开源项目:高级SQL Server监控、性能图、分析与优化、版本控制
这是一个相当高级的SQL Server监控工具,全面监控SQL Server的活动与性能,分析性能瓶颈,给出优化建议。
red-gate有一个在线的数据库监控工具,不过那个商业的东西价钱不便宜。我写的这个平民版,开源,功能上有颇多的差异(各有长短)。
项目在Codeplex上开源:http://sqlmon.codeplex.com/
在Codeproject上有英文介绍:http://www.codeproject.com/KB/database/sqlmonitor.aspx
介绍
是否想过:“SQL Server为什么那么慢?”,“为什么CPU占用那么高?”,“到底哪里死锁了?”,“为什么数据库那么大?”,“怎样才可以查看我的存储过程和函数的历史版本?”,“可以让我的SQL Server跑得更快吗?”。
你的答案就在这里;-)
到底能干嘛
- 监控SQL Server的活动:进程、任务,详细查看当前执行的语句与实际变量值,终止进程
- IO/CPU/网络等性能趋势图
- 函数/存储过程等的版本控制,这在商业软件中也没有(如果你知道,告诉我)
- 对象浏览器:服务器、数据库、表、视图、函数、存储过程等
- 数据库管理:收缩、日志清除、备份、恢复等
- 在整个数据库中搜索对象/脚本内容,这在SQL Server 2012中也无法做到
- 自动显示所有对象的脚本,如表、视图、函数、存储过程等
概览
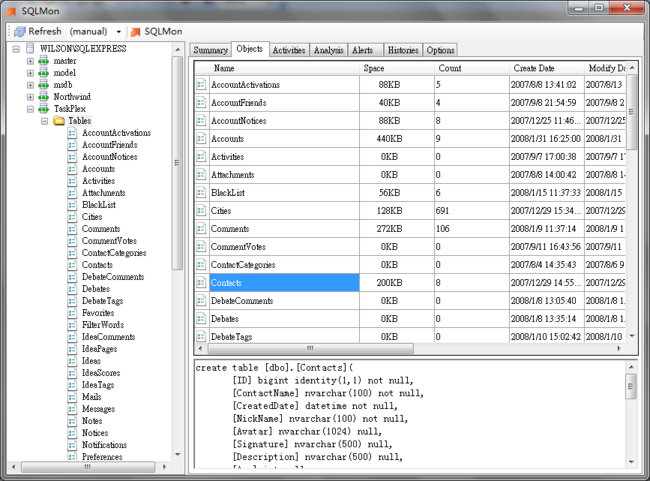
在上图中,我们可以看见表的create脚本。如果你选择其它对象,如函数、存储过程等,一样会显示相应的脚本。
在对象列表中,如果是数据表,显示表的占用空间(包括索引)、记录数等。
这些在SQL Server 2012中都没有。
获取数据库信息
对象/脚本搜索
Select s.name, s.create_date AS CreateDate, s.modify_date AS ModifyDate, s.type, c. text from syscomments c left join sys.objects s on c.id = s. object_id where [ Text ] like ' %YOUR_QUERY_HERE% '
-- search in jobs
SELECT job_id, name, date_created AS CreateDate, date_modified AS ModifyDate, ' Job ' AS type FROM msdb.dbo.sysjobs
获取表结构
SELECT
[ TableName ] = so.name,
[ RowCount ] = MAX(si.rows)
FROM
sysobjects so,
sysindexes si
WHERE
so.xtype = ' U '
AND
si.id = OBJECT_ID(so.name)
GROUP BY
so.name
-- To get table used space
EXEC sp_spaceused ' TABLE_NAME '
-- To get table script
declare @Id int, @i int, @i2 int, @Sql varchar( max), @Sql2 varchar( max), @f1 varchar( 5), @f2 varchar( 5), @f3 varchar( 5), @f4 varchar( 5), @T varchar( 5)
select @Id = object_id( ' YOUR_TABLE_NAME_HERE '), @f1 = char( 13) + char( 10), @f2 = ' ', @f3 = @f1 + @f2, @f4 = ' , ' + @f3
if not( @Id is null)
BEGIN
declare @Data table(Id int identity primary key, D varchar( max) not null, ic int null, re int null, o int not null);
-- Columns
with c as(
select c.column_id, Nr = row_number() over( order by c.column_id), Clr = count( *) over(),
D = quotename(c.name) + ' ' +
case when s.name = ' sys ' or c.is_computed = 1 then '' else quotename(s.name) + ' . ' end +
case when c.is_computed = 1 then '' when s.name = ' sys ' then t.Name else quotename(t.name) end +
case when c.user_type_id !=c.system_type_id or c.is_computed = 1 then ''
when t.Name in ( ' xml ', ' uniqueidentifier ', ' tinyint ', ' timestamp ', ' time ', ' text ', ' sysname ', ' sql_variant ', ' smallmoney ', ' smallint ', ' smalldatetime ', ' ntext ', ' money ',
' int ', ' image ', ' hierarchyid ', ' geometry ', ' geography ', ' float ', ' datetimeoffset ', ' datetime2 ', ' datetime ', ' date ', ' bigint ', ' bit ') then ''
when t.Name in( ' varchar ', ' varbinary ', ' real ', ' numeric ', ' decimal ', ' char ', ' binary ')
then ' ( ' + isnull( convert( varchar, nullif(c.max_length, - 1)), ' max ') + isnull( ' , ' + convert( varchar, nullif(c.scale, 0)), '') + ' ) '
when t.Name in( ' nvarchar ', ' nchar ')
then ' ( ' + isnull( convert( varchar, nullif(c.max_length, - 1) / 2), ' max ') + isnull( ' , ' + convert( varchar, nullif(c.scale, 0)), '') + ' ) '
else ' ?? '
end +
case when ic. object_id is not null then ' identity( ' + convert( varchar,ic.seed_value) + ' , ' + convert( varchar,ic.increment_value) + ' ) ' else '' end +
case when c.is_computed = 1 then ' as ' + cc.definition when c.is_nullable = 1 then ' null ' else ' not null ' end +
case c.is_rowguidcol when 1 then ' rowguidcol ' else '' end +
case when d. object_id is not null then ' default ' + d.definition else '' end
from sys.columns c
inner join sys.types t
on t.user_type_id = c.user_type_id
inner join sys.schemas s
on s.schema_id =t.schema_id
left outer join sys.computed_columns cc
on cc. object_id =c. object_id and cc.column_id =c.column_id
left outer join sys.default_constraints d
on d.parent_object_id = @id and d.parent_column_id =c.column_id
left outer join sys.identity_columns ic
on ic. object_id =c. object_id and ic.column_id =c.column_id
where c. object_id = @Id
)
insert into @Data(D, o)
select ' ' + D + case Nr when Clr then '' else ' , ' + @f1 end, 0
from c where NOT D IS NULL
order by column_id
-- SubObjects
set @i = 0
while 1 = 1
begin
select top 1 @i =c. object_id, @T = c.type, @i2 =i.index_id
from sys.objects c
left outer join sys.indexes i
on i. object_id = @Id and i.name =c.name
where parent_object_id = @Id and c. object_id > @i and c.type not in( ' D ')
order by c. object_id
if @@rowcount = 0 break
if @T = ' C '
insert into @Data
select @f4 + ' check ' + case is_not_for_replication when 1 then ' not for replication ' else '' end + definition, null, null, 10
from sys.check_constraints where object_id = @i
else if @T = ' Pk '
insert into @Data
select @f4 + ' primary key ' + isnull( ' ' + nullif( lower(i.type_desc), ' clustered '), ''), @i2, null, 20
from sys.indexes i
where i. object_id = @Id and i.index_id = @i2
else if @T = ' uq '
insert into @Data values( @f4 + ' unique ', @i2, null, 30)
else if @T = ' f '
begin
insert into @Data
select @f4 + ' foreign key ', - 1, @i, 40
from sys.foreign_keys f
where f. object_id = @i
insert into @Data
select ' references ' + quotename(s.name) + ' . ' + quotename(o.name), - 2, @i, 41
from sys.foreign_keys f
inner join sys.objects o
on o. object_id =f.referenced_object_id
inner join sys.schemas s
on s.schema_id =o.schema_id
where f. object_id = @i
insert into @Data
select ' not for replication ', - 3, @i, 42
from sys.foreign_keys f
inner join sys.objects o
on o. object_id =f.referenced_object_id
inner join sys.schemas s
on s.schema_id =o.schema_id
where f. object_id = @i and f.is_not_for_replication = 1
end
else
insert into @Data values( @f4 + ' Unknow SubObject [ ' + @T + ' ] ', null, null, 99)
end
insert into @Data values( @f1 + ' ) ', null, null, 100)
-- Indexes
insert into @Data
select @f1 + ' create ' + case is_unique when 1 then ' unique ' else '' end + lower(s.type_desc) + ' index ' + ' i ' + convert( varchar, row_number() over( order by index_id)) + ' on ' + quotename(sc.Name) + ' . ' + quotename(o.name), index_id, null, 1000
from sys.indexes s
inner join sys.objects o
on o. object_id =s. object_id
inner join sys.schemas sc
on sc.schema_id =o.schema_id
where s. object_id = @Id and is_unique_constraint = 0 and is_primary_key = 0 and s.type_desc != ' heap '
-- columns
set @i = 0
while 1 = 1
begin
select top 1 @i =ic from @Data where ic > @i order by ic
if @@rowcount = 0 break
select @i2 = 0, @Sql = null, @Sql2 = null
while 1 = 1
begin
select @i2 =index_column_id,
@Sql = case c.is_included_column when 1 then @Sql else isnull( @Sql + ' , ', ' ( ') + cc.Name + case c.is_descending_key when 1 then ' desc ' else '' end end,
@Sql2 = case c.is_included_column when 0 then @Sql2 else isnull( @Sql2 + ' , ', ' ( ') + cc.Name + case c.is_descending_key when 1 then ' desc ' else '' end end
from sys.index_columns c
inner join sys.columns cc
on c.column_id =cc.column_id and cc. object_id =c. object_id
where c. object_id = @Id and index_id = @i and index_column_id > @i2
order by index_column_id
if @@rowcount = 0 break
end
update @Data set D =D + @Sql + ' ) ' + isnull( ' include ' + @Sql2 + ' ) ', '') where ic = @i
end
-- references
set @i = 0
while 1 = 1
begin
select top 1 @i =re from @Data where re > @i order by re
if @@rowcount = 0 break
select @i2 = 0, @Sql = null, @Sql2 = null
while 1 = 1
begin
select @i2 =f.constraint_column_id,
@Sql = isnull( @Sql + ' , ', ' ( ') + c1.Name,
@Sql2 = isnull( @Sql2 + ' , ', ' ( ') + c2.Name
from sys.foreign_key_columns f
inner join sys.columns c1
on c1.column_id =f.parent_column_id and c1. object_id =f.parent_object_id
inner join sys.columns c2
on c2.column_id =f.referenced_column_id and c2. object_id =f.referenced_object_id
where f.constraint_object_id = @i and f.constraint_column_id > @i2
order by f.constraint_column_id
if @@rowcount = 0 break
end
update @Data set D = D + @Sql + ' ) ' where re = @i and ic =- 1
update @Data set D = D + @Sql2 + ' ) ' where re = @i and ic =- 2
end;
-- Render
with x as(
select id =d.id - 1, D =d.D + isnull(d2.D, '')
from @Data d
left outer join @Data d2
on d.re =d2.re and d2.o = 42
where d.o = 41
)
update @Data
set D =d.D +x.D
from @Data d
inner join x
on x.id =d.id
delete @Data where o in( 41, 42)
select @Sql = ' create table ' + quotename(s.name) + ' . ' + quotename(o.name) + ' ( ' + @f1
from sys.objects o
inner join sys.schemas s
on o.schema_id = s.schema_id
where o. object_id = @Id
set @i = 0
while 1 = 1
begin
select top 1 @I =Id, @Sql = @Sql + D from @Data order by o, case when o = 0 then right( ' 0000 ' + convert( varchar,id), 5) else D end, id
if @@rowcount = 0 break
delete @Data where id = @i
end
END
SELECT @Sql
性能趋势图
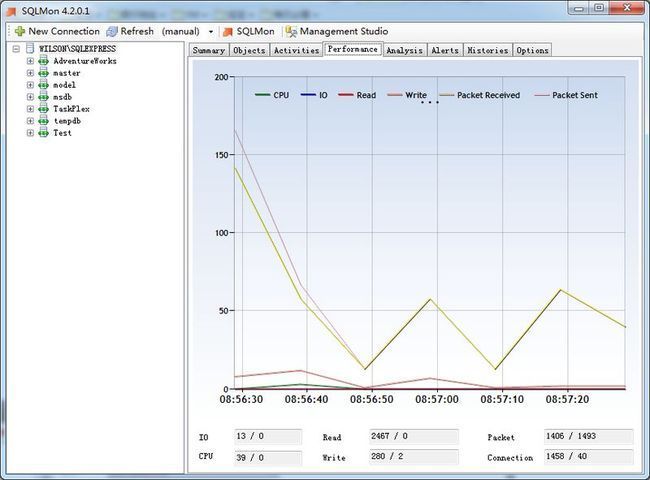
在上图中,我们可以看见SQL Server历史/当前的IO/CPU/网络信息都在趋势图中显示。
这些数据来自几个系统变量:
- @@cpu_busy
- @@io_busy
- @@idle
- @@pack_received
- @@pack_sent
- @@connections
- @@packet_errors
- @@total_read
- @@total_write
- @@total_errors
以下是相应的SQL:
declare @cpu_busy int
declare @io_busy int
declare @idle int
declare @pack_received int
declare @pack_sent int
declare @pack_errors int
declare @connections int
declare @total_read int
declare @total_write int
declare @total_errors int
declare @oldcpu_busy int /* used to see if DataServer has been rebooted */
declare @interval int
declare @mspertick int /* milliseconds per tick */
/*
** Set @mspertick. This is just used to make the numbers easier to handle
** and avoid overflow.
*/
select @mspertick = convert( int, @@timeticks / 1000.0)
/*
** Get current monitor values.
*/
select
@now = getdate(),
@cpu_busy = @@cpu_busy,
@io_busy = @@io_busy,
@idle = @@idle,
@pack_received = @@pack_received,
@pack_sent = @@pack_sent,
@connections = @@connections,
@pack_errors = @@packet_errors,
@total_read = @@total_read,
@total_write = @@total_write,
@total_errors = @@total_errors
/*
** Check to see if DataServer has been rebooted. If it has then the
** value of @@cpu_busy will be less than the value of spt_monitor.cpu_busy.
** If it has update spt_monitor.
*/
select @oldcpu_busy = cpu_busy
from master.dbo.spt_monitor
if @oldcpu_busy > @cpu_busy
begin
update master.dbo.spt_monitor
set
lastrun = @now,
cpu_busy = @cpu_busy,
io_busy = @io_busy,
idle = @idle,
pack_received = @pack_received,
pack_sent = @pack_sent,
connections = @connections,
pack_errors = @pack_errors,
total_read = @total_read,
total_write = @total_write,
total_errors = @total_errors
end
/*
** Now print out old and new monitor values.
*/
set nocount on
select @interval = datediff(ss, lastrun, @now)
from master.dbo.spt_monitor
/* To prevent a divide by zero error when run for the first
** time after boot up
*/
if @interval = 0
select @interval = 1
select last_run = lastrun, current_run = @now, seconds = @interval,
cpu_busy_total = convert( int, (( @cpu_busy * @mspertick) / 1000)),
cpu_busy_current = convert( int, ((( @cpu_busy - cpu_busy)
* @mspertick) / 1000)),
cpu_busy_percentage = convert( int, (((( @cpu_busy - cpu_busy)
* @mspertick) / 1000) * 100) / @interval),
io_busy_total = convert( int, (( @io_busy * @mspertick) / 1000)),
io_busy_current = convert( int, ((( @io_busy - io_busy)
* @mspertick) / 1000)),
io_busy_percentage = convert( int, (((( @io_busy - io_busy)
* @mspertick) / 1000) * 100) / @interval),
idle_total = convert( int, (( convert( bigint, @idle) * @mspertick) / 1000)),
idle_current = convert( int, ((( @idle - idle)
* @mspertick) / 1000)),
idle_percentage = convert( int, (((( @idle - idle)
* @mspertick) / 1000) * 100) / @interval),
packets_received_total = @pack_received,
packets_received_current = @pack_received - pack_received,
packets_sent_total = @pack_sent,
packets_sent_current = @pack_sent - pack_sent,
packet_errors_total = @pack_errors,
packet_errors_current = @pack_errors - pack_errors,
total_read = @total_read,
current_read = @total_read - total_read,
total_write = @total_write,
current_write = @total_write - total_write,
total_errors = @total_errors,
current_errors = @total_errors - total_errors,
connections_total = @connections,
connections_current = @connections - connections
from master.dbo.spt_monitor
/*
** Now update spt_monitor
*/
update master.dbo.spt_monitor
set
lastrun = @now,
cpu_busy = @cpu_busy,
io_busy = @io_busy,
idle = @idle,
pack_received = @pack_received,
pack_sent = @pack_sent,
connections = @connections,
pack_errors = @pack_errors,
total_read = @total_read,
total_write = @total_write,
total_errors = @total_errors
版本控制
数据库开发人员总在想,每次修改了函数/存储过程,我们都得自己做备份,用以历史参考,当发现错误的时候,可以回滚。在SQL Monitor里面,这个是全自动的。
版本控制的思想来自这里:http://www.sqlteam.com/article/using-ddl-triggers-in-sql-server-2005-to-capture-schema-changes
原理就是用数据库DDL触发器记录每个DDL操作,自增版本,并存储到一个表中。
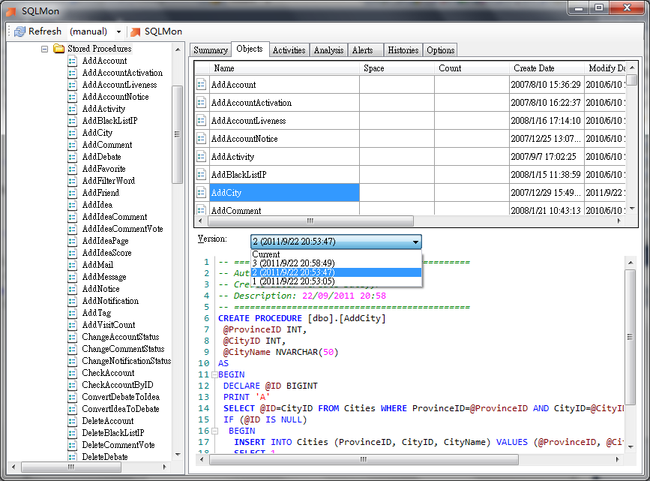
关键代码
GO
SET QUOTED_IDENTIFIER OFF
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
IF NOT EXISTS ( SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N ' [dbo].[VERSION_CONTROL_TABLE] ') AND type in (N ' U '))
BEGIN
CREATE TABLE [ dbo ]. [ {0} ](
[ ID ] [ bigint ] IDENTITY( 1, 1) NOT NULL,
[ databasename ] [ varchar ]( 256) NULL,
[ eventtype ] [ varchar ]( 50) NULL,
[ objectname ] [ varchar ]( 256) NULL,
[ objecttype ] [ varchar ]( 25) NULL,
[ sqlcommand ] [ nvarchar ]( max) NULL,
[ loginname ] [ varchar ]( 256) NULL,
[ hostname ] [ varchar ]( 256) NULL,
[ PostTime ] [ datetime ] NULL,
[ Version ] [ int ] NOT NULL,
CONSTRAINT [ PK_VERSION_CONTROL_TABLE ] PRIMARY KEY CLUSTERED
(
[ ID ] ASC
) WITH (IGNORE_DUP_KEY = OFF) ON [ PRIMARY ]
) ON [ PRIMARY ]
END
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TRIGGER [ TRG_VERSION_CONTROL_TABLE} ]
ON DATABASE
FOR CREATE_PROCEDURE, ALTER_PROCEDURE, DROP_PROCEDURE,
CREATE_TABLE, ALTER_TABLE, DROP_TABLE,
CREATE_FUNCTION, ALTER_FUNCTION, DROP_FUNCTION,
CREATE_TRIGGER, ALTER_TRIGGER, DROP_TRIGGER,
CREATE_VIEW, ALTER_VIEW, DROP_VIEW,
CREATE_INDEX, ALTER_INDEX, DROP_INDEX
AS
SET NOCOUNT ON
DECLARE @CurrentVersion int
DECLARE @CurrentID int
DECLARE @DatabaseName varchar( 256)
DECLARE @ObjectName varchar( 256)
DECLARE @data XML
SET @data = EVENTDATA()
INSERT INTO dbo.VERSION_CONTROL_TABLE(databasename, eventtype,objectname, objecttype, sqlcommand, loginname,Hostname,PostTime, Version)
VALUES(
@data.value( ' (/EVENT_INSTANCE/DatabaseName)[1] ', ' varchar(256) '),
@data.value( ' (/EVENT_INSTANCE/EventType)[1] ', ' varchar(50) '), -- value is case-sensitive
@data.value( ' (/EVENT_INSTANCE/ObjectName)[1] ', ' varchar(256) '),
@data.value( ' (/EVENT_INSTANCE/ObjectType)[1] ', ' varchar(25) '),
@data.value( ' (/EVENT_INSTANCE/TSQLCommand)[1] ', ' varchar(max) '),
@data.value( ' (/EVENT_INSTANCE/LoginName)[1] ', ' varchar(256) '),
HOST_NAME(),
GETDATE(),
0
)
SET @CurrentID = IDENT_CURRENT( ' VERSION_CONTROL_TABLE ')
SELECT @DatabaseName = databasename, @ObjectName = objectname FROM VERSION_CONTROL_TABLE WHERE ID = @CurrentID
IF ( @DatabaseName IS NOT NULL AND @ObjectName IS NOT NULL)
BEGIN
SELECT @CurrentVersion = MAX(Version) FROM VERSION_CONTROL_TABLE WHERE databasename = @DatabaseName AND objectname = @ObjectName
UPDATE VERSION_CONTROL_TABLE SET Version = ISNULL( @CurrentVersion, 0) + 1 WHERE ID = @CurrentID
END
GO
ENABLE TRIGGER [ TRG_VERSION_CONTROL_TABLE ] ON DATABASE
SQL Monitor会全自动给你的所有脚本修改做版本记录。你可以随时查看在什么时候哪个机器用什么身份修改了哪个对象的脚本。
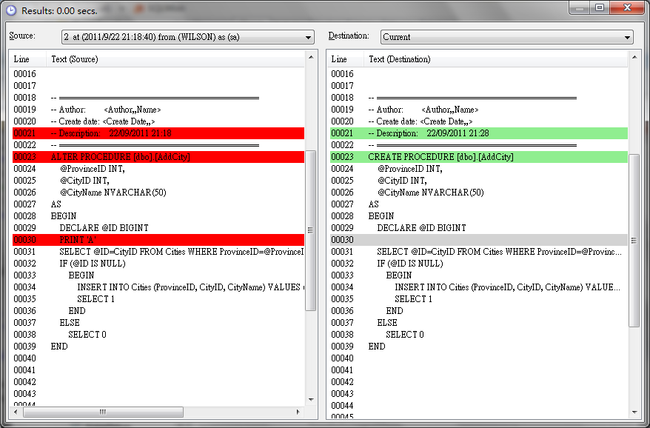
SQL Monitor内置版本比较,你可以清楚知道不同的版本的差异。
活动监控
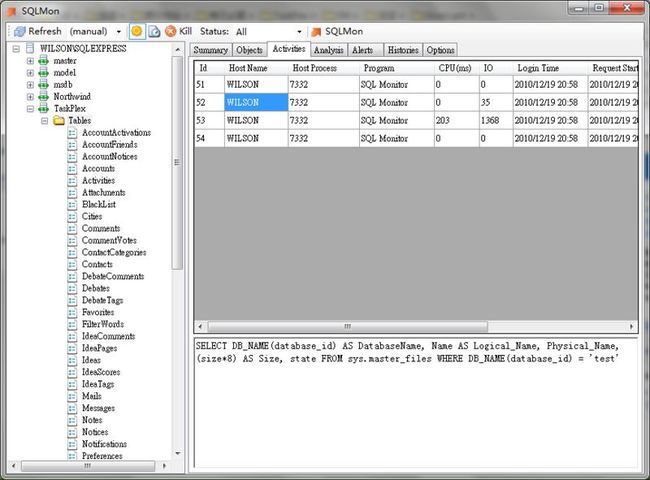
上图清晰显示所有系统的活动进程,每个进程当前执行什么语句。
获取进程列表
SELECT s.session_id AS spid, s.login_time, s. host_name AS hostname, s.host_process_id AS hostprocess, s.login_name AS loginname, s.logical_reads AS physical_io, s.cpu_time AS cpu, s.program_name, 0 AS dbid, s.last_request_start_time AS last_batch_begin, CASE WHEN status = ' running ' THEN GETDATE() ELSE dateadd(ms, s.cpu_time, s.last_request_end_time) END AS last_batch_end, s.status FROM sys.dm_exec_sessions s JOIN sys.dm_exec_connections c ON s.session_id = c.session_id
获取任务列表
SELECT job_id AS spid, name AS program_name, 0 AS dbid, 0 AS cpu, 0 AS physical_io, NULL AS login_time, NULL AS last_batch_begin, NULL AS last_batch_end, NULL AS status, NULL AS hostname, NULL AS hostprocess, NULL AS cmd, NULL AS loginname FROM msdb.dbo.sysjobs
分析
这是商业级的数据与性能分析,SQL Monitor自动给你的系统、数据库、数据表、索引等进行分析。
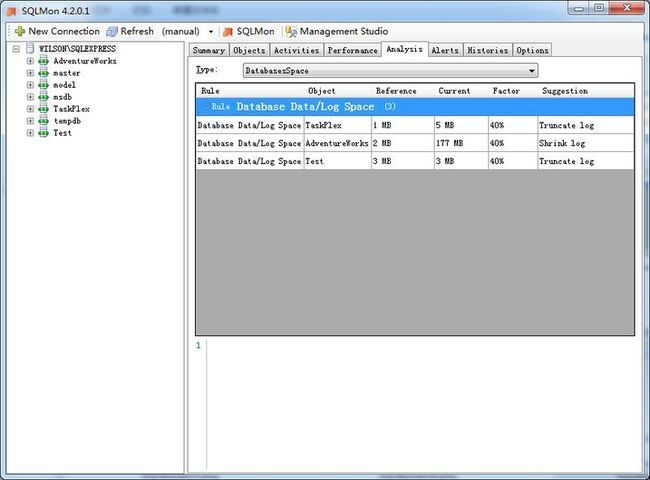
基本原理是首先利用master.sys.xp_fixeddrives获取磁盘的剩余空间,然后:
var databases = GetDatabasesInfo();
var files = new List <tuple <bool, />>();
databases.AsEnumerable().ForEach(d =>
{
var database = GetDatabaseInfo(d [ "name" ].ToString());
database.AsEnumerable().ForEach(f =>
{
files. Add(new Tuple <bool, />( Convert.ToInt32(f [ "type" ]) == 1, f [ "physical_name" ].ToString(), Convert.ToInt64( Convert.ToDecimal(f [ "Size" ]) / Size1K)));
}
);
});
var spaces = new Dictionary <string, />>();
//MB free
var driveSpaces = Query(" EXEC master.sys.xp_fixeddrives");
driveSpaces.AsEnumerable().ForEach(s =>
{
//could not use name but rather index, because the column name will change according to locale
spaces. Add(s [ 0 ].ToString(), new KeyValue < long, />( Convert.ToInt64(s [ 1 ]), 0));
});
files.ForEach(f =>
{
//maybe some access issues
try
{
var drive = f.Item2. Substring( 0, 1);
if (spaces.ContainsKey(drive))
{
spaces [ drive ].Value += f.Item3;
}
}
catch (Exception)
{
//mmmm.....what can we do, mate?
}
});
spaces.ForEach(s =>
{
if (s.Value. Key < s.Value.Value / 100 * Settings.Instance.DatabaseDiskFreeSpaceRatio)
{
analysisResult. Add(new AnalysisResult { ResultType = AnalysisResultTypes.DiskFreeSpace, ObjectName = s. Key, ReferenceValue = s.Value. Key, CurrentValue = s.Value.Value, Factor = Settings.Instance.DatabaseDiskFreeSpaceRatio + SizePercentage });
}
});
// database data file & log file space
databases.AsEnumerable().ForEach(d =>
{
var name = d [ "name" ].ToString();
if (!systemDatabases. Contains(name))
{
var database = GetDatabaseInfo(name);
var databaseSpace = new Dictionary <databasefiletypes, /> { { DatabaseFileTypes.Data, 0 }, { DatabaseFileTypes. Log, 0 } };
database.AsEnumerable().ForEach(f =>
{
var key = (DatabaseFileTypes) Convert.ToInt32(f [ "type" ]);
databaseSpace [ key ] += Convert.ToInt64( Convert.ToDecimal(f [ "Size" ]) / Size1K);
}
);
bool? shrink = null;
if (databaseSpace [ DatabaseFileTypes.Log ] > databaseSpace [ DatabaseFileTypes.Data ] / 100 * Settings.Instance.DatabaseDataLogSpaceRatio)
shrink = false;
else
{
var logSpaces = SQLHelper.Query(" DBCC SQLPERF(LOGSPACE)", GetServerInfo(name));
var logSpace = logSpaces. Select(string.Format(" [ Database Name ] = ' {0} '", name));
if (logSpace.Length > 0)
{
var logSpacedUsed = Convert.ToDouble(logSpace [ 0 ][ "Log Space Used (%)" ]);
if (logSpacedUsed < Settings.Instance.DatabaseDataLogSpaceRatio)
shrink = true;
}
}
if (shrink != null)
analysisResult. Add(new AnalysisResult { ResultType = AnalysisResultTypes.DatabaseLogSpace, ObjectName = name, ReferenceValue = databaseSpace [ DatabaseFileTypes.Log ], CurrentValue = databaseSpace [ DatabaseFileTypes.Data ], Factor = Settings.Instance.DatabaseDataLogSpaceRatio + SizePercentage, Key = (bool)shrink ? 1 : 0 });
}
});
对于表空间,使用了sp_spaceused,关键代码:
tables.AsEnumerable().ForEach(t =>
{
var name = t [ KeyName ].ToString();
var space = Query(string.Format(" EXEC sp_spaceused ' {0} '", name), CurrentServerInfo);
if ( space.Rows. Count > 0)
{
var row = space.Rows [ 0 ];
var dataSize = ToKB(row [ "data" ]) / Size1K;
var indexSize = ToKB(row [ "index_size" ]) / Size1K;
if (indexSize > dataSize / 100 * Settings.Instance.TableDataIndexSpaceRatio)
analysisResult. Add(new AnalysisResult { ResultType = AnalysisResultTypes.TableIndexSpace, ObjectName = name, ReferenceValue = dataSize, CurrentValue = indexSize, Factor = Settings.Instance.DatabaseDataLogSpaceRatio + SizePercentage, Key = ( int)TableIndexSpaceRules.DataIndexSpaceRatio });
}
});
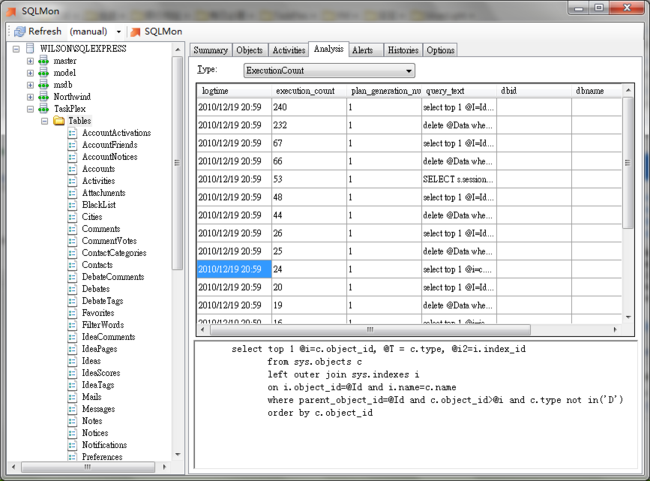
最新版本
http://sqlmon.codeplex.com/releases/view/77943