SEDA性能优化的分析和模拟
内容出自: http://www.iteye.com/topic/432134
在学习Mule的过程中,发现MULE对于服务调用的性能做了不少优化工作,其中最显著的就是实现SEDA模型。
Staged Event Driven Architecture (SEDA) 是加州大学伯克利分校研究的一套优秀的高性能互联网服务器架构模型。其设计目标是:支持大规模并发处理、简化系统开发、支持处理监测、支持系统资源管理。它的核心思想是把一个请求处理过程分成几个Stage,不同资源消耗的Stage使用不同数量的线程来处理,Stage间使用事件驱动的异步通信模式。
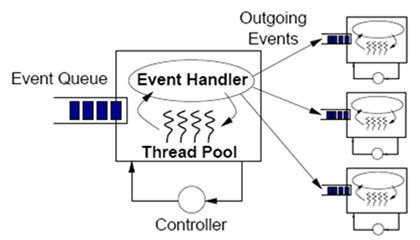
可以参考
http://www.eecs.harvard.edu/~mdw/papers/seda-sosp01.pdf
http://larryzhu.bokee.com/6779982.html
http://www.ibm.com/developerworks/cn/java/j-jtp0730/
这几篇文章对SEDA和线程池相关知识有着详细的介绍,这里就不复述了。
了解了SEDA后可以看出,经过它的改造,一个请求的处理过程被分为了很多个stage,并且使用了事件驱动的异步通信。接收到请求的最初始的线程所做的事情仅仅是将请求转换为一个event然后放入一个Stage的事件队列中。每个Stage都有自己的线程池,来处理事件队列中的事件。与另一个 stage的通信也是通过在eventQueue中添加event的方式。
为什么要做此改造?
可以分析下面这个例子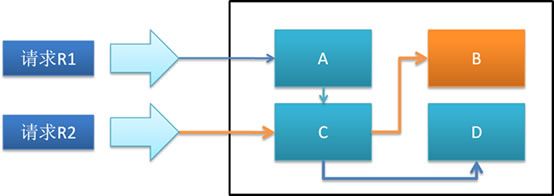
前提假设:在一个单核系统中存在A、B、C、D四个组件,他们向外暴露服务。四个组件中A C D是进行普通业务处理,而B会涉及到调用WebService或大数据量查询等导致长阻塞的处理。现有两个请求R1和R2,R1需要的业务处理会调用A- C-D组件,R2的业务处理会调用C-B组件。假设R1请求过程中的CPU使用时间ST(Service Time)是2ms, 而几个简单的数据库访问导致的阻塞时间WT(Wait Time)是10ms。 R2请求过程中CPU使用时间ST是3ms,而调用WebService和大数据量查询导致的阻塞时间WT是150ms。
在传统线程池的方案中,对于具有N个处理器的系统,需要设置大约 N*(1+WT/ST) 个线程来保持处理器得到充分利用。理解起来很简单,就是需要在WT的阻塞时间内提供足够的线程来保持CPU一直进行ST的处理,达到最大的CPU利用率。
通过计算可以得到,R1需要的线程池大小是6,R2需要的线程池大小是51。若仅仅在接收请求时使用传统的线程池方案,R1、R2两种请求同时高并发时,线程池对他们一视同仁,假设线程池的大小是80,而并发数是1000,按照公平的假设,80大小的线程池平均的被分配给R1和R2两种请求,各拿 40。这样导致的结果就是,R1只需要6个线程却被分配了40个线程,浪费了资源,增加了额外的调度工作;R2需要51个线程却只分配了40个,会导致 40个线程全部阻塞时没有足够新线程处理其他的并发请求,CPU没有充分利用,请求处理速度下降,系统吞吐量下降。
这里的数字全部是假设,仅供分析。事实情况下的并发数和线程池都会大很多,但上面分析得出的结论同样适用。
不难看出解决上面问题的方法就是能够为不同的请求分配不同的线程数量。但是一个请求会交给多个组件进行处理,组件的调用关系和请求的数量种类都会不断变化,所以不可能静态的为每个请求配置线程池大小。但是组件却可以,系统中ABCD四个组件是可以确定的,他们的WT和ST也是可估的,可以为每个组件的服务设计线程池大小。若要为每个组件设计线程池,组件间的调用也需要由同一线程内的同步调用,改造为事件驱动的异步通信方式。
于是,SEDA的方案被设计出来了。上面的组件对应的就是SEDA中的一个个阶段stage。分阶段的事件驱动架构的原理也展现在眼前。
实际演练
在分析了SEDA的原理和作用后,我模拟了他最简单的功能,实现了一个简单的SEDA模型,并进行了一些实验和比较,亲身体验到了他对性能的优化。下面是实验过程:
首先,实现一个简单的SEDA模型以及测试器,见附件的 SedaTester.java和seda.properties,分别是模拟代码和相关参数的配置文件。为了方便,我将功能代码写在了同一个类中。
代码中有详细的注释,这里就不解释了,简单介绍一下它的结构和配置参数: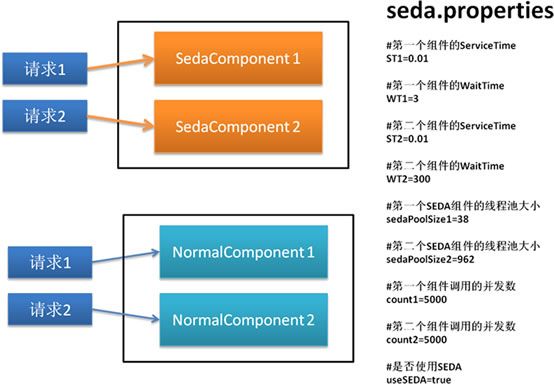
模拟器实现了两种并发处理,包括传统的线程池处理,对应图中NormalComponent部分,以及SEDA方案,对应图中SedaComponent部分。
此模拟器主要是为了测试性能上的优化,为了简化,没有设计组件之间事件驱动的异步通信,一个请求的处理过程只涉及到一个组件。不过它已经能体现出SEDA的优势——为不同的请求分配不同大小的线程池。
配置文件中,为两个请求对应的两个组件分别配置了ST和WT值,以及两个请求的并发数量,如果是使用SEDA,还要分别配置两个组件线程池的大小。 useSEDA这个boolean属性表示是否使用SEDA,不使用SEDA将使用普通的线程池进行处理,线程池的大小是两个SEDA组件线程池大小的和(sedaPoolSize1+sedaPoolSize2),这样能保证两种方案的线程总数一致。
下面是我个人的实验结果
| ST1 | WT1 | ST2 | WT2 | sedaPoolSize1 | sedaPoolSize2 | count1 | count2 | 结果 |
| 0.1 | 30 | 0.1 | 100 | 200 | 300 | 5000 | 5000 | Seda:1875ms
Normal:1690ms |
| 0.1 | 30 | 0.1 | 100 | 100 | 400 | 5000 | 5000 | Seda:1594ms
Normal:1656ms |
| 0.1 | 30 | 0.1 | 100 | 50 | 450 | 5000 | 5000 | Seda:3172ms
Normal:1656ms |
| 0.1 | 3 | 0.1 | 300 | 200 | 300 | 5000 | 5000 | Seda:5343ms
Normal:3453ms |
| 0.1 | 3 | 0.1 | 300 | 10 | 490 | 5000 | 5000 | Seda:3375ms
Normal:3410ms |
| 0.1 | 3 | 0.1 | 300 | 100 | 900 | 5000 | 5000 | Seda: 1968ms
Normal:3482ms |
| 0.1 | 3 | 0.1 | 300 | 38 | 962 | 5000 | 5000 | Seda: 1890ms
Normal:3422ms |
| 0.1 | 3 | 0.1 | 300 | 38 | 962 | 50000 | 50000 | Seda: 16107ms
Normal:17085ms |
| 0.01 | 3 | 0.01 | 300 | 38 | 962 | 50000 | 50000 | Seda: 15450ms
Normal:23430ms |
| 0.1 | 3 | 0.1 | 300 | 138 | 2962 | 30000 | 30000 | Seda: 3895ms
Normal: 65664 ms |
| 0.1 | 3 | 0.1 | 300 | 138 | 2962 | 300000 | 300000 | Seda: 31574ms
Normal:76412ms |
| 0.1 | 3 | 0.1 | 300 | 138 | 2962 | 300000 | 300000 | Seda: 31761ms
Normal:94426ms |
| 0.1 | 3 | 0.1 | 300 | 138 | 2962 | 300000 | 300000 | Seda: 31561ms
Normal:???? ms |
实验数据看似零乱,其实比较后不难发现,是按照两组件的WT比值、线程池大小比值的规律进行实验的。
结果分析:
1 在前几组数据中,SEDA的优势没有体现出来,原因可能是两个组件的WT相差不是很大,线程池和并发数量不大,不能体现出动态分配线程池的优化效果,相反会因为SEDA内部的线程管理和调度花费较多的时间,出现比传统线程池低效的结果。
2 在逐渐加大WT比值后,本来希望SEDA能体现优势,但是红色的数据显示了相反的情况,调整了线程池大小后发现红色数据中SEDA低效的原因是:两个组件线程池大小的比例不够大,只有200/300,而WT的比值是3/300,线程池大小的比值应该和WT的比值在某种程度成正比。当WT比值加大后,线程池的比值也需要加大调整。
3 逐渐好转后,到了橘黄色的数据已经比较明显的体现出了SEDA的优化,一方面是WT比值加大,两个线程池大小也调整到了较合适的比值,并且总的线程数量增大到1000,是原来的两倍,SEDA优化的效果开始体现。
4到了蓝色的数据,减少ST到0.01,并发增加到10万,SEDA比Normal缩短了8秒左右。
5 再下面的实验中,增加并发到了60万,线程池总数增加到3100,适当调整线程池比例后,SEDA已经能够缩短几十秒的时间。
特别是绿色标识的数据,优化的效果已经有点让我怀疑是不是我代码出了问题,是不是模拟器不能正确的测试出性能。这个也有待进一步确认。
6 最后一行数据之所以用四个问号来表示Normal的时间,是因为某几次实验过程中消耗的时间已经涨到200多秒而且还在不断继续上涨,不符合正常的预估。不知道是不是因为大并发和较大容量的时候,传统的线程池容易出现性能的异常。
总结一下,当不同请求的WT比值越悬殊、线程池大小越接近机器性能所允许的最大值、并发数量越满负荷、两个线程池大小的比值越合适时,就越能体现SEDA的优化效果。同时,必须根据某种算法,将两个组件的线程池大小调整到合适的比值(和WT的比值成正比),才能发挥SEDA的作用。否则,不合适的线程数目分配将严重折损SEDA的优化效果甚至产生反效果。