在技术支持中碰到最多的应该就是编码问题,有必要做一个详细的分析以巩固自己,再来对他人有所帮助。
乱码一般出现在:
1.写在jsp文件中的中文变成乱码
2.页面的中文都变成乱码
3.后台通过request.getParameter()乱码(注意 getQueryString()和getParameter()在编码方面是有区别的,getQueryString()方法应用服务器是不会进行编码 转化的,也就是说不管setCharacterEncoding()设置的是什么字符集,getQueryString都是按服务器容器自身的字符集进行 转码的,在was上试过,其他的应用服务器不敢保证是这样,有时间试试)
编码的基础知识
- 字符->字节:编码,例如:“中”的UTF-8编码为 E4 B8 AD
- 字节->字符:解码,例如:字节数组D0 D6根据GB2312解码为字符“中”
- 还有一类编码称为URI编码和URI解码,不过URI编码和解码不是字符串和字节流之间的转换,而是由一个字符串表示另一个字符串,例如:
- “中”的UTF-8 URI编码为 %E4%B8%AD
- 字符串%E4%B8%AD根据UTF-8进行URI解码为字符“中”
- 可以看出来,URI编码就是将一个字符串用%+对应字符集的编码组织的字符串来表示的,在java中String类有两个常用的方法进行编码和解码:
- getBytes :例如“中”.getBytes(“字符集”),根据指定的字符集进行编码
- String(bytes[],”字符集”):根据自定的字符集对字节数组进行解码
- <span style="font-size: small;"><html xmlns="http://www.w3.org/1999/xhtml">
- <head>
- <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
- <title>test</title>
- </head>
- <body>
- <form action=http://www.google.com>
- <input type=text name=test value="中" />
- <input type=submit />
- </form>
- </body>
- </html>
- </span>
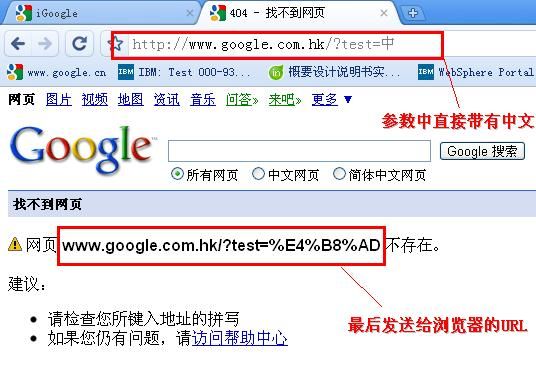
但 是不同的浏览器采用的字符集却不一样,如上面的这个超链接片段,在windows7中,不论页面的content="text/html; charset=utf-8"还是content="text/html; charset=GBK"IE8发送的都是www.google.com.hk/?test=%D6%D0,可以看出这是GBK的URI编码,IE8对超 链接中的URI编码与页面的编码无关,与系统的默认编码有关;而在windosx xp中,IE8发送的是页面编码采用的字符集进行的URI编码,如果页面编码为GBK,IE6发送的为GBK的页面编码,如果页面编码为UTF-8则只发 送UTF-8的URI编码的前两个字节;在其他的浏览器中,如Firefox和chrome,其URI编码采用的是页面的编码。
| 操作系统 | 浏览器 | 页面编码 | 发送的请求字符串 | 说明 |
| windows7 | IE8中文 | UTF-8 | test=%D6%D0 | windows7中,采用GBK字符集进行URI编码与页面的编码无关 |
| windows7 | IE8中文 | GBK | test=%D6%D0 | |
| XP | IE8中文 | UTF-8 | test=%E4%B8%AD | xp中与采用页面编码的字符集进行URI编码 |
| XP | IE8中文 | GBK | test=%D6%D0 | |
| windows2003 | IE6中文 | GBK | test=%D6%D0 | GBK是正确,UTF-8是不正确 |
| windows2003 | IE6中文 | UTF-8 | test=%E4%B8 | |
| -- | chrome中文,firefox英文 | UTF-8 | test=%E4%B8%AD | 采用页面编码的字符集进行URI编码 |
| -- | chrome中文,firefox英文 | GBK | test=%D6%D0 |
可以看出,直接在URL中带中文,IE的不同版本在不同的操作系统中进行 URI编码的结果可能不一样,chrome和firefox使用编码和表单的get方式的编码一致,因此,直接在链接中写非asc字符是很危险的,因为字 符的编码方式和客户端的环境有关。所以为了避免浏览器进行不确定的URI编码,需要在程序中将中文进行URI编码后在放到URL中,JavaScript 提供了encodeURI()函数,它提供的是根据页面的字符集进行URI编码,在jsp或servelt中可以通过 java.net.URLEncoder.encode(str,"字符集")进行编码。
3)ajax
ajax可以指定get方式或者post方式,情况和上面说的类似
2.应用服务器获取参数
在servlet中一般通过request.getParameter()来获得浏览器发送过来的参数,需要注意的是,服务器Servlet的最底 层接受到的是InputStream,也就是字节流,request.getParameter()返回的是一个字符串,因此在 getParameter()方法的内部存在解码的过程,而解码所采用的字符集根据应用服务器和操作系统的不同有可能不同,ServletRequest 接口提供了一个方法:setCharacterEncoding()来设置getParameter解码的字符集,这个方法必需在 getParameter之前调用,通过查看tomcate的源代码发现getParameter在第一次调用时会去初始化一个map的对象,map中存 储的就是参数名和参数值,这些值就是根据设置的字符集进行解码的,一旦这些对象解码完毕,下次调用就直接从map中取值,而不需要重新去解码了,所以 setCharacterEncoding必需在getParameter之前调用才有作用,也有人说这个方法只对post传递参数有效,而对get方法 传递的参数无效,对tomcat5确实是这样的,但是对Websphere和apsuic,setCharacterEncoding对post和get 同样有效。
效。
| 应用服务器 | 服务器所在系统默认编码 | 页面编码 | 提交方式 | URI编码 | setCharacterEncoding | getParameter结果 | 备注 |
| websphere6.1 | GBK | UTF-8 | POST | - | UTF-8 | 正确 | 服务器默认配置 |
| POST | - | GBK | 错误 | ||||
| GET | UTF-8 | UTF-8 | 正确 | ||||
| 超链接 | GBK | GBK | 正确 | ||||
| tomcat5.5 | GBK | UTF-8 | POST | UTF-8 | 正确 | 未设置URIEncoding和 useBodyEncodingForURI | |
| POST | GBK | 错误 | |||||
| GET | UTF-8 | UTF-8 | 错误 | ||||
| 超链接 | GBK | GBK | 错误 | ||||
| apusic5.1 | GBK | UTF-8 | POST | UTF-8 | 正确 | 服务器默认配置 | |
| POST | GBK | 错误 | |||||
| GET | UTF-8 | UTF-8 | 正确 | ||||
| 超链接 | GBK | GBK | 正确 |
从上面的表格可以 看出,Websphere6.1,apusic5.1应用服务器的get和post方法其getParameter解码所用的字符集是 setCharacterEncoding所指定的字符集,tomcat5的post方法使用的是setCharacterEncoding,但是get 方法却不是。再回过头看看这几个试验的过程,浏览器使用post方法时将会采用页面的字符集进行编码成字节流发送到服务器,服务器接收到字节流后根据 setCharacterEncoding设定的字符集进行解码,获得字符串,也就是说,如果使用post方法提交,只要保证“页面的编码的字符 集=setCharacterEncoding设置的字符集”那么getParameter获得的值就是正确的,get和超链接的方式类似,表单使用 get提交时,会根据页面的编码进行encodeURI,超链接的方式程序可以根据指定的字符集进行URI编码,两种方式的共同点是浏览器都会进行URI 编码,在Websphere中,get和超链接的方式只要“URI编码的字符集=setCharacterEncoding的字符集”,那么 getParameter的结果就是正确的,而使用get提交表单时其“URI编码的字符集=页面编码的字符集”,超链接的URI编码的字符集在上面说 过,chrome和Firefox浏览器中URI编码的字符集=页面编码的字符集,但是IE却不是,没有规律。
tomcat5.5 中getParameter获取get方法或超链接传过来的参数时默认会用ISO8859-1进行解码,例如浏览器发送UTF-8的编码的请 求,tomcat5.5的getParameter使用ISO8859-1解码,这时的结果是错的,如果要获得正确的值,需要在tomcat5.5的 getParameter的时候采用UTF-8进行解码,通过设置URIEncoding="UTF-8"或者 useBodyEncodingForURI="true",就能让tomcat在的getParameter时采用UTF-8解码 (useBodyEncodingForURI="true"表示解码的字符集采用与页面编码相同的字符集),如果不通过配置要并且需要获得正确的值,则 需要程序进行转码,因为getParameter是通过ISO8859-1解码的,所有先通过 getParameter().getBytes("ISO8859-1")编码成原来的字节数组,然后使用UTF-8字符集解码为字符串:new String(getParameter().getBytes("ISO8859-1"),"UTF-8")
3.设置浏览器的页面编码
服务器向浏览器发送的也是经过编码成字节流在网络上传输,浏览器接收到字节流之后使用指定的 字符集解码成字符串再进行展现,如果这两个环节的字符集不一致也会导致乱码的问题,例如静态HTML文件或jsp中都是以UTF-8保存的,则需要告诉浏 览器用UTF-8来进行解码,如果是jsp可以通过<%@ page contentType="text/html; charset=UTF-8" language="java" %>来进行设置,静态文件可以通过 <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/> 进行设置,如果在servlet中直接进行输出,可以通过response.setCharacterEncoding("UTF- 8"),setContentType("text/html;charset=UTF-8"),setHeader("Content- Type","text/html;charset=UTF-8")进行设置,这些操作都相当于在response的头部增加"Content- Type:text/html;charset=UTF-8"信息,header中的编码信息的优先级要高于html的meta标签,也就是说如果 serlvet中设置了setContentType("text/html;charset=UTF-8"),jsp设置了<meta http-equiv="Content-Type" content="text/html; charset=GBK"/>则浏览器会按照UTF-8字符集进行解码,需要说明的是,servlet这些设置浏览器编码格式的方法需要在进行输入 之前调用,jsp的page指令也需要在输出内容的行之前。正如前面实验所看到的,浏览器的页面编码不仅决定了浏览器按照什么字符集解码从服务器传输过来 的字节流,还决定了浏览器按照什么字符集进行编码向服务器发送请求。
4.设置HTML文件和jsp文件的编码,设置jsp编译的编码
文件存储的编码格式要和页面的编码集一致,否则将导致写在页面上的汉字出现乱码问题,例如 HTML文件中设置页面的编码为UTF-8格式,那么此文件的存储格式也应该为UTF-8的,可以通过记事本或者Editplus打开文件,选择另存为, 然后编码选择UTF-8,覆盖原来的文件即可。jsp文件和html文件一样,页面的编码和文件保存的编码要一致,而且要指定jsp的编译编码和文件的保 存编码一致,也就是pageEncding的值要和文件保存的编码一致。
如何解决乱码问题
1).统一编码:页面编码=URI编码=setCharacterEncoding=文件保 存编码=jsp编译编码,这种解决方法能解决绝大部分的乱码问题,在WebSphere服务器,apusic服务器,post和get都能获得正确的值, 但是在tomcat5.5中get方式还是会出现乱码,可以设置URIEncoding="UTF-8"或者 useBodyEncodingForURI="true"来解决,这种方法付出的代价最小,效率也最高,应该使用这种方法来解决乱码问题。
2).两次次URI编码,服务器URI解码:在程序中由程序进行2次URI编码,其原理是利 用不同服务器其默认解码字符集对ASC字符的解码结果是一样的,例 如:url="TestServlet?test="+encodeURI(encodeURI("中")),浏览器发送的结果 为:TestServlet?test=%25E4%25B8%25AD,应用服务器遇到%号开头的字节会进行解码,不同的应用服务器,都会将%25解析 为%,所以参数被析为test=%E4%B8%AD,也即是说getParameter("test")的值为%E4%B8%AD,这就是“中”的 UTF-8的URI编码,通过java.net.URLDecoder.decode(getParameter("test"),"UTF-8")便可 获得字符“中”,这种方法不需要设置服务器的setCharacterEncoding,也不用关系页面的编码字符集,但是需要手动进行URI编码,后台 还需要进行一次URL解码,适合解决少数乱码问题。
3).BASE64编码:参数先经过BASE64编码,服务器端在进行BASE64解 码,BASE64是可逆的编码方式,编码后都是ASC字符,能在浏览器和应用服务器之间安全的传输而不会出现乱码。不过和方法2一样,需要进行一次 BASE64编码和解码,并且还需要在页面和后台添加支持BASE64编码和解码的函数,这种方式也只适合于解决少数乱码问题,和方法2相 比,BASE64更适合于解决参数中有特殊符号的情况。
4).转码:将错误的字符串编码还原为原来的字节数组,然后用此字节数组通过正确的字符集解 码为正确的字符串,例如:new String(request.getParamter("test").getBytes("ISO8859-1"),"UTF-8"),使用这种方法 的前提是需要知道浏览器发送过来的编码字符集,和服务器解码所使用的字符集,上面例子中表示应用服务器解码的字符集是ISO8859-1,浏览器发送过来 编码所用字符集是UTF-8,这种方法需要根据应用服务器的编码来进行转换,不同的应用服务器可能不同,所用此方法并不通用,只适合于解决在某个具体应用 服务器中出现的乱码问题。
总结
- 字符->字节:编码,字节->字符:解码
- URI编码是用一个字符串表示另一个字符串,URI编码就是用要编码的字符串根据指定的字符集解码后每个字节码前加上%组织的字符串,例如“中”的UTF-8编码为E4 B8 AD三个字节,那么其UTF-8的URI编码为:%E4%B8%AD组织的字符串
- 浏览器的发送给服务器的URL只能包含ASC字符,如果URL中包含非ASC字符,浏览器会进行URI编码
- post提交时,表单的数据会根据页面编码的字符集进行编码发送到浏览器(每个form也可以单独设置编码字符集,如果没设置则采用页面的编码字符集)
- get提交时,表单中的数据会根据页面的字符集进行URI编码
- 链接中直接带有非ASC字符时,浏览器也会进行编码,但编码所用的字符集跟浏览器有关
- 需要在url后面添加非ASC字符的参数时,更安全的做法是自己进行根据指定的字符集进行URI编码,因为不同的浏览器编码结果可能不一样
- request.getParameter获得值经过了服务器的解码,POST方法时所有的服务器都是通过 setCharacterEncoding进行解码的,GET方法时,WebSphere和apusic也是使用 setCharacterEncoding指定的字符集进行解码,tomcat5则是通过ISO8859-1进行解码
- 可以通过调整tomcat5的配置来指定get方法时request.getParameter解码所用的字符集,修改server.xml中 Connecter元素,增加属性URIEncoding="UTF-8"设定字符集,或者增加属性 useBodyEncodingForURI="true"表示使用页面的编码所用的字符集
- 解决乱码的最好方法是编码5统一:页面编码=URI编码=setCharacterEncoding=文件保存编码=jsp编译编码
jboss7解析request参数的逻辑是:
1.首先获得request的CharacterEncoding(这个值通过request.setCharacterEncoding设置),及connector的UseBodyEncodingForURI(这个值通过在jboss的standalone.xml中 <property name="org.apache.catalina.connector.USE_BODY_ENCODING_FOR_QUERY_STRING" value="true"/>设置);
2.如果request的CharacterEncoding不为空,则设置post参数的字符集为此CharacterEncoding(源码通过parameters.setEncoding());同时如果connector的UseBodyEncodingForURI为true,则设置get参数的字符集为此CharacterEncoding(源码通过parameters.setQueryStringEncoding())
3.如果request的CharacterEncoding为空,则设置post参数的字符集为ISO-8859-1;同时如果connector的UseBodyEncodingForURI为true,则设置get参数的字符集为ISO-8859-1
此解析过程见源码http://grepcode.com/file/repo1.maven.org/maven2/org.apache.geronimo.ext.tomcat/catalina/7.0.39.2/org/apache/catalina/connector/Request.java#Request.parseParameters%28%29
细心的你可能会总结发现解码post参数的字符集完全取决于request的CharacterEncoding;而get参数的字符集取决于connector的UseBodyEncodingForURI,只有UseBodyEncodingForURI为true的时候才设置get参数的字符集,那么问题来了,如果UseBodyEncodingForURI为false那get参数的字符集应该是什么呢?它在别处哪里有设置吗?答案是肯定的,见源码http://grepcode.com/file/repo1.maven.org/maven2/org.apache.geronimo.ext.tomcat/catalina/7.0.39.2/org/apache/catalina/connector/CoyoteAdapter.java#493,我们发现早在创建request的时候就设置了get参数的字符集,而且设置的是connector的URIEncoding值(这个值通过jboss的standalone.xml中<property name="org.apache.catalina.connector.URI_ENCODING" value="UTF-8"/>设置)
最后总结:
1、决定post参数解码的字符集只有一种方式:request.setCharacterEncoding;
2、决定get参数解码的字符集有两种方式:request.setCharacterEncoding+connector的UseBodyEncodingForURI设为true,或者设置connector的URI_ENCODING
假设前端传递发送过来的参数(无论get还是post)都是UTF-8编码的(因为页面html中设置了content="text/html; charset=UTF-8"),因此要正确就解析参数就必须也通过UTF-8来解码;
参照上文jboss7解析参数的过程,所以这里要设置request.setCharacterEncoding("UTF-8"),同时在jboss的standalone.xml中配置USE_BODY_ENCODING_FOR_QUERY_STRING=true或者connector的URI_ENCODING="UTF-8"