一、 ik-analyzer分词
1、下载
“IK Analyzer 2012FF_hf1.zip”包: http://ik-analyzer.googlecode.com/files/IK%20Analyzer%202012FF_hf1.zip
源码: https://ik-analyzer.googlecode.com/files/IK%20Analyzer%202012FF_hf1_source.rar
官网:https://code.google.com/p/ik-analyzer/
2、源码拷入eclipse,添加IKTokenizerFactory类,拷贝出ext.dic、IKAnalyzer.cfg.xml、stopword.dic后删除, 打成ik-solr4.6.jar包。
自定义IKTokenizerFactory类 为了支持solr4.6可以加同义词,这个类写法参考: http://thinkjet.me/solr-lucene-tokenizer-filter.html
package org.wltea.analyzer.lucene;
import java.io.Reader;
import java.util.Map;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeSource.AttributeFactory;
public class IKTokenizerFactory extends TokenizerFactory{
private boolean useSmart;
public boolean useSmart() {
return useSmart;
}
public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
}
public IKTokenizerFactory(Map<String, String> args) {
super(args);
assureMatchVersion();
this.setUseSmart("true".equals(args.get("useSmart")));
}
@Override
public Tokenizer create(AttributeFactory factory, Reader input) {
Tokenizer _IKTokenizer = new IKTokenizer(input , this.useSmart);
return _IKTokenizer;
}
}
3、将ik-solr4.6.jar拷贝到tomcat/webapps/solr/WEB-INF/lib ,拷贝出的IKAnalyzer.cfg.xml、ext.dic、stopword.dic 放到 tomcat/webapps/solr/WEB-INF/classes目录(创建)
<!-- IKAnalyzer.cfg.xml-- >
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
<!--ext.dic-- >
荧光海滩
我爱中国
<!--stopword.dic-->
with
也
了
4、schema.xml添加配置
<field name="content" type="text_ik" indexed="true" stored="true" multiValued="false" />
<fieldType name="text_ik" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.LowerCaseFilterFactory"/>
<!--提取词干filter ,解决英语时态的问题-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<!--同义词-->
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
5、solr\collection1\conf下添加synonyms.txt、stopwords.txt文件。
添加中文后,需要用ue另存为 无BOM 的 UTF-8 编码,否则启动tomcat报错java.nio.charset.MalformedInputException: Input length = 1。
synonyms.txt内容:
无数,许多
蓝色,浅蓝色
stopwords.txt
上
6、测试
分词内容:Bunnies i'm coding 2014无数浮游生物随着浪花冲在沙滩上形成了荧光海滩
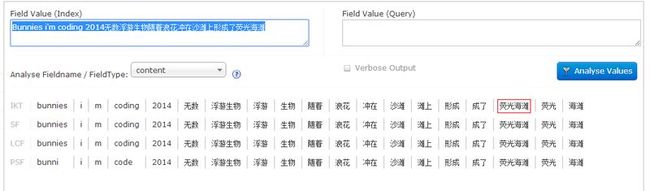
在query页面搜索:
索引后,搜索code codes bunny 各时态,荧光海滩 扩展词 ,许多 同义词 可以搜出内容。
搜索“了” “上”停用词 查不出结果。说明web 工程和solr 部署目录下的停用词都起了作用。
7、名称说明
同义词:
synonyms.txt一行为单位配置格式:
Gifts,gift
ideapad,ideacenter,lenovo,联想
原1,原2,...=>目标1,目标2 (原可以多个,目标也可以多个)
即当输入搜索词原1的时候,最后以 目标1,目标2当个词搜索。
如果expand为true,等同于
ideapad,ideacenter,lenovo,联想 =>ideapad,ideacenter,lenovo,联想
参考:http://my.oschina.net/baowenke/blog/104019
停用词:
为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词)。
应用十分广泛的词。语气助词、副词、介词、连接词等,通常自身 并无明确的意义,只有将其放入一个完整的句子中才有一定作用,如常见的“的”、“在”之类。
在网页Title中避免出现Stop Words往往能够让我们优化的关键词更突出。
如果没有指定analyzer的type,则表明index与query阶段用的是同样的analyzer。
BOM: Byte Order MarkUTF-8 BOM又叫UTF-8 签名,其实UTF-8 的BOM对UFT-8没有作用,是为了支援UTF-16,UTF-32才加上的BOM,BOM签名的意思就是告诉编辑器当前文件采用何种编码,方便编辑器识别,但是BOM虽然在编辑器中不显示,但是会产生输出,就像多了一个空行。
8、ik源码中的demo
/** * IK 中文分词 版本 5.0.1 * IK Analyzer release 5.0.1 * 源代码由林良益([email protected])提供 * 版权声明 2012,乌龙茶工作室 * provided by Linliangyi and copyright 2012 by Oolong studio * * */ package org.wltea.analyzer.sample; import java.io.IOException; import java.io.StringReader; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.apache.lucene.analysis.tokenattributes.OffsetAttribute; import org.apache.lucene.analysis.tokenattributes.TypeAttribute; import org.wltea.analyzer.lucene.IKAnalyzer; /** * 使用IKAnalyzer进行分词的演示 * 2012-10-22 * */ public class IKAnalzyerDemo { public static void main(String[] args){ //构建IK分词器,使用smart分词模式 // useSmart 为true,使用智能分词策略。非智能分词:细粒度输出所有可能的切分结果 。智能分词: 合并数词和量词,对分词结果进行歧义判断 Analyzer analyzer = new IKAnalyzer(true); //获取Lucene的TokenStream对象 TokenStream ts = null; try { ts = analyzer.tokenStream("myfield", new StringReader("这是一个中文分词的例子,你可以直接运行它!IKAnalyer can analysis english text too")); //获取词元位置属性 OffsetAttribute offset = ts.addAttribute(OffsetAttribute.class); //获取词元文本属性 CharTermAttribute term = ts.addAttribute(CharTermAttribute.class); //获取词元文本属性 TypeAttribute type = ts.addAttribute(TypeAttribute.class); //重置TokenStream(重置StringReader) ts.reset(); //迭代获取分词结果 while (ts.incrementToken()) { System.out.println(offset.startOffset() + " - " + offset.endOffset() + " : " + term.toString() + " | " + type.type()); } //关闭TokenStream(关闭StringReader) ts.end(); // Perform end-of-stream operations, e.g. set the final offset. } catch (IOException e) { e.printStackTrace(); } finally { //释放TokenStream的所有资源 if(ts != null){ try { ts.close(); } catch (IOException e) { e.printStackTrace(); } } } } }