Oracle Hint
Hint 是Oracle 提供的一种SQL语法,它允许用户在SQL语句中插入相关的语法,从而影响SQL的执行方式。
因为Hint的特殊作用,所以对于开发人员不应该在代码中使用它,Hint 更像是Oracle提供给DBA用来分析问题的工具 。在SQL代码中使用Hint,可能导致非常严重的后果,因为数据库的数据是变化的,在某一时刻使用这个执行计划是最优的,在另一个时刻,却可能很差,这也是CBO 取代RBO的原因之一,规则是死的,而数据是时刻变化的,为了获得最正确的执行计划,只有知道表中数据的实际情况,通过计算各种执行计划的成本,则其最优,才是最科学的,这也是CBO的工作机制。 在SQL代码中加入Hint,特别是性能相关的Hint是很危险的做法。
Hints are comments in a SQL statement that pass instructions to the Oracle Database optimizer. The optimizer uses these hints to choose an execution plan for the statement, unless some condition exists that prevents the optimizer from doing so.
Hints were introduced in Oracle7, when users had little recourse if the optimizer generated suboptimal plans. Now Oracle provides a number of tools, including the SQL Tuning Advisor, SQL plan management, and SQL Performance Analyzer, to help you address performance problems that are not solved by the optimizer. Oracle strongly recommends that you use those tools rather than hints. The tools are far superior to hints, because when used on an ongoing basis, they provide fresh solutions as your data and database environment change.
Hints should be used sparingly, and only after you have collected statistics on the relevant tables and evaluated the optimizer plan without hints using the EXPLAIN PLAN statement. Changing database conditions as well as query performance enhancements in subsequent releases can have significant impact on how hints in your code affect performance.
The remainder of this section provides information on some commonly used hints. If you decide to use hints rather than the more advanced tuning tools, be aware that any short-term benefit resulting from the use of hints may not continue to result in improved performance over the long term.
Oracle 联机文档对Hint的说明:
http://download.oracle.com/docs/cd/E11882_01/server.112/e10592/sql_elements006.htm#SQLRF50705
之前整理的一篇文章:
常见Oracle HINT的用法
在SQL语句优化过程中,我们经常会用到hint,现总结一下在SQL优化过程中常见Oracle HINT的用法:
1. /*+ALL_ROWS*/
表明对语句块选择基于开销的优化方法,并获得最佳吞吐量,使资源消耗最小化.
例如:
SELECT /*+ALL+_ROWS*/ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO='SCOTT';
2. /*+FIRST_ROWS*/
表明对语句块选择基于开销的优化方法,并获得最佳响应时间,使资源消耗最小化.
例如:
SELECT /*+FIRST_ROWS*/ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO='SCOTT';
3. /*+CHOOSE*/
表明如果数据字典中有访问表的统计信息,将基于开销的优化方法,并获得最佳的吞吐量;
表明如果数据字典中没有访问表的统计信息,将基于规则开销的优化方法;
例如:
SELECT /*+CHOOSE*/ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO='SCOTT';
4. /*+RULE*/
表明对语句块选择基于规则的优化方法.
例如:
SELECT /*+ RULE */ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO='SCOTT';
5. /*+FULL(TABLE)*/
表明对表选择全局扫描的方法.
例如:
SELECT /*+FULL(A)*/ EMP_NO,EMP_NAM FROM BSEMPMS A WHERE EMP_NO='SCOTT';
6. /*+ROWID(TABLE)*/
提示明确表明对指定表根据ROWID进行访问.
例如:
SELECT /*+ROWID(BSEMPMS)*/ * FROM BSEMPMS WHERE ROWID>='AAAAAAAAAAAAAA'
AND EMP_NO='SCOTT';
7. /*+CLUSTER(TABLE)*/
提示明确表明对指定表选择簇扫描的访问方法,它只对簇对象有效.
例如:
SELECT /*+CLUSTER */ BSEMPMS.EMP_NO,DPT_NO FROM BSEMPMS,BSDPTMS
WHERE DPT_NO='TEC304' AND BSEMPMS.DPT_NO=BSDPTMS.DPT_NO;
8. /*+INDEX(TABLE INDEX_NAME)*/
表明对表选择索引的扫描方法.
例如:
SELECT /*+INDEX(BSEMPMS SEX_INDEX) USE SEX_INDEX BECAUSE THERE ARE FEWMALE BSEMPMS */ FROM BSEMPMS WHERE SEX='M';
9. /*+INDEX_ASC(TABLE INDEX_NAME)*/
表明对表选择索引升序的扫描方法.
例如:
SELECT /*+INDEX_ASC(BSEMPMS PK_BSEMPMS) */ FROM BSEMPMS WHERE DPT_NO='SCOTT';
10. /*+INDEX_COMBINE*/
为指定表选择位图访问路经,如果INDEX_COMBINE中没有提供作为参数的索引,将选择出位图索引的布尔组合方式.
例如:
SELECT /*+INDEX_COMBINE(BSEMPMS SAL_BMI HIREDATE_BMI)*/ * FROM BSEMPMS
WHERE SAL<5000000 AND HIREDATE<SYSDATE;
11. /*+INDEX_JOIN(TABLE INDEX_NAME)*/
提示明确命令优化器使用索引作为访问路径.
例如:
SELECT /*+INDEX_JOIN(BSEMPMS SAL_HMI HIREDATE_BMI)*/ SAL,HIREDATE
FROM BSEMPMS WHERE SAL<60000;
12. /*+INDEX_DESC(TABLE INDEX_NAME)*/
表明对表选择索引降序的扫描方法.
例如:
SELECT /*+INDEX_DESC(BSEMPMS PK_BSEMPMS) */ FROM BSEMPMS WHERE DPT_NO='SCOTT';
13. /*+INDEX_FFS(TABLE INDEX_NAME)*/
对指定的表执行快速全索引扫描,而不是全表扫描的办法.
例如:
SELECT /*+INDEX_FFS(BSEMPMS IN_EMPNAM)*/ * FROM BSEMPMS WHERE DPT_NO='TEC305';
14. /*+ADD_EQUAL TABLE INDEX_NAM1,INDEX_NAM2,...*/
提示明确进行执行规划的选择,将几个单列索引的扫描合起来.
例如:
SELECT /*+INDEX_FFS(BSEMPMS IN_DPTNO,IN_EMPNO,IN_SEX)*/ * FROM BSEMPMS WHERE EMP_NO='SCOTT' AND DPT_NO='TDC306';
15. /*+USE_CONCAT*/
对查询中的WHERE后面的OR条件进行转换为UNION ALL的组合查询.
例如:
SELECT /*+USE_CONCAT*/ * FROM BSEMPMS WHERE DPT_NO='TDC506' AND SEX='M';
16. /*+NO_EXPAND*/
对于WHERE后面的OR 或者IN-LIST的查询语句,NO_EXPAND将阻止其基于优化器对其进行扩展.
例如:
SELECT /*+NO_EXPAND*/ * FROM BSEMPMS WHERE DPT_NO='TDC506' AND SEX='M';
17. /*+NOWRITE*/
禁止对查询块的查询重写操作.
18. /*+REWRITE*/
可以将视图作为参数.
19. /*+MERGE(TABLE)*/
能够对视图的各个查询进行相应的合并.
例如:
SELECT /*+MERGE(V) */ A.EMP_NO,A.EMP_NAM,B.DPT_NO FROM BSEMPMS A (SELET DPT_NO
,AVG(SAL) AS AVG_SAL FROM BSEMPMS B GROUP BY DPT_NO) V WHERE A.DPT_NO=V.DPT_NO
AND A.SAL>V.AVG_SAL;
20. /*+NO_MERGE(TABLE)*/
对于有可合并的视图不再合并.
例如:
SELECT /*+NO_MERGE(V) */ A.EMP_NO,A.EMP_NAM,B.DPT_NO FROM BSEMPMS A (SELECT DPT_NO,AVG(SAL) AS AVG_SAL FROM BSEMPMS B GROUP BY DPT_NO) V WHERE A.DPT_NO=V.DPT_NO AND A.SAL>V.AVG_SAL;
21. /*+ORDERED*/
根据表出现在FROM中的顺序,ORDERED使ORACLE依此顺序对其连接.
例如:
SELECT /*+ORDERED*/ A.COL1,B.COL2,C.COL3 FROM TABLE1 A,TABLE2 B,TABLE3 C WHERE A.COL1=B.COL1 AND B.COL1=C.COL1;
22. /*+USE_NL(TABLE)*/
将指定表与嵌套的连接的行源进行连接,并把指定表作为内部表.
例如:
SELECT /*+ORDERED USE_NL(BSEMPMS)*/ BSDPTMS.DPT_NO,BSEMPMS.EMP_NO,BSEMPMS.EMP_NAM FROM BSEMPMS,BSDPTMS WHERE BSEMPMS.DPT_NO=BSDPTMS.DPT_NO;
23. /*+USE_MERGE(TABLE)*/
将指定的表与其他行源通过合并排序连接方式连接起来.
例如:
SELECT /*+USE_MERGE(BSEMPMS,BSDPTMS)*/ * FROM BSEMPMS,BSDPTMS WHERE BSEMPMS.DPT_NO=BSDPTMS.DPT_NO;
24. /*+USE_HASH(TABLE)*/
将指定的表与其他行源通过哈希连接方式连接起来.
例如:
SELECT /*+USE_HASH(BSEMPMS,BSDPTMS)*/ * FROM BSEMPMS,BSDPTMS WHERE BSEMPMS.DPT_NO=BSDPTMS.DPT_NO;
25. /*+DRIVING_SITE(TABLE)*/
强制与ORACLE所选择的位置不同的表进行查询执行.
例如:
SELECT /*+DRIVING_SITE(DEPT)*/ * FROM BSEMPMS,DEPT@BSDPTMS WHERE BSEMPMS.DPT_NO=DEPT.DPT_NO;
26. /*+LEADING(TABLE)*/
将指定的表作为连接次序中的首表.
27. /*+CACHE(TABLE)*/
当进行全表扫描时,CACHE提示能够将表的检索块放置在缓冲区缓存中最近最少列表LRU的最近使用端
例如:
SELECT /*+FULL(BSEMPMS) CAHE(BSEMPMS) */ EMP_NAM FROM BSEMPMS;
28. /*+NOCACHE(TABLE)*/
当进行全表扫描时,CACHE提示能够将表的检索块放置在缓冲区缓存中最近最少列表LRU的最近使用端
例如:
SELECT /*+FULL(BSEMPMS) NOCAHE(BSEMPMS) */ EMP_NAM FROM BSEMPMS;
29. /*+APPEND*/
直接插入到表的最后,可以提高速度.
insert /*+append*/ into test1 select * from test4 ;
30. /*+NOAPPEND*/
通过在插入语句生存期内停止并行模式来启动常规插入.
insert /*+noappend*/ into test1 select * from test4 ;
在使用Hint时需要注意的一点是,并非任何时刻Hint都起作用。 导致HINT 失效的原因有如下2点:
(1) 如果CBO 认为使用Hint 会导致错误的结果时,Hint将被忽略。
如索引中的记录因为空值而和表的记录不一致时,结果就是错误的,会忽略hint。
(2) 如果表中指定了别名,那么Hint中也必须使用别名,否则Hint也会忽略。
Select /*+full(a)*/ * from t a; -- 使用hint
Select /*+full(t) */ * from t a; --不使用hint
根据hint的功能,可以分成如下几类:
| Hint | Hint 语法 |
| 优化器模式提示 | ALL_ROWS Hint |
| FIRST_ROWS Hint | |
| RULE Hint |
| 访问路径提示 | CLUSTER Hint |
| FULL Hint | |
| HASH Hint | |
| INDEX Hint | |
| NO_INDEX Hint | |
| INDEX_ASC Hint | |
| INDEX_DESC Hint | |
| INDEX_COMBINE Hint | |
| INDEX_FFS Hint | |
| INDEX_SS Hint | |
| INDEX_SS_ASC Hint | |
| INDEX_SS_DESC Hint | |
| NO_INDEX_FFS Hint | |
| NO_INDEX_SS Hint | |
| ORDERED Hint | |
| LEADING Hint | |
| USE_HASH Hint | |
| NO_USE_HASH Hint | |
| 表连接顺序提示 | USE_MERGE Hint |
| NO_USE_MERGE Hint | |
| USE_NL Hint | |
| USE_NL_WITH_INDEX Hint | |
| NO_USE_NL Hint | |
| 表关联方式提示 | PARALLEL Hint |
| NO_PARALLEL Hint | |
| PARALLEL_INDEX Hint | |
| NO_PARALLEL_INDEX Hint | |
| PQ_DISTRIBUTE Hint | |
| 并行执行提示 | FACT Hint |
| NO_FACT Hint | |
| MERGE Hint | |
| NO_MERGE Hint | |
| NO_EXPAND Hint | |
| USE_CONCAT Hint | |
| 查询转换提示 | REWRITE Hint |
| NO_REWRITE Hint | |
| UNNEST Hint | |
| NO_UNNEST Hint | |
| STAR_TRANSFORMATION Hint | |
| NO_STAR_TRANSFORMATION Hint | |
| NO_QUERY_TRANSFORMATION Hint | |
| APPEND Hint | |
| NOAPPEND Hint | |
| CACHE Hint | |
| NOCACHE Hint | |
| CURSOR_SHARING_EXACT Hint | |
| 其他Hint | DRIVING_SITE Hint |
| DYNAMIC_SAMPLING Hint | |
| PUSH_PRED Hint | |
| NO_PUSH_PRED Hint | |
| PUSH_SUBQ Hint | |
| NO_PUSH_SUBQ Hint | |
| PX_JOIN_FILTER Hint | |
| NO_PX_JOIN_FILTER Hint | |
| NO_XML_QUERY_REWRITE Hint | |
| QB_NAME Hint | |
| MODEL_MIN_ANALYSIS Hint |
一. 和优化器相关的Hint
Oracle 允许在系统级别,会话级别和SQL中(hint)优化器类型:
系统级别:
1: SQL>alter system set optimizer_mode=all_rows;<!--CRLF-->
会话级别:
SQL>alter system set optimizer_mode=all_rows;<!--CRLF-->
关于优化器,参考:
Oracle Optimizer CBO RBO
Oracle 数据库中优化器(Optimizer)是SQL分析和执行的优化工具,它负责指定SQL的执行计划,也就是它负责保证SQL执行的效率最高,比如优化器决定Oracle 以什么样的方式来访问数据,是全表扫描(Full Table Scan),索引范围扫描(Index Range Scan)还是全索引快速扫描(INDEX Fast Full Scan:INDEX_FFS);对于表关联查询,它负责确定表之间以一种什么方式来关联,比如HASH_JOHN还是NESTED LOOPS 或者MERGE JOIN。 这些因素直接决定SQL的执行效率,所以优化器是SQL 执行的核心,它做出的执行计划好坏,直接决定着SQL的执行效率。
Oracle 的优化器有两种:
RBO(Rule-Based Optimization): 基于规则的优化器
CBO(Cost-Based Optimization): 基于代价的优化器
从Oracle 10g开始,RBO 已经被弃用,但是我们依然可以通过Hint 方式来使用它。
一. RBO 基于规则的优化器
在8i之前,Oracle 使用的是一种叫作RBO(Rule Based Optimizer)的优化器,它的执行机制非常简单,就是在优化器里面嵌入若干种规则,执行的SQL语句符合哪种规则(RANK),则按照规则(RANK)制定出相应的执行计划,比如说表上有个索引,如果谓词上有索引的列存在,则Oracle 会选择索引,否则选择全表扫描;又比如,两个表关联的时候,按照表在SQL中的位置来决定哪个是驱动表,哪个是被驱动表。
RBO 选择执行计划的一个优先级列表
| Rank |
Access Path |
| 1 |
Single row by ROWID |
| 2 |
Single row by cluster join |
| 3 |
Single row by hash cluster key with unique or primary key |
| 4 |
Single row by unique or primary key |
| 5 |
Cluster Join |
| 6 |
Hash cluster key |
| 7 |
Indexed cluster key |
| 8 |
Composite index |
| 9 |
Single-column index |
| 10 |
Bounded range search on indexed columns |
| 11 |
Unbounded range search on indexed columns |
| 12 |
Sort-merge join |
| 13 |
MAX OR MIN of indexed column |
| 14 |
ORDER by on indexed column |
| 15 |
Full table scan |
由于RBO 只是简单的去匹配Rank,所以它的执行计划有时并不是最佳的。 比如我们有一张数据分布非常不均匀的表。 90%的数据内容是一样的,并且在这个字段上有索引。 如果我们的SQL 谓词里有这个字段,那么RBO 就会选择走索引。 这就会增加额外的开销。 因为Oracle 要先访问索引数据块,在索引上找到相应的键值,然后按照键值上的rowid 在去访问表中的相应数据。 在这种情况下,我们选择全表扫描是最优的,但是RBO 不会这么选择。
二. CBO 基于成本的优化器
从8i开始,Oracle 引入了CBO(Cost Based Optimizer),它的思路是让Oracle 获取所有执行计划相关的信息,通过对这些信息做计算分析,最后得出一个代价最小的执行计划作为最终的执行计划。
CBO是一种比RBO 更理性化的优化器。从10g开始,Oracle 已经彻底丢弃了RBO。 即使在表,索引没有被分析的时候,Oracle依然会使用CBO。此时,Oracle 会使用一种叫做动态采样的技术,在分析SQL的时候,动态的收集表,索引上的一些数据块,使用这些数据块的信息及字典表中关于这些对象的信息来计算出执行计划的代价,从而挑出最优的执行计划。
当表没有做分析的时候,Oracle 会使用动态采样来收集统计信息,这个动作只有在SQL执行的第一次,即硬分析阶段使用,后续的软分析将不在使用动态采样,直接使用第一次SQL 硬分析时生成的执行计划。
Oracle SQL的硬解析和软解析
http://blog.csdn.net/tianlesoftware/archive/2010/04/08/5458896.aspx
在Oracle 10g中,CBO 可选的运行模式有2种:
(1) FIRST_ROWS(n)
(2) ALL_ROWS -- 10g中的默认值
查看CBO 模式:
SQL> show parameter optimizer_mode
NAME TYPE VALUE
------------------------------------ ----------- -------------
optimizer_mode string ALL_ROWS
修改CBO 模式的三种方法:
(1) SQL 语句:
Sessions级别:
SQL> alter session set optimizer_mode=all_rows;
(2) 修改pfile 参数:
OPTIMIZER_MODE=RULE/CHOOSE/FIRST_ROWS/ALL_ROWS
(3) 语句级别用Hint(/* + ... */)来设定
Select /*+ first_rows(10) */ name from table;
Select /*+ all_rows */ name from table;
OPTIMIZER_INDEX_COST_ADJ参数
参数OPTIMIZER_INDEX_COST_ADJ可以理解为Oracle执行多块(MultiBlock)I/O(比如全表扫描)的代价与执行单块(Single-block)I/O代价的相对比例。OPTIMIZER_INDEX_COST_ADJ通过指明索引I/O代价与扫描全表I/O代价的相对比值来影响CBO的行为,取值越小,CBO越倾向于使用索引,取值越大,越倾向于全表扫描。而缺省值100,指明缺省下,二者的代价是相等。
官方文档(Reference)中对这个参数描述如下:
| Property |
Description |
| Parameter type |
Integer |
| Default value |
100 |
| Modifiable |
ALTER SESSION, ALTER SYSTEM |
| Range of values |
1 to 10000 |
OPTIMIZER_INDEX_COST_ADJ lets you tune optimizer behavior for access path selection to be more or less index friendly—that is, to make the optimizer more or less prone to selecting an index access path over a full table scan.
The default for this parameter is 100 percent, at which the optimizer evaluates index access paths at the regular cost. Any other value makes the optimizer evaluate the access path at that percentage of the regular cost. For example, a setting of 50 makes the index access path look half as expensive as normal.
Note:
The adjustment does not apply to user-defined cost functions for domain indexes.
http://download.oracle.com/docs/cd/B28359_01/server.111/b28320/initparams160.htm#REFRN10143
FIRST_ROWS(n) 模式说明
当CBO 的优化模式设置为FIRST_ROWS(n)时,Oracle 在执行SQL时,优先考虑将结果集中的前n条记录以最快的速度反馈回来,而其他的结果并不需要同时返回。
这种需求在一些网站或者BBS的分页上经常看到,比如每次只显示查询信息的前20条或者BBS上的前20个帖子, 这时候设置FIRST_ROWS(20)就非常合适,优化器并不需要同事将所有符合条件的结果返回,用户也不需要。这时,CBO将考虑用一种最快的返回前20条记录的执行计划,这种执行计划对于SQL的整体执行时间也不不是最快的,但是在返回前20条记录的处理上,确实最快的。
如:
Select /*+ first_rows(10) */b.x,b.y from
(
Select /*+ first_rows(10) */ a.*, rownum rnum from
(
Select /*+ first_rows(20) */ * from t order by x
) a
Where rownum < 20
) b where rnum >=10;
在这个分页例子中,每次从结果集中取10条记录,记录按照x字段排序。
注意: 排序使用的字段x 必须创建有索引,否则CBO 会忽略FIRST_ROWS(n),而使用ALL_ROWS.
ALL_ROWS 模式说明
当CBO 模式设置为ALL_ROWS时,Oracle 会用最快的速度将SQL执行完毕,将结果集全部返回,它和FIRST_ROWS(n)的区别在于,ALL_ROWS强调以最快的速度将SQL执行完毕,并将所有的结果集反馈回来,而FIRST_ROWS(n)则侧重于返回前n条记录的执行时间。
ALL_ROWS在OLAP 系统中使用得比较多,它用最快的速度获得SQL执行的最后一条记录,而不是前N条记录。 和FIRST_ROWS(n)正好相反。 ALL_ROWS 强调SQL整体的执行效率,而FIRST_ROWS(n)强调用最快的速度返回前N行,而不管所有的结果返回的时长,可能最后一条要很长时间才能获得。
1.1 ALL_ROWS 和FIRST_ROWS(n) -- CBO 模式
对于OLAP系统,这种系统中通常都是运行一些大的查询操作,如统计,报表等任务。 这时优化器模式应该选择ALL_ROWS. 对于一些分页显示的业务,就应该用FIRST_ROWS(n)。 如果是一个系统上运行这两种业务,那么就需要在SQL 用hint指定优化器模式。
如:
SQL> select /* + all_rows*/ * from dave;
SQL> select /* + first_rows(20)*/ * from dave;
1.2 RULE Hint -- RBO 模式
尽管Oracle 10g已经弃用了RBO,但是仍然保留了这个hint。 它允许在CBO 模式下使用RBO 对SQL 进行解析。
如:
SQL> show parameter optimizer_mode
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_mode string ALL_ROWS
SQL> set autot trace exp;
SQL> select /*+rule */ * from dave;
执行计划
----------------------------------------------------------
Plan hash value: 3458767806
----------------------------------
| Id | Operation | Name |
----------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS FULL| DAVE |
----------------------------------
Note
-----
- rule based optimizer used (consider using cbo) -- 这里提示使用RBO
SQL>
二. 访问路径相关的Hint
这一部分hint 将直接影响SQL 的执行计划,所以在使用时需要特别小心。 该类Hint对DBA分析SQL性能非常有帮助,DBA 可以让SQL使用不同的Hint得到不同的执行计划,通过比较不同的执行计划来分析当前SQL性能。
2.1 FULL Hint
该Hint告诉优化器对指定的表通过全表扫描的方式访问数据。
示例:
SQL> select /*+full(dave) */ * from dave;
要注意,如果表有别名,在hint里也要用别名, 这点在前面已经说明。
2.2 INDEX Hint
Index hint 告诉优化器对指定的表通过索引的方式访问数据,当访问索引会导致结果集不完整时,优化器会忽略这个Hint。
示例:
SQL> select /*+index(dave index_dave) */ * from dave where id>1;
谓词里有索引字段,才会用索引。
2.3 NO_INDEX Hint
No_index hint 告诉优化器对指定的表不允许使用索引。
示例:
SQL> select /*+no_index(dave index_dave) */ * from dave where id>1;
2.4 INDEX_DESC Hint
该Hint 告诉优化器对指定的索引使用降序方式访问数据,当使用这个方式会导致结果集不完整时,优化器将忽略这个索引。
示例:
SQL> select /*+index_desc(dave index_dave) */ * from dave where id>1;
2.5 INDEX_COMBINE Hint
该Hint告诉优化器强制选择位图索引,当使用这个方式会导致结果集不完整时,优化器将忽略这个Hint。
示例:
SQL> select /*+ index_combine(dave index_bm) */ * from dave;
2.6 INDEX_FFS Hint
该hint告诉优化器以INDEX_FFS(INDEX Fast Full Scan)的方式访问数据。当使用这个方式会导致结果集不完整时,优化器将忽略这个Hint。
示例:
SQL> select /*+ index_ffs(dave index_dave) */ id from dave where id>0;
2.7 INDEX_JOIN Hint
索引关联,当谓词中引用的列上都有索引时,可以通过索引关联的方式来访问数据。
示例:
SQL> select /*+ index_join(dave index_dave index_bm) */ * from dave where id>0 and name='安徽安庆';
2.8 INDEX_SS Hint
该Hint强制使用index skip scan 的方式访问索引,从Oracle 9i开始引入这种索引访问方式,当在一个联合索引中,某些谓词条件并不在联合索引的第一列时(或者谓词并不在联合索引的第一列时),可以通过index skip scan 来访问索引获得数据。 当联合索引第一列的唯一值很小时,使用这种方式比全表扫描效率要高。当使用这个方式会导致结果集不完整时,优化器将忽略这个Hint。
示例:
SQL> select /*+ index_ss(dave index_union) */ * from dave where id>0;
三. 表关联顺序的Hint
表之间的连接方式有三种。 具体参考blog:
多表连接的三种方式详解 HASH JOIN MERGE JOIN NESTED LOOP
3.1 LEADING hint
在一个多表关联的查询中,该Hint指定由哪个表作为驱动表,告诉优化器首先要访问哪个表上的数据。
示例:
SQL> select /*+leading(t1,t) */ * from scott.dept t,scott.emp t1 where t.deptno=t1.deptno;
SQL> select /*+leading(t,t1) */ * from scott.dept t,scott.emp t1 where t.deptno=t1.deptno;
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 812 | 6 (17)| 00
| 1 | MERGE JOIN | | 14 | 812 | 6 (17)| 00
| 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 4 | 80 | 2 (0)| 00
| 3 | INDEX FULL SCAN | PK_DEPT | 4 | | 1 (0)| 00
|* 4 | SORT JOIN | | 14 | 532 | 4 (25)| 00
| 5 | TABLE ACCESS FULL | EMP | 14 | 532 | 3 (0)| 00
--------------------------------------------------------------------------------
3.2 ORDERED Hint
该hint 告诉Oracle 按照From后面的表的顺序来选择驱动表,Oracle 建议在选择驱动表上使用Leading,它更灵活一些。
SQL> select /*+ordered */ * from scott.dept t,scott.emp t1 where t.deptno=t1.deptno;
四. 表关联操作的Hint
4.1 USE_HASH,USE_NL,USE_MERGE hint
表之间的连接方式有三种。 具体参考blog:
多表连接的三种方式详解 HASH JOIN MERGE JOIN NESTED LOOP
在多表联合查询的时候,如果我们查看它的执行计划,就会发现里面有多表之间的连接方式。 之前打算在sqlplus中用执行计划的,但是格式看起来有点乱,就用Toad 做了3个截图。

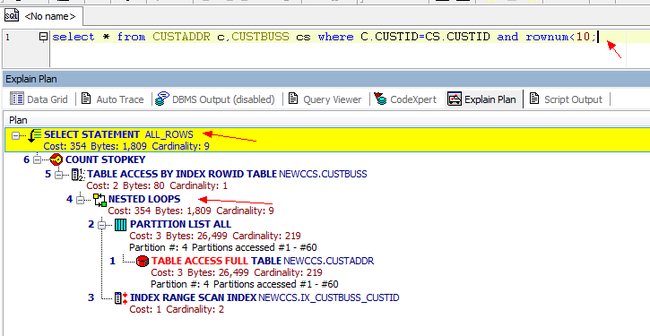
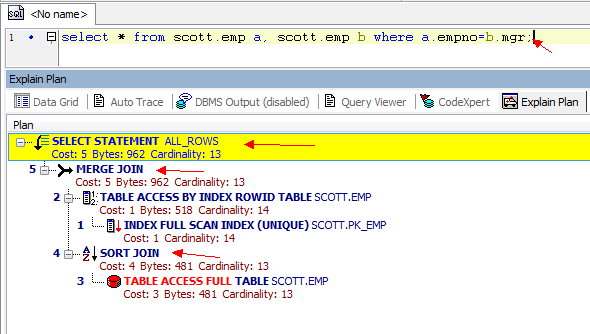
从3张图里我们看到了几点信息:
1. CBO 使用的ALL_ROWS模式
Oracle Optimizer CBO RBO
http://blog.csdn.net/tianlesoftware/archive/2010/08/19/5824886.aspx
2. 表之间的连接用了hash Join, Nested loops,Sort Merge Join
多表之间的连接有三种方式:Nested Loops,Hash Join 和 Sort Merge Join. 下面来介绍三种不同连接的不同:
一. NESTED LOOP:
对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1 万不适合),要把返回子集较小表的作为外表(CBO 默认外表是驱动表),而且在内表的连接字段上一定要有索引。当然也可以用ORDERED 提示来改变CBO默认的驱动表,使用USE_NL(table_name1 table_name2)可是强制CBO 执行嵌套循环连接。
Nested loop一般用在连接的表中有索引,并且索引选择性较好的时候.
步骤:确定一个驱动表(outer table),另一个表为inner table,驱动表中的每一行与inner表中的相应记录JOIN。类似一个嵌套的循环。适用于驱动表的记录集比较小(<10000)而且inner表需要有有效的访问方法(Index)。需要注意的是:JOIN的顺序很重要,驱动表的记录集一定要小,返回结果集的响应时间是最快的。
cost = outer access cost + (inner access cost * outer cardinality)
| 2 | NESTED LOOPS | | 3 | 141 | 7 (15)|
| 3 | TABLE ACCESS FULL | EMPLOYEES | 3 | 60 | 4 (25)|
| 4 | TABLE ACCESS BY INDEX ROWID| JOBS | 19 | 513 | 2 (50)|
| 5 | INDEX UNIQUE SCAN | JOB_ID_PK | 1 | | |
EMPLOYEES为outer table, JOBS为inner table.
二. HASH JOIN :
散列连接是CBO 做大数据集连接时的常用方式,优化器使用两个表中较小的表(或数据源)利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。
这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O 的性能。
也可以用USE_HASH(table_name1 table_name2)提示来强制使用散列连接。如果使用散列连接HASH_AREA_SIZE 初始化参数必须足够的大,如果是9i,Oracle建议使用SQL工作区自动管理,设置WORKAREA_SIZE_POLICY 为AUTO,然后调整PGA_AGGREGATE_TARGET 即可。
Hash join在两个表的数据量差别很大的时候.
步骤:将两个表中较小的一个在内存中构造一个HASH表(对JOIN KEY),扫描另一个表,同样对JOIN KEY进行HASH后探测是否可以JOIN。适用于记录集比较大的情况。需要注意的是:如果HASH表太大,无法一次构造在内存中,则分成若干个partition,写入磁盘的temporary segment,则会多一个写的代价,会降低效率。
cost = (outer access cost * # of hash partitions) + inner access cost
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 665 | 13300 | 8 (25)|
| 1 | HASH JOIN | | 665 | 13300 | 8 (25)|
| 2 | TABLE ACCESS FULL | ORDERS | 105 | 840 | 4 (25)|
| 3 | TABLE ACCESS FULL | ORDER_ITEMS | 665 | 7980 | 4 (25)|
--------------------------------------------------------------------------
ORDERS为HASH TABLE,ORDER_ITEMS扫描
三.SORT MERGE JOIN
通常情况下散列连接的效果都比排序合并连接要好,然而如果行源已经被排过序,在执行排序合并连接时不需要再排序了,这时排序合并连接的性能会优于散列连接。可以使用USE_MERGE(table_name1 table_name2)来强制使用排序合并连接.
Sort Merge join 用在没有索引,并且数据已经排序的情况.
cost = (outer access cost * # of hash partitions) + inner access cost
步骤:将两个表排序,然后将两个表合并。通常情况下,只有在以下情况发生时,才会使用此种JOIN方式:
1.RBO模式
2.不等价关联(>,<,>=,<=,<>)
3.HASH_JOIN_ENABLED=false
4.数据源已排序
四. 三种连接工作方式比较:
Hash join的工作方式是将一个表(通常是小一点的那个表)做hash运算,将列数据存储到hash列表中,从另一个表中抽取记录,做hash运算,到hash 列表中找到相应的值,做匹配。
Nested loops 工作方式是从一张表中读取数据,访问另一张表(通常是索引)来做匹配,nested loops适用的场合是当一个关联表比较小的时候,效率会更高。
Merge Join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配,因为merge join需要做更多的排序,所以消耗的资源更多。 通常来讲,能够使用merge join的地方,hash join都可以发挥更好的性能。
这三种关联方式是多表关联中主要使用的关联方式。 通常来说,当两个表都比较大时,Hash Join的效率要高于嵌套循环(nested loops)的关联方式。
Hash join的工作方式是将一个表(通常是小一点的那个表)做hash运算,将列数据存储到hash列表中,从另一个表中抽取记录,做hash运算,到hash 列表中找到相应的值,做匹配。
Nested loops 工作方式是从一张表中读取数据,访问另一张表(通常是索引)来做匹配,nested loops适用的场合是当一个关联表比较小的时候,效率会更高。
Merge Join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配,因为merge join需要做更多的排序,所以消耗的资源更多。 通常来讲,能够使用merge join的地方,hash join都可以发挥更好的性能。
USE_HASH,USE_NL,USE_MERGE 这三种hint 就是告诉优化器使用哪种关联方式。
示例如下:
SQL> select /*+use_hash(t,t1) */ * from scott.dept t,scott.emp t1 where t.deptno=t1.deptno;
SQL> select /*+use_nl(t,t1) */ * from scott.dept t,scott.emp t1 where t.deptno=t1.deptno;
SQL> select /*+use_merge(t,t1) */ * from scott.dept t,scott.emp t1 where t.deptno=t1.deptno;
4.2 NO_USE_HASH,NO_USE_NL,NO_USE_MERGE HINT
分别禁用对应的关联方式。
示例:
SQL> select /*+no_use_merge(t,t1) */ * from scott.dept t,scott.emp t1 where t.deptno=t1.deptno;
SQL> select /*+no_use_nl(t,t1) */ * from scott.dept t,scott.emp t1 where t.deptno=t1.deptno;
SQL> select /*+no_use_hash(t,t1) */ * from scott.dept t,scott.emp t1 where t.deptno=t1.deptno;
五. 并行执行相关的Hint
5.1 PARALLEL HINT
指定SQL 执行的并行度,这个值会覆盖表自身设定的并行度,如果这个值为default,CBO使用系统参数值。
示例:
SQL> select /*+parallel(t 4) */ * from scott.dept t;
关于表的并行度,我们在创建表的时候可以指定,如:
SQL> CREATE TABLE Anqing
2 (
3 name VARCHAR2 (10)
4 )
5 PARALLEL 2;
表已创建。
SQL> select degree from all_tables where table_name = 'ANQING'; -- 查看表的并行度
DEGREE
--------------------
2
SQL> alter table anqing parallel(degree 3); -- 修改表的并行度
表已更改。
SQL> select degree from all_tables where table_name = 'ANQING';
DEGREE
--------------------
3
SQL> alter table anqing noparallel; -- 取消表的并行度
表已更改。
SQL> select degree from all_tables where table_name = 'ANQING';
DEGREE
--------------------
1
5.2 NO_PARALLEL HINT
在SQL中禁止使用并行。
示例:
SQL> select /*+ no_parallel(t) */ * from scott.dept t;
六. 其他方面的一些Hint
6.1 APPEND HINT
提示数据库以直接加载的方式(direct load)将数据加载入库。
示例:
Insert /*+append */ into t as select * from all_objects;
这个hint 用的比较多。 尤其在插入大量的数据,一般都会用此hint。
Oracle 插入大量数据
1. 采用高速的存储设备,提高读写能力,如:EMC 和NetApp,
2. 假如tab1表中的没有数据的话
DROP TABLE TAB1;
CREATE TABLE TAB1 AS SELECT * FROM TAB2;
然后在创建索引
3. 用Hint 提示减少操作时间
INSERT /*+Append*/ INTO tab1
SELECT * FROM tab2;
4. 采用不写日志及使用Hint提示减少数据操作的时间。
建议方案是先修改表为不写日志:
sql> alter table table_name NOLOGGING;
插入数据:
INSERT /*+Append*/ INTO tab1
SELECT * FROM tab2;
插入完数据后,再修改表写日志:
sql> alter table table_name LOGGING;
这里的区别就在于如果插入数据的同时又写日志,尤其是大数据量的insert操作,需要耗费较长的时间。
5. 用EXP/IMP 处理大量数据
(1)给当前的两个表分别改名
alter table tab1 rename to tab11;
alter table tab2 rename to tab1;
(2)导出改名前的tab2
exp user/pwd@... file=... log=... tables=(tab1)
(3)把名字改回来
alter table tab1 rename to tab2;
alter table tab11 rename to tab1;
(4)导入数据
imp user/pwd@... file=... log=... fromuser=user touser=user tables=(tab1)
6.2 DYNAMIC_SAMPLING HINT
提示SQL 执行时动态采样的级别。 这个级别从0-10,它将覆盖系统默认的动态采样级别。
示例:
SQL> select /*+ dynamic_sampling(t 2) */ * from scott.emp t where t.empno>0;
6.3 DRIVING_SITE HINT
这个提示在分布式数据库操作中比较有用,比如我们需要关联本地的一张表和远程的表:
Select /* + driving_site(departmetns) */ * from employees,departments@dblink where
employees .department_id = departments.department_id;
如果没有这个提示,Oracle 会在远端机器上执行departments 表查询,将结果送回本地,再和employees表关联。 如果使用driving_site(departments), Oracle将查询本地表employees,将结果送到远端,在远端将数据库上的表与departments关联,然后将查询的结果返回本地。
如果departments查询结果很大,或者employees查询结果很小,并且两张表关联之后的结果集很小,那么就可以考虑把本地的结果集发送到远端。 在远端执行完后,在将较小的最终结果返回本地。
6.4 CACHE HINT
在全表扫描操作中,如果使用这个提示,Oracle 会将扫描的到的数据块放到LRU(least recently Used: 最近很少被使用列表,是Oracle 判断内存中数据块活跃程度的一个算法)列表的最被使用端(数据块最活跃端),这样数据块就可以更长时间地驻留在内存当中。 如果有一个经常被访问的小表,这个设置会提高查询的性能;同时CACHE也是表的一个属性,如果设置了表的cache属性,它的作用和hint一样,在一次全表扫描之后,数据块保留在LRU列表的最活跃端。
示例:
SQL> select /*+full(t) cache (t) */ * from scott.emp;
小结:
对于DBA来讲,掌握一些Hint操作,在实际性能优化中有很大的好处,比如我们发现一条SQL的执行效率很低,首先我们应当查看当前SQL的执行计划,然后通过hint的方式来改变SQL的执行计划,比较这两条SQL 的效率,作出哪种执行计划更优,如果当前执行计划不是最优的,那么就需要考虑为什么CBO 选择了错误的执行计划。当CBO 选择错误的执行计划,我们需要考虑表的分析是否是最新的,是否对相关的列做了直方图,是否对分区表做了全局或者分区分析等因素。
关于执行计划参考:
Oracle Explain Plan
http://blog.csdn.net/tianlesoftware/archive/2010/08/20/5827245.aspx
总之,在处理问题时,我们要把问题掌握在可控的范围内,不能将问题扩大化,甚至失控。 作为一个DBA,需要的扎实的基本功,还有胆大心细,遇事不慌。