删除和添加)。
a、删除
在HDFS上删除索引,将生成的*.del文件分发到所有的索引服务器上去或者对HDFS索引目录删除索引再分发到对应的索引服务器上去。
b、添加
新添加的数据用另一台服务器来生成。
删除和添加步骤可按不同定时策略来实现。
5、Nut分布式并行计算特点
Nut分布式并行计算虽然也是基于M/R模型,但是与Hadoop M/R模型是不同的。在Hadoop M/R模型中 Mapper和Reducer是一个完整的流程,Reducer依赖于Mapper。数据源通过Mapper分发本身就会消耗大量的I/O,并且是消耗I /O最大的部分。所以Hadoop M/R 并发是有限的。
Nut M/R模型是将Mapper和Reducer分离,各自独立存在。在Nut中 索引以及索引管理 构成M,搜索以及搜索服务器组 构成 R。
以一个分类统计来说明Nut分布式并行计算的流程。假设有10个分类,对任意关键词搜索要求统计出该关键词在这10个分类中的总数。同时假设有10组搜索 服务器。索引以及索引管理进行索引数据的Mapper,这块是后台独自运行管理的。Nut Client将这10个分类统计分发到10组搜索服务器上,每组搜索服务器对其中一个分类进行Reducer,并且每组搜索服务器可进行多级 Reducer。最后将最终结果返回给Nut Client。
6、设计图

7、Zookeeper服务器状态管理策略

在架构设计上通过使用多组搜索服务器可以支持每秒处理100万个搜索请求。
每组搜索服务器能处理的搜索请求数在1万—1万5千之间。如果使用100组搜索服务器,理论上每秒可处理100万个搜索请求。
假如每组搜索服务器有100份索引放在100台正在运行中搜索服务器(run)上,那么将索引按照如下的方式放在备用中搜索服务器(bak) 上:index 1,index 2,index 3,index 4,index 5,index 6,index 7,index 8,index 9,index 10放在B 1 上,index 6,index 7,index 8,index 9,index 10,index 11,index 12,index 13,index 14,index 15放在B 2上。。。。。。index 96,index 97,index 98,index 99,index 100,index 5,index 4,index 3,index 2,index 1放在最后一台备用搜索服务器上。那么每份索引会存在3台机器中(1份正在运行中,2份备份中)。
尽管这样设计每份索引会存在3台机器中,仍然不是绝对安全的。假如运行中的index 1,index 2,index 3同时宕机的话,那么就会有一份索引搜索服务无法正确启用。这样设计,作者认为是在安全性和机器资源两者之间一个比较适合的方案。
备用中的搜索服务器会定时检查运行中搜索服务器的状态。一旦发现与自己索引对应的服务器宕机就会向lock申请分布式锁,得到分布式锁的服务器就将自己加入到运行中搜索服务器组,同时从备用搜索服务器组中删除自己,并停止运行中搜索服务器检查服务。
为能够更快速的得到搜索结果,设计上将搜索服务器分优先等级。通常是将最新的数据放在一台或几台内存搜索服务器上。通常情况下前几页数据能在这几台搜索服务器里搜索到。如果在这几台搜索服务器上没有数据时再向其他旧数据搜索服务器上搜索。
优先搜索等级的逻辑是这样的:9最大为搜索全部服务器并且9不能作为level标识。当搜索等级level为1,搜索优先级为1的服务器,当level为2时搜索优先级为1和2的服务器,依此类推。
![]() 2010年12月29日
2010年12月29日
PDF文档下载
一、 概述
在网页抓取项目中通常最缺的是IP地址资源,大多数网站对抓取会做些限制(比如同一IP地址的线程数限制,再比如几分钟之内同一IP地址的页面访问次数限制)。
基于P2P模式的分布式抓取方案是利用分散在各处的可上网机器来抓取网页,可有效的突破网站限制。
二、设计图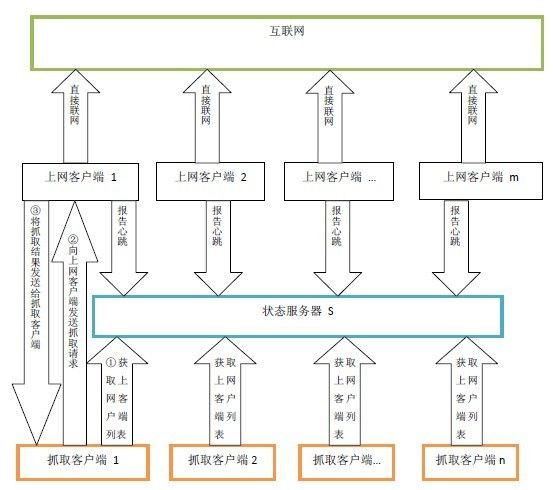
上网客户端1 。。。上网客户端m是分散在各处能直接上网的机器,这些上网客户端机器定时向状态服务区报告自己的心跳。
抓取客户端 1 。。。抓取客户端 n 是集中放在某处的抓取机器。抓取客户端机器定时向状态服务器获取可用上网客户端列表,然后抓取客户端机器直接与上网客户端建立连接,抓取客户端机器直接通过上网客户端来抓取网页。
三、实现方案
方案一:
在上网客户端机器上安装共享上网代理软件比如ccproxy,抓取客户端以代理的方式通过上网机器抓取网页。该方案简单易行,无技术障碍。
方案二:
开发一套简化版P2P软件,抓取客户端机器将抓取请求分发给客户端机器,客户端机器将网页抓取下来传回给抓取客户端机器。该方案复杂些,但可扩展性极强。在掌握了大量上网客户端机器后完全可以做成云计算进行商业运作。
![]() 2010年11月17日
2010年11月17日
http://www.blogjava.net/nianzai/
http://code.google.com/p/nutla/
一、安装
1、 安装虚拟机 vmware6.5.2
2、 在虚拟机下安装Linux Fedora14
3、 安装jdk jdk-6u22-linux-i586.bin 安装路径为:/home/nianzai/jdk1.6.0_22
4、 安装hadoop hadoop-0.20.2.tar.gz 安装路径为:/home/nianzai/hadoop-0.20.2
5、 安装zookeeper zookeeper-3.3.1.tar.gz 安装路径为:/home/nianzai/zookeeper-3.3.1
6、 安装hbase hbase-0.20.6.tar.gz 安装路径为:/home/nianzai/hbase-0.20.6
二、配置
1、Linux配置
ssh-keygen –t rsa -P ''
cd .ssh
cp id_rsa.pub authorized_keys
/etc/hosts里增加 192.168.195.128 nz 并且将127.0.0.1 改为 192.168.195.128
2、hadoop配置
hadoop-env.sh
JAVA_HOME=/home/nianzai/jdk1.6.0._22
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-nianzai</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://nz:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>nz:9001</value>
</property>
</configuration>
sh hadoop namenode -format
sh start-all.sh
sh hadoop fs -mkdir input
3、zookeeper配置
zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/nianzai/zkdata
clientPort=2181
sh zkServer.sh start
4、hbase配置
hbase-env.sh
export JAVA_HOME=/home/nianzai/jdk1.6.0_22
export HBASE_MANAGES_ZK=false
hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://nz:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>nz</value>
</property>
</configuration>
regionservers
nz
sh start-hbase.sh
![]() 2010年10月27日
2010年10月27日
http://code.google.com/p/nutla/
1、概述
不管程序性能有多高,机器处理能力有多强,都会有其极限。能够快速方便的横向与纵向扩展是Nut设计最重要的原则。
Nut是一个Lucene+Hadoop分布式搜索框架,能对千G以上索引提供7*24小时搜索服务。在服务器资源足够的情况下能达到每秒处理100万次的搜索请求。
Nut开发环境:jdk1.6.0.21+lucene3.0.2+eclipse3.6.1+hadoop0.20.2+zookeeper3.3.1+hbase0.20.6+memcached+linux
2、特新
a、热插拔
b、可扩展
c、高负载
d、易使用,与现有项目无缝集成
e、支持排序
f、7*24服务
g、失败转移
3、搜索流程
Nut由Index、Search、Client、Cache和DB五部分构成。(Cache默认使用memcached,DB默认使用hbase)
Client处理用户请求和对搜索结果排序。Search对请求进行搜索,Search上只放索引,数据存储在DB中,Nut将索引和存储分离。 Cache缓存的是搜索条件和结果文档id。DB存储着数据,Client根据搜索排序结果,取出当前页中的文档id从DB上读取数据。
用 户发起搜索请求给由Nut Client构成的集群,由某个Nut Client根据搜索条件查询Cache服务器是否有该缓存,如果有缓存根据缓存的文档id直接从DB读取数据,如果没有缓存将随机选择一组搜索服务器组 (Search Group i),将查询条件同时发给该组搜索服务器组里的n台搜索服务器,搜索服务器将搜索结果返回给Nut Client由其排序,取出当前页文档id,将搜索条件和当前文档id缓存,同时从DB读取数据。
4、索引流程
Hadoop Mapper/Reducer 建立索引。再将索引从HDFS分发到各个索引服务器。
对索引的更新分为两种:删除和添加(更新分解为删除和添加)。
a、删除
在HDFS上删除索引,将生成的*.del文件分发到所有的索引服务器上去或者对HDFS索引目录删除索引再分发到对应的索引服务器上去。
b、添加
新添加的数据用另一台服务器来生成。
删除和添加步骤可按不同定时策略来实现。
5、Zookeeper服务器状态管理策略
在架构设计上通过使用多组搜索服务器可以支持每秒处理100万个搜索请求。
每组搜索服务器能处理的搜索请求数在1万—1万5千之间。如果使用100组搜索服务器,理论上每秒可处理100万个搜索请求。
假如每组搜索服务器有100份索引放在100台正在运行中搜索服务器(run)上,那么将索引按照如下的方式放在备用中搜索服务器(bak) 上:index 1,index 2,index 3,index 4,index 5,index 6,index 7,index 8,index 9,index 10放在B 1 上,index 6,index 7,index 8,index 9,index 10,index 11,index 12,index 13,index 14,index 15放在B 2上。。。。。。index 96,index 97,index 98,index 99,index 100,index 5,index 4,index 3,index 2,index 1放在最后一台备用搜索服务器上。那么每份索引会存在3台机器中(1份正在运行中,2份备份中)。
尽管这样设计每份索引会存在3台机器中,仍然不是绝对安全的。假如运行中的index 1,index 2,index 3同时宕机的话,那么就会有一份索引搜索服务无法正确启用。这样设计,作者认为是在安全性和机器资源两者之间一个比较适合的方案。
备用中的搜索服务器会定时检查运行中搜索服务器的状态。一旦发现与自己索引对应的服务器宕机就会向lock申请分布式锁,得到分布式锁的服务器就将自己加入到运行中搜索服务器组,同时从备用搜索服务器组中删除自己,并停止运行中搜索服务器检查服务。
为能够更快速的得到搜索结果,设计上将搜索服务器分优先等级。通常是将最新的数据放在一台或几台内存搜索服务器上。通常情况下前几页数据能在这几台搜索服务器里搜索到。如果在这几台搜索服务器上没有数据时再向其他旧数据搜索服务器上搜索。
优先搜索等级的逻辑是这样的:9最大为搜索全部服务器并且9不能作为level标识。当搜索等级level为1,搜索优先级为1的服务器,当level为2时搜索优先级为1和2的服务器,依此类推。
![]() 2010年9月25日
2010年9月25日
http://code.google.com/p/nutla/
1、概述
只为lucene提供分布式搜索框架。7*24千G以上索引文件支持数千万级的用户搜索访问。
Nut开发环境:jdk1.6.0.21+lucene3.0.2+eclipse3.6+hadoop0.20.2+zookeeper3.3.1+linux
2、特新
a、热插拔
b、可扩展
c、高负载
d、易使用,与现有项目无缝集成
e、支持排序
f、7*24服务
g、失败转移
3、搜索流程
Nut由Index、Search、Client、Cache和DB五部分构成。
Client处理用户请求和对搜索结果排序。Search对请求进行搜索,Search上只放索引,数据存储在DB中,Nut将索引和存储分离。 Cache缓存的是搜索条件和结果文档id。DB存储着数据,Client根据搜索排序结果,取出当前页中的文档id从DB上读取数据。
用 户发起搜索请求给由Nut Client构成的集群,由某个Nut Client根据搜索条件查询Cache服务器是否有该缓存,如果有缓存根据缓存的文档id直接从DB读取数据,如果没有缓存将查询条件同时发给后面的n 台搜索服务器,搜索服务器将搜索结果返回给Nut Client由其排序,取出当前页文档id,将搜索条件和当前文档id缓存,同时从DB读取数据。
4、索引流程
Hadoop Mapper/Reducer 建立索引。再将索引从HDFS分发到各个索引服务器。
对索引的更新分为两种:删除和添加(更新分解为删除和添加)。
a、删除
在HDFS上删除索引,将生成的*.del文件分发到所有的索引服务器上去或者对HDFS索引目录删除索引再分发到对应的索引服务器上去。
b、添加
新添加的数据用另一台服务器来生成。
删除和添加步骤可按不同定时策略来实现。
5、Zookeeper服务器状态管理策略

假如我们有100份索引放在100台正在运行中搜索服务器上,那么将索引按照如下的方式放在备用中搜索服务器上:index 1,index 2,index 3,index 4,index 5,index 6,index 7,index 8,index 9,index 10放在B 1 上,index 6,index 7,index 8,index 9,index 10,index 11,index 12,index 13,index 14,index 15放在B 2上。。。。。。index 96,index 97,index 98,index 99,index 100,index 5,index 4,index 3,index 2,index 1放在最后一台备用搜索服务器上。那么每份索引会存在3台机器中(1份正在运行中,2份备份中)。
尽管这样设计每份索引会存在3台机器中,仍然不是绝对安全的。假如运行中的index 1,index 2,index 3同时宕机的话,那么就会有一份索引搜索服务无法正确启用。那么这样设计,作者认为是在安全性和机器资源两者之间一个比较适合的方案。
备用中的搜索服务器会定时检查运行中搜索服务器的状态。一旦发现与自己索引对应的服务器宕机就会先向zookeeper申请分布式锁,得到锁的服务器就将自己加入到运行中搜索服务器组,同时从备用搜索服务器组中删除自己,并停止运行中搜索服务器检查服务。