WebSphere应用服务器内存泄漏探测与诊断工具选择最佳实践
<!--START RESERVED FOR FUTURE USE INCLUDE FILES--><!-- include java script once we verify teams wants to use this and it will work on dbcs and cyrillic characters --><!--END RESERVED FOR FUTURE USE INCLUDE FILES-->自:http://blog.chinaunix.net/u1/57765/showart_450998.html
本文介绍了如何在WebSphere应用服务器中实现应用程序内存泄漏的探测,并且针对IBM所提供的系列分析与诊断工具,给出了具体的配置步骤和使用最佳实践。
内存泄漏是比较常见的一种应用程序性能问题,一旦发生,则系统的可用内存和性能持续下降;最终将导致内存不足(OutOfMemory),系统彻底宕掉,不能响应任何请求,其危害相当严重。同时,Java堆(Heap)中大量的对象以及对象间之复杂关系,导致内存泄漏问题的探测和分析均比较困难,采用相应的辅助工具是很必要的。
WebSphere应用服务器提供了系列针对内存问题的探测和分析诊断工具,这些工具可以帮助用户进行内存问题的及时探测,保证系统在发生OOM之前,用户可以在无须进行复杂分析的条件下,预知在其部署的应用中是否存在内存泄漏的问题。如果确有内存泄漏现象发生,WebSphere还提供了相应的工具,可以帮助用户进行分析诊断,从而找到内存泄漏的真正原因。
实践中,我们可以采用以下的步骤来处理内存泄漏的问题:

(1) 首先,在WebSphere中我们启用实时探测内存泄漏工具, WebSphere性能诊断顾问会对内存泄漏提前发出警告信息。
(2) 启用WebSphere自带的Tivoli性能查看器监视系统的JVM使用状况,确定内存泄漏是否正在发生。
(3) 根据需要,生成详细内存回收日志,使用PMAT工具分析并确定泄漏的时间,周期等。
(4) 生成单个或者多个Heapdump文件,选用MDD4J进行分析诊断,找到内存泄漏的真正原因。
(5) 提交开发部门进行代码修复,然后重新部署到WebSphere应用服务器。
接下来的部分,我们针对每个环节的配置和工具使用进行阐述。
| |
|
性能诊断顾问(Performance and Diagnostic Advisor),在WebSphere应用服务器6.0.2版本之前称为运行时性能顾问(Runtime Performance Advisor)。该工具可以周期性的检查WebSphere的设置,并给出调整的推荐值。自WebSphere应用服务器6.0.2版本开始,该工具实现了一种轻量级的内存探测机制,可以非常容易的帮助用户探测是否在系统中存在内存泄漏问题,并提前通过日志和管理控制台进行通知。这样就给用户以足够的时间采取必要的措施防止系统宕掉,同时可以收集或生成相关的文件以进行离线的分析,来查找泄漏的根本原因。
可以在WebSphere应用服务器的管理控制台中启用性能诊断顾问
(1) 访问管理控制台 ->服务器-> 应用程序服务器。
(2) 选择所要配置的服务器。
(3) 在性能区域,选择性能和诊断顾问程序配置。
(4) 如图所示,有两个Tab, 运行时和配置。区别在于,运行时里面的内容无须重启服务器就可以生效,但下次重启服务器的时候,这些配置也会丢失。配置Tab里面的内容只有在服务器重启后才生效,而且配置的内容也会一直存在,除非再次登陆并去掉所选项。
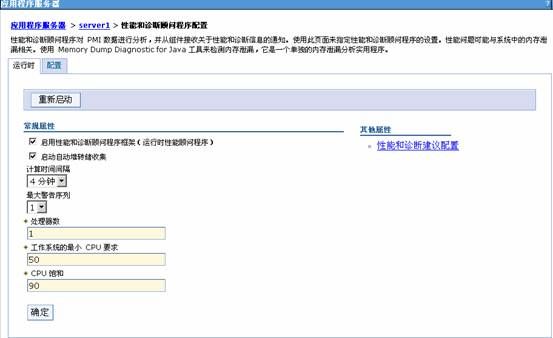
(5)在其他属性区域,点击性能和诊断建议配置,确保内存泄漏规则处于运行状态(绿色箭头)。
![]()
WebSphere性能诊断顾问输出信息可以显示在WebSphere的管理控制台,并记录在WebSphere应用服务器的SystemOut.log日志文件里面。
(1) SystemOut.log日志
[8/31/06 13:21:43:545 CST] 00000010 TraceResponse W TUNE9001W: Heap utilization patterns indicate that you may have a memory leak Additional explanatory data follows. Data values for free memory between 8/31/06 1:20 PM and 8/31/06 1:21 PM were consistently below minimum required percentage. |
(2) 管理控制台
-登陆管理控制台->故障诊断 ->运行时消息 ->点击运行时警告

| |
|
进一步检测是否有内存泄漏的发生,以及泄漏发生的时间,周期和速度,我们可以启用Java虚拟机中的详细垃圾回收,然后分析相应的日志。 WebSphere应用服务器6.1使用了Java SDK5.0, 在Window, Linux, AIX, i5/OS,z/Linux 和z/OS上使用了IBM的JAVA虚拟机, 在Solaris和HP-UX上使用Sun的JVM。Java 虚拟机概要分析工具接口(Java Virtual Machine Tool Interface,JVMTI)支持从运行应用程序服务器的 Java 虚拟机(JVM)收集信息(如,关于垃圾回收的数据、对象利用和线程状态)并且支持更全面的性能分析。一旦启用了 JVMTI,可以使用 PMI 定制选项来启用所选统计信息以收集特定数据。
配置步骤:
1. 在控制台导航树中单击服务器 > 应用程序服务器
2. 单击选择所需应用程序服务器。
3. 在"服务器基础结构"下,单击 Java 和进程管理-> 进程定义。
4. 在"其他属性"下,单击 Java 虚拟机。
5. 选中配置Tab的详细垃圾回收选项。
6. 在通用 JVM 参数字段中输入 -agentlib:pmiJvmtiProfiler。
注: WebSphere6.1中,JVM概要分析接口改为Java Virtual Machine Tool Interface (JVMTI)。之前版本是JVMPI。如果需要JVMPI的时候,也可以此处输入-XrunpmiJvmpiProfiler。另外,启用JVMTI接口对性能影响较大,尽量避免在生产环境中使用。
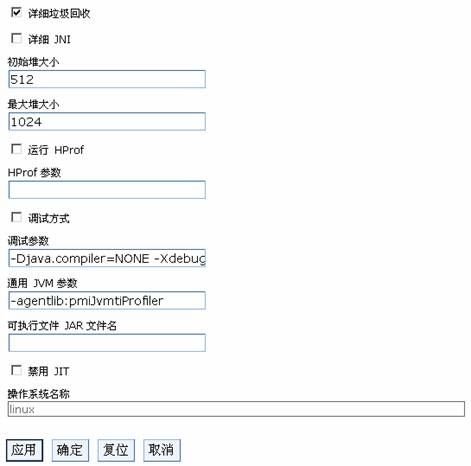
7.点击应用或者确定。
8. 单击保存按钮。
9.重启WebSphere应用服务器。
在WebSphere应用服务器的日志目录下,native_stderr.log文件就是我们需要的内存回收分析文件。我们推荐使用IBM Pattern Modeling and Analysis Tool for Java Garbage Collector 工具,简称PMAT。 PMAT工具解析JAVA SDK的详细内存回收(GC)日志,并提供统计信息,图表,分析并推荐Java堆配置。PMAT提供了丰富的图形界面来显示Java堆的使用状况,从而更轻松地判断是否有内存问题发生。该工具可以从IBM的alphaWorks网站下载,只有英文版。
我们可以把GC文件从服务器上下载到PMAT所在机器,然后根据WebSphere的平台选择打开相应的GC文件进行分析。下面是一个GC日志片断,手动分析是比较费劲,而且需要深入了解JVM相关知识。
<af type="tenured" id="6" timestamp="Tue Sep 05 12:31:59 2006"
intervalms="18633.354">
<minimum requested_bytes="8208" />
<time exclusiveaccessms="6.240" />
<tenured freebytes="12098304" totalbytes="268435456" percent="4" >
<soa freebytes="51952" totalbytes="255013888" percent="0" />
<loa freebytes="12046352" totalbytes="13421568" percent="89" />
</tenured>
<gc type="global" id="6" totalid="6" intervalms="18699.043">
<classloadersunloaded count="0" timetakenms="1.598" />
<refs_cleared soft="233" weak="856" phantom="65" />
<finalization objectsqueued="455" />
<timesms mark="165.502" sweep="10.989" compact="0.000" total="178.668"
/>
<tenured freebytes="169843272" totalbytes="268435456" percent="63" >
<soa freebytes="157796920" totalbytes="255013888" percent="61" />
<loa freebytes="12046352" totalbytes="13421568" percent="89" />
</tenured>
</gc>
<tenured freebytes="169834952" totalbytes="268435456" percent="63" >
<soa freebytes="157788600" totalbytes="255013888" percent="61" />
<loa freebytes="12046352" totalbytes="13421568" percent="89" />
</tenured>
<time totalms="191.943" />
</af>
|
PMAT在分析GC日志后,给出一个总结。下图为例,我们可以看出GC对系统性能的影响,以及完成的垃圾回收次数等,并且我们可以看出工具给出的推荐(Recommendations)显示系统的Java堆使用情况是持续增加的。

进一步,我们可以查看GC的详情,点击Analysis菜单,然后选择Graph View All,我们就可以根据需要选择所要查看的曲线。如图所示,红色曲线代表已使用内存,蓝色曲线代表每次垃圾回收后可用的内存。已使用内存逐渐增加,可用内存的持续降低表明系统可能存在内存泄漏。
| |
|
另外一种方法是借助TPV和PMI来实时监视JVM,分析性能曲线来判断是否有内存泄漏的状况发生。 WebSphere性能监控基础结构(PMI)和Java虚拟机概要分析工具接口(JVMTI)可以帮助我们收集系统的性能状况数据,使用Tivoli性能查看器(TPV)以图形的方式显示这些数据(性能计数器),可以进一步证实是否系统正在发生内存泄漏。
PMI 提供WebSphere运行时和应用程序资源行为的一组全面的数据,。例如,PMI 提供数据库连接池大小、servlet 响应时间、 Enterprise JavaBeans(EJB)方法响应时间、Java 虚拟机(JVM)垃圾回收时间以及 CPU 使用量等等。使用 PMI 数据,可以识别并修正应用程序服务器中的性能瓶颈, 还可使用 PMI 数据来监控应用程序服务器的运行状况。PMI 数据可以由 Tivoli Performance Viewer(TPV)、其他 Tivoli 工具、您自己的应用程序或第三方工具来监控和分析。TPV 是随 WebSphere Application Server 一起提供的 PMI 数据图形查看器。
Tivoli Performance Viewer(TPV)使得我们可以通过查看图表或表格,从而解读WebSphere的性能监控基础结构(PMI)数据。
默认情况下,PMI已经开启,级别是默认(Default)。配置步骤:
1. 在控制台导航树中单击监视&调整-> 性能监视基础结构(PMI)。
2. 选择所要配置的服务器名字。
3.单击配置选项卡,这里可以根据监控内容的需要,来选择PMI的任一种统计信息集(无,基本,扩展,全部,定制)。我们这里选择"定制"。
注:如果在配置选项卡中,则当重新启动服务器时应用设置。如果在运行时选项卡中,则立即应用设置。
4.点击定制 -> 在定制监视级别的树中,选择配置选项卡,然后点开JVM运行时,可以根据需要,启用或禁用相应的计数器。
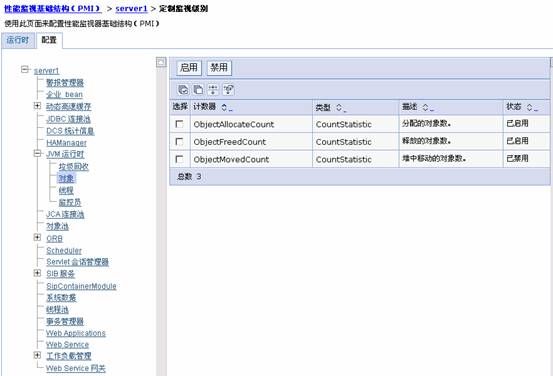
5.保存并重启WebSphere服务器。
实时查看 TPV 性能模块的步骤:
(1) 在控制台导航树中,单击监控和调整 -> 性能查看器 -> 当前活动 -> 服务器名字)-> 性能模块。
(2) 选中要查看的每个性能模块,例如JVM运行时。
(3) 单击查看模块按钮。 在页面的右侧会显示所选性能数据的图形或切换成表格。注:每个模块有与其关联的多个计数器。这些计数器会显示在数据图形或表格下面的表中。您可以通过选择或取消选择计数器旁的复选框,将计数器添加到图表或表中,或从中除去。
TPV显示的已使用内存的图形理想情况下应该是锯齿状,图形中每个坡(下降)对应着一次内存的垃圾回收(Garbage collection),如下图已使用内存的曲线,显示的是没有发生内存泄漏的状况。

如果测试过程中出现如下情况,则有可能发生了内存泄漏:
-每次垃圾回收后的已使用内存的数值骤增。
-TPV对应的已使用内存图形更接近于阶梯(staircase),或者锯齿形状严重不规则。
-也可以查看分配的对象数与释放的对象数之差值,如果这个数值越来越大,则有内存泄漏(如果需要查看对象数,需要启用JVMTI接口并在PMI中启用相应的JVM计数器)。

上图,红色曲线代表已使用的内存,从整体趋势,我们可以看出已使用内存一直在增长。 TPV可以帮助发现内存泄漏,为了得到最优结果,我们可以重复试验,而且每次可以增加测试的时间,例如测试1000,3000或5000个页面请求。
| |
|
WAS6.1中,在使用IBM JDK的平台上,可以直接使用以下的方法,随时生成所需的heapdump文件。如果在性能诊断顾问程序配置里面选中了"启用自动堆转储收集,则可以自动在WebSphere profile所在的路径下(例如/opt/IBM/WebSphere/WAS6.1/profiles/AppSrv01)生成heapdump文件,备用户进行分析。
在使用IBM SDK的平台上,例如AIX, Linux和Windows,在启用了性能诊断顾问工具后,如果探测到有内存泄漏发生,WebSphere会自动生成两个heapdump文件,供后续分析使用。
我们在任何时候,可以随时手动生成所需的heap dump文件。在WAS6.1 profile的bin目录下,首先运行wsadmin 脚本客户端,然后可以调用generateHeapDump操作来完成。
关键步骤:
1. 找到JVM对象名字。
<wsadmin> set objectName WebSphere:type=JVM,process=<WebSphere服务器名字>,node=<节点名字>,*] |
2. 对JVM MBean调用generateHeapDump操作。
<wsadmin> $AdminControl invoke $objectName generateHeapDump |
例如:
[root@csspvm bin]# pwd /opt/IBM/WebSphere/WAS6.1/profiles/AppSrv01/bin [root@csspvm bin]# ./wsadmin.sh -username root -password demo4you WASX7209I: Connected to process "server1" on node csspvmNode02 using SOAP connector; The type of process is: UnManagedProcess WASX8011W: AdminTask object is not available. WASX7029I: For help, enter: "$Help help" wsadmin>set objectName [$AdminControl queryNames WebSphere:type=JVM,process=server1, node=csspvmNode02,*] WebSphere:name=JVM,process=server1,platform=proxy,node=csspvmNode02, j2eeType=JVM,J2EEServer=server1, version=6.1.0.0,type=JVM,mbeanIdentifier=JVM,cell=csspvmNode02Cell,spec=1.0 wsadmin>$AdminControl invoke $ objectName generateHeapDump /opt/IBM/WebSphere/WAS6.1/profiles/AppSrv01/./heapdump.20060904.075650.3576.phd wsadmin>quit |
理想情况下,在探测到问题时,尽快生成一个初始的heap dump,然后密切监控内存使用情况,等到泄漏了足够的内存的时候,再生成另外一个heap dump,这样可以对比分析以更准确地找到泄漏的原因。
注: 生成HeapDump文件的过程是比较耗资源的,所以请只在必须的时候做这样的操作。
| |
|
一旦确定了系统中有内存泄漏,并且为此生成了heap dump。接下来,我们可以把这些文件从WebSphere应用服务器转移到离线的分析工具所在的机器,进行离线分析诊断。
MDD4J(Memory Dump Diagnostic for Java)是一个内存泄漏分析工具,用于对运行 WebSphere Application Server 的虚拟机(JVM)所生成的常用内存转储(堆转储)格式进行分析。进行内存转储(Memory dump)分析的目的,是为了确定 Java 堆中真正导致内存泄漏的类和包(classes and packages),这样可以缩小内存泄漏的范围并找到真正的原因,此分析还确定应用程序 Java 堆占用量的主要组成部分以及它们之间的拥有关系。
此工具支持下列格式的内存转储格式有:
-IBM 的PHD格式(heapdump.phd)
-IBM 文本堆转储(heapdump.txt)
-HPROF 堆转储格式(hprof.txt,主要针对Solaris和HP-UX平台)
-SVC 转储(dump.bin,IBM z-Series上的WebSphere)
该工具提供了两种分析机制:单转储分析以及对两个转储进行的比较分析。
单转储分析最常用于在发生 OutOfMemoryException 时自动触发的内存转储。此类分析查找可疑的数据结构,能够相对快速地提供可疑泄漏对象的分析结果。
比较分析用于对运行内存泄漏应用程序期间(即可用 Java 堆内存流失时)获取的两个内存转储进行分析。在运行泄漏应用程序的早期触发的内存转储被称为基线内存转储,发生泄漏的应用程序运行一段时间(以允许泄漏程度加大)后触发的内存转储被称为主内存转储。在发生了内存泄漏的情况下,主内存转储可能包含大量对象,而这些对象占用的 Java 堆空间量会比基线内存转储大很多。
为了获得更好的分析结果,建议使主内存转储的触发点与基线内存转储的触发点在时间上拉开一定距离,从而使总耗用堆大小在两个触发点之间大幅增长。
MDD4J的分析结果显示是基于Web界面的,具有下列特征:
- 列示分析结果、堆内容、大小和增长幅度的总结
- 列示可疑的数据结构、数据类型和包,它们是造成堆使用量增加(对于比较分析)和堆大小较大(对于单转储分析)的主要原因。
- 拥有关系上下文视图显示了占用量主要组成部分之间的关系,以及一组汇总的主要占用量组成部分所包含的重要数据类型。
- 在堆转储内容的交互式树形视图中,浏览功能能够显示堆中任何对象的所有进入引用(在树中只显示一个引用,其余引用单独显示)和外出引用,而子对象按到达大小排序。
- 导航功能使您能够从可疑对象列表转到所有关系上下文,以及从内容视图转到浏览视图。
- 提供了内存转储中所有对象和数据类型的表视图,视图中具有过滤器和经过排序的列。
WebSphere 应用服务器v6.1的附带光盘里面有IBM Support Assistant工具的安装文件,运行相应的安装文件,MDD4J作为插件同时被安装了。
另外,也可以从IBM 技术支持站点http://www-306.ibm.com/software/support/isa/ 下载Support Assistant工具,然后选择更新程序,独立安装MDD4J插件。
启动步骤:
(1) 程序->IBM Support Assitant ->IBM Support Assistant v3
(2) 在Support Assistant窗口中,选择工具 -> 选择WebSphere版本号。

点击MDD4J的链接,就可以开启MDD4J工具。在该界面中,我们可以提交单个heap dump文件进行单转储分析,或同时提交两个文件进行比较分析。也可以从内存转储分析结果的下拉选项中选择以前的分析结果,从而查看以前的分析内容。

查看分析进度
单击"上载并分析"按钮后,MDD4J开始分析heap dump文件。在分析执行过程中,登录页面将自动刷新,以反映当前正在执行的分析步骤以及整体分析进度。如果该页面由于某种原因而不刷新,您可以单击"刷新"按钮以了解当前分析状态。如果您希望停止分析,可以单击"停止"按钮,这将在当前正在执行的模块完成后终止分析。
在提交了heap dump文件,MDD4J显示分析状态。

查看分析结果
分析完成后,Mdd4J页面将重定向到"分析结果"页面。"分析结果"页面包含 4 个选项卡:
"分析总结"选项卡:显示分析结果总结,并列示下一组用于查看分析结果的步骤。
"可疑对象"选项卡:它显示四类可疑对象,即对增长幅度影响最大的数据结构、到达大小显著流失的数据结构、有大量实例的对象类型以及有大量对象实例的 Java 包。
"察看上下文和内容"选项卡:显示主内存转储中 Java 堆占用量的主要组成部分的拥有关系上下文图,以及图中所选节点的内容。
"浏览"选项卡:根据对对象引用图执行的深度优先遍历,用树形视图显示主内存转储的所有内容。
其他内容,请参照MDD4J工具附带的Help文档,该帮助文档有详细的使用说明,在此不再赘述。
| |
|
IBM提供了一系列的工具辅助用户进行内存问题的监控和分析,在合适的阶段选择合理的工具可以帮助我们轻松搞定内存泄漏。这里介绍的工具都是 WebSphere附带或者免费的,IBM Tivoli工具还提供了更强大的监控和诊断功能,例如ITCAM (IBM Tivoli Composite Application Management),可以根据实际情况选用。
- WebSphere Application Server V6.1: Version 6.1 中的新特性
- WAS6.1 信息中心
- WebSphere Application Server Java Dumps
- WebSphere Application Server 中的内存泄漏检测与分析: 第 1 部分:内存泄漏概述
- IBM Pattern Modeling and Analysis Tool for Java Garbage Collector
本文转载于IBM官方网站:
http://www.ibm.com/developerworks/cn/websphere/library/techarticles/0609_xuechao/index.html