skipfish试用
一。简介
google的一款安全扫描工具,项目地址在http://code.google.com/p/skipfish/
A fully automated, active web application security reconnaissance tool. Key features: High speed: pure C code, highly optimized HTTP handling, minimal CPU footprint - easily achieving 2000 requests per second with responsive targets. Ease of use: heuristics to support a variety of quirky web frameworks and mixed-technology sites, with automatic learning capabilities, on-the-fly wordlist creation, and form autocompletion. Cutting-edge security logic: high quality, low false positive, differential security checks, capable of spotting a range of subtle flaws, including blind injection vectors. The tool is believed to support Linux, FreeBSD 7.0+, MacOS X, and Windows (Cygwin) environments.
目前只有在linux环境下的编译包,无windows支持。
二。安装过程:
下载tar包,解压,然后linux下make;make install
项目主页上就这么一句话:To compile it, simply unpack the archive and try make. Chances are, you will need to install libidn first.
但是实际要编译成功,问题多多!需要注意的问题:
1.项目同时依赖-lidn和-lssl,当然在编译ssl库的时候,还可能会出现另外的问题,google可以解决。
2.下载的tar包,makefile文件有严重的问题! 改为如下内容编译通过(特别要注意LIBS的顺序)
Makefile:
PROGNAME = skipfish
OBJFILES = http_client.c database.c crawler.c analysis.c report.c
INCFILES = alloc-inl.h string-inl.h debug.h types.h http_client.h \
database.h crawler.h analysis.h config.h report.h
CFLAGS_GEN = -Wall -funsigned-char -g -ggdb -I/usr/local/ssl/include/ -I/usr/local/include/ \
-I/opt/local/include/ $(CFLAGS) -D_FORTIFY_SOURCE=0
CFLAGS_DBG = -DLOG_STDERR=1 -DDEBUG_ALLOCATOR=1 $(CFLAGS_GEN)
CFLAGS_OPT = -O3 -Wno-format $(CFLAGS_GEN)
LDFLAGS += -L/usr/local/lib/ -L/opt/local/lib -L/home/weisong/clib/openssl-1.0.0a/
LIBS += -lidn -lz -ldl -L/home/weisong/clib/openssl-1.0.0a/ -lssl -lcrypto
另外一些常见的FAQ可以访问:http://code.google.com/p/skipfish/wiki/KnownIssues
我们要,字典准备好!因为它决定你扫描结果的质量!cd dictionaries进入这个目录 ,把其中的一个字典copy 到skipfish目录下面/,重新命名为:skipfish.wl
三。试用:
这个时候就可以扫描你想要扫描的站点 # ./skipfish -o output_dir http://www.google.com
然后在output_dir/index.html 查看结果即可!详细的用法大家可以
./skipfish –h 得到想要的帮助
./skipfish -o /home/weisong/out3 http://10.6.206.48:5001
扫描过程:
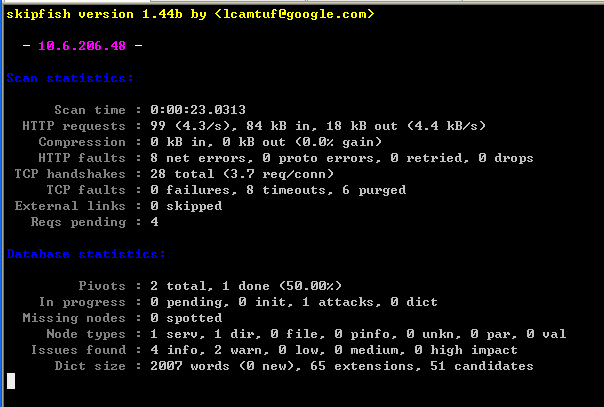
指定了网址的root目录之后,会自动向下遍历

扫描结果,会输出静态的html页面,google给出的示例截图如下:
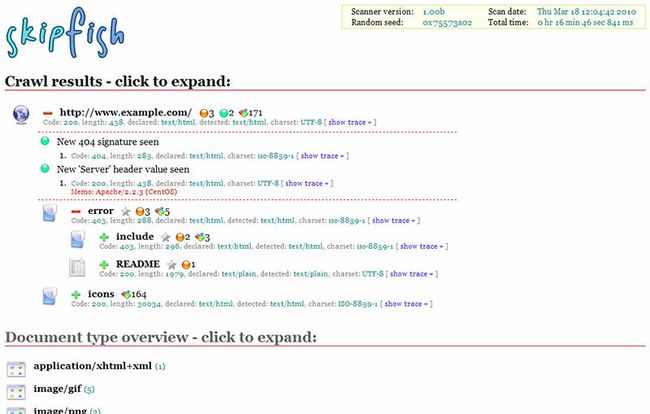
但是在我扫描了workproject之后,发现结果是空空如也,啥子都木有。
四。详细分析
在第2步骤中,我们使用了这个命令去扫描项目,但是skipfish如何去获取网站下面有哪些url呢?
./skipfish -o /home/weisong/out3 http://10.6.206.48:5001
这个时候就需要仔细阅读skipfish/dictionaries下面的README-FIRST文件了,因为这里定义到的扫描字典,直接决定了扫描的质量! 因为skipfish完全根据字典文件定义的wordlist去拼凑站点url。如果字典不能覆盖到自己的站点,那么就是徒劳了。
you should understand several basic concepts related to dictionary management in this scanner, as this topic is of critical importance to the quality of your scans.
在skipfish.wl文件中挑出几行,示例如下:
w 1 8 8 test123 w 1 8 8 torrent e 1 8 8 sh e 1 8 8 txt
在字典里面,其实就是按格式定义了一堆关键词文本,每个一行,格式如下:
type hits total_age last_age keyword
其中type有'e' 和 'w'两种,代表 (extension扩展名 or wordlist关键词)
hits代表“is the total number of times this keyword resulted in a non-404 hit in all previous scans”,不是特别理解,就贴原文了,skipfish.wl文件里面hits大多定义为1。猜它的意思是在导致404之前,该word的利用次数。
total_age代表“is the number of scan cycles this word is in the dictionary”,扫描的循环次数,说实话也不能特别理解。
last_age代表"is the number of scan cycles since the last 'hit'"
keyword 则是真正的关键单词
(要知道这个skipfish.wl文件是自学习的,会根据扫描结果自动添加wordlist,并更新hits,total_age,last_age 字段.所以看起来是3个统计字段,自己添加wordlist的时候全部写1即可)
到此知道为什么分析了本地站点得到的结果为空。于是自己将本站点struts2文件抓取,分析出所有actionname,添加到type-w,然后将xhtml的扩展名添加到type -e.从新进行扫描。
整个使用过程发现,skipfish真的只是一个小小的工具而已,称不上强大。单单是编译源码就比较困难,其次要自己构造字典文件,然后具体扫描中使用的策略和算法也不能在使用过程中得到体现。并且开发skipfish的两个程序员也说这个工具不属于一个真正符合安全扫描标准的工具。
到此打住。
补充
===============================
楼下有兄弟问Webgoat扫描的问题,这里做一个解答:
1.下载安装,我这里是WebGoat-5.2 版本,并且把server.xml中的Connector监听ip从127.0.0.1切换成对外ip,这样可以从其他机器来访问webgoat
2.skipfish使用default.wl字典,扫描命令如下:, 当然要不要指定d=5可以再做其他尝试
./skipfish -Aguest:guest -o outA -d5 http://10.6.206.48:8080/WebGoat/attack
3.扫描结果:
可以看到,是有找到漏洞的。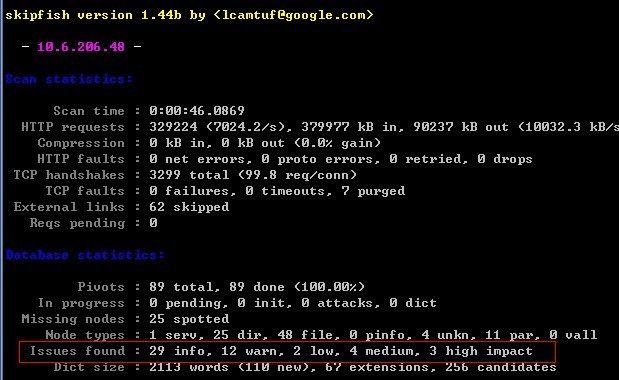
然后tar -cvf outA.tar outA/,把输出弄到本地来看,这里就出现陷阱了!!
使用chrome打开index页面,可能看到的输出结果会是空的。让人以为扫描失败。

但是,换ff,则可以看到这个结果:

具体原因,查看http://code.google.com/p/skipfish/wiki/KnownIssues pro 6#