Derby入门
译者:曾巧(numenzq)
源作者:Sing Li
发布日期:2005-06-30
摘要
Derby是一个100%Java开源的关系数据库,并且你不可轻视它。
正文
一般的应用程序都需要一个简单的存储和获得数据的方法。如果你长期开发一个软件,你都需要一个关系数据库为你长期服务。然而,作为一个Java开发者,你的选择是有限的。你可能尝试使用商业的关系数据库管理系统,它们大多数不是用Java语言编写的,虽然普遍的能达到100% Java JDBC连接器。这些商业产品通常需要大量的配置,接下来需要数据库管理员对服务进行操作和调整,并且当你在每个客服端发布使用时,都需要很高的许可费。
另一方面,你可以选择一个开源的Java基于关系数据库管理系统实现。这些产品通常是为嵌入式应用设计的。支持有限的重要的标准SQL语句,并支持关系数据库管理系统的最小特性。但是它们是自由许可的,容易管理,并且可以集成一些代码来弥补缺少的特性。
它是一个理想的,并且开源的,100% Java编写的,容易管理的关系数据库管理系统,它可以和一些商业产品的特性进行交付。这篇文章是关注Apache Derby项目--一个两全其美的关系数据库管理系统。
Derby--一个出神入化的产品周期
图片片刻实现一个商业级软件产品的完美生命周期。最初,设计者应该开始构思;当设计师不能获得问题的答案或没有创新的解决方案时,将会丧失原有的激情。一旦产品能证明在解决问题上有自身的能力,并有一定数量的用户基础后,这个小公司将进入一个大公司的视野。使这款软件成为它们收购的目标,大公司将“handen”这个产品附加质量保证,加宽它的范畴,使之快速增长,并写出高质量的文档。一旦这款产品达到它的最高采用时,然后大公司应该支持该产品成为开源项目,有一个很好的自由许可让每个人都可以采用和修改。你,作为一个受益者可以获得这些健壮的地层代码,也可以将它加入到你的产品中,商业应用和其他的,并受益于探研地层代码的所有心血。
当然,上面提到的理想化的软件产品生命周期听起来不会发生在资本主义自由经济下。但是有时在现实生活中,是做得到的!
上面理想化的产品生命周期是确切的,因为它发生在Apache Derby上。Derby是一个名为Cloudscape的小公司构思的;当Cloudscape卖给Informix后,该产品得到了加强;当IBM加入时,在“big blue”期间,它的高端工程特性得到增强;现在已经成为一个有最自由的许可的开源项目而存在。
广泛而深入的特性列表
Derby的生动逼真的抚育使得它拥有一个令人惊奇的特性列表。有许多简单的高级特性不能被其他开源Java数据库利用。一部分的列表特性使Derby从其他的Java 关系数据库管理系统中分离出来,包括:
l 100% Java实现
l 100% Java类型4 JDBC驱动
l SQL92E标准支持大部分SQL 99特性
l ACID完全的事务独立的事务支持
l J2EE支持JNDI,连接池和XA
l 视图,临时表和保存
l BLOB和CLOB数据类型
l 行和表锁定
l 有价值的基本查询优化
l 服务器端指示约束
l 触发器和存储过程
l 为服务器端函数,触发器或存储过程等操作在数据库里存储Java代码
l 能排除CD-ROM里的只读数据库
l 数据的导入和导出
l 快速数据库加密选项
在代码例子中,你将谈究使用指示约束,存储过程和在数据库中存储Java代码。
两种灵活的使用模式
Derby可以工作在嵌入式模式下,或在完全的客户端/服务器模式下。插图1说明在嵌入式模式下的工作原理。
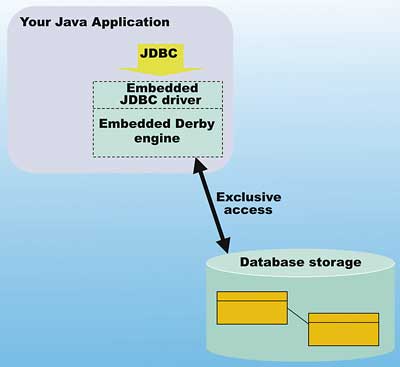
插图1:嵌入式模式
在插图1里,你可以看到Derby引擎是嵌入在你的应用程序里的。当工作在嵌入式模式,你的应用程序访问数据库是直接和专有的。这就意味着其他应用程序不可能在同一时间访问该数据库。嵌入式模式的主要优点是不需要进行网络和服务器设置。因为你的应用程序包含了Derby引擎,使用者并不知道你使用了一个关系数据库。
当使用Derby的嵌入式模式时,并没有复杂的配置和特殊的API需要你去学习。实际上,你仅仅需要做:
1.
确保Derby JARs文件在你的应用程序classpath里
2.
使用嵌入式JDBC驱动
3.
写数据库访问代码到JDBC
这是正确的,Derby根本没有特殊的APIs。只需要为你的应用程序编码到JDBC,然后Derby会为你工作得很好。事实上,如果你已经有了JDBC代码,而想把代码转换到Derby嵌入式模式下运行是十分容易的。
如果你使用过ORACLE,DB2,SQL Server或MySQL,你应该对网络模式(客户端/服务器模式)的工作原理相当熟悉。插图2说明了这个模型的工作原理
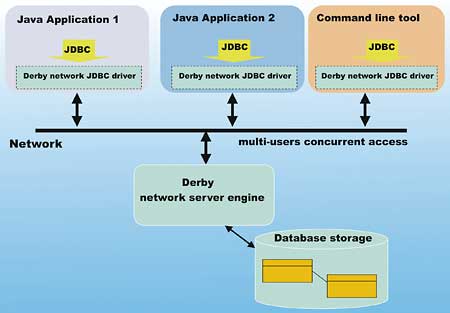
插图2:客户端/服务器模式
在插图2中,一个独立的Java进程运行作为Derby的网络服务器,通过网络监听客户端的连接。该Derby网络服务器能唯一的访问数据库存储器,并能同时接受多个客户端连接。这就允许多个用户在同一时间通过网络方式访问该关系数据库管理系统。
当不适合使用嵌入式模式进行操作时(例如:你必须运行和管理个别的服务器进程,或许在不同的机器上),当你需要多用户访问数据库时,Derby的客户端-服务器模式能提供一个有效的解决方案。
在插图2中,注意客户端应用程序编码到JDBC。这些不是Derby特有的APIs。事实上,这个类似于插图1里的运行在嵌入式下JDBC应用程序运行在客户端-服务器模式的最低配置下。
配置Derby数据库
为了完全体会Derby设置和使用的好处,你需要自己亲身体验它。首先,下载和安装Derby。然后,确保你的classpath环境变量包含:
derby_installation_directory\lib\derby.jar;和derby_installation_directory\lib\derbytools.jar;
你也可以编辑提供给你的sp.bat文件,设置你的Derby安装目录,然后运行设置你的classpath。
一旦你设置好了classpath,就修改工作目录。数据库将被创建在这个目录里面。从db\createdb目录复制createdb.sql文件到工作目录。然后,启动命令行界面(执行ij)进入Derby:
java org.apache.derby.tools.ij
你也可以使用在batch子目录下提供的ij.bat,在使用前一定要编辑该批处理文件,添加你的Derby安装目录路径。这样才能进入正确的命令行,使用嵌入式Derby引擎。你看到的提示将与下面的类似:
ij version 10.0
ij>
你可以输入“help”;来查看可以使用的命令。要创建数据库和表来使用,仅仅需要运行createdb.sql文件。使用ij命令:
run ‘createdb.sql’;
run命令将调用一个脚本文件并执行它里面的Derby命令,类似于Windows的批处理文件。下面显示的是createdb.sql文件的内容。
connect
'jdbc:derby:vsjdb;create=true';
drop table orders;
drop table custs;
create table custs
(id char (5) not null,
name char(40) not null,
primary key(id));
create table orders
(id char(8) not null,
custid char(5) not null,
total integer,
primary key(id,custid));
insert into custs values (
'1', 'John Smith');
insert into custs values (
'2', 'Mary Todd');
insert into orders values(
'0001', '1', 39999);
insert into orders values(
'0002', '1', 2999);
insert into orders values(
'0003', '1', 1904);
insert into orders values(
'0004', '2', 3232);
insert into orders values(
'0005', '2', 109900);
在每一行都需要一个分号,这与命令行输入命令是一样的。脚本的第一行是连接命令,指明连接的嵌入式Derby驱动名字。在脚本里的连接命令为:
connect
‘jdbc:derby:vsjdb;create=true’;
使用jdbc:derby说明Derby驱动是使用的JDBC协议,而vsjdb是一个数据库的名字,它能通过嵌入式驱动创建和访问。create=true属性说明如果该数据库不存在时,就创建该数据库。
该createdb.sql脚本将创建一个名为vsjdb(当它不存在时)的数据库,并在该数据库中创建custs和orders表。它将在表中添加两个用户和五个定单。如果你使用过其他数据库的SQL语句,你应该相当熟悉在脚本里的SQL语句。
你可以查看你的工作目录,现在你将看到一个vsjdb子目录。数据将保存在里面。数据库可以很简单的的进行备份,就是复制这个子目录。
表格1和表格2是custs和orders表的信息
|
Table 1: The custs table
|
||
|
Field Name
|
Data Type
|
Note
|
|
Id
|
char(5)
|
primary key
|
|
Name
|
char(40)
|
|
|
Table 2: The orders table
|
||
|
Field Name
|
Data Type
|
Note
|
|
Id
|
char(8)
|
primary key (compound)
|
|
Custid
|
char(5)
|
primary key (compound)
|
|
Total
|
int
|
|
与关系数据库管理系统数据操作
要查看顾客记录信息,在ij提示行后使用SQL SELECT语句:
select * from custs;
要查看定单,使用下面的命令:
select * from orders;
要删除顾客,尝试使用下面的命令:
delete from custs where id=’1’;
你可以选择custs表里的某一行,并能查看到哪个用户被删除。要删除与这个用户相关联的定单信息,使用下面的命令:
delete from orders where custid=’1’;
你现在可以查看orders表,并能看见所有关于一号顾客的定单都被删除了。
在你离开ij前,删除数据库里的所有记录:
delete from custs;
delete from orders;
着它将是一个空数据库,在下一部分,将写入自定义的Java代码。
使用exit命令离开ij:
exit;
自从连接URL指定了嵌入式驱动,只有ij能唯一的访问这个数据库。
嵌入Derby到你的Java应用程序中
时间加速我们的Java编译和编写某些代码。这些代码将放入Derby做一个小测试,给你一个关系数据库管理系统能处理现实世界大量数据能力的信心。
下面是名为FillTable.java的代码,将创建1000个用户,每个用户有10条定单--总共10000条定单。在嵌入子目录下你可以找到FillTable.java的源代码。
import java.sql.*;
public class TableFiller {
Connection conn = null;
PreparedStatement insertCust
= null;
PreparedStatement insertOrder
= null;
上面的申明是标准的JDBC申明。conn控制JDBC连接。insertCust和insertOrder将分别处理插入记录到custs和orders表里的SQL语句。PreparedStatement的使用使关系数据库管理系统得到优化的可能。
其次,下面的代码,driverName包含我们装载和使用的JDBC驱动器的类名。这是一个嵌入式驱动器。连接的URL是url值。你可以看见是使用的绝对路径定位这个数据库(注意:你必须要使用正斜线来分离路径)。如果你总是在你的工作目录运行这个程序的话,你可以仅使用”jdbc:derby:vsjdb”。也可以可以设置derby.system.home属性来改变Derby数据库文件的位置(例如:java -D derby.system.home=c:\mydbdir org.apche.derby.tools.ij)。
String driverName =
"org.apache.derby.jdbc.EmbeddedDriver";
String url =
"jdbc:derby:c:/derby1021/vsjdb";
loadDrivers()方法装载JDBC驱动类并创建获得一个Derby的JDBC连接。并准备两个插入语句。
public void loadDrivers()
throws SQLException,
ClassNotFoundException {
Class.forName(driverName);
conn = DriverManager.getConnection(
url);
insertCust = conn.prepareStatement(
"INSERT INTO custs VALUES(
?, ?)");
insertOrder =
conn.prepareStatement(
"INSERT INTO orders VALUES(
?, ?, ?)");
}
TableFiller的main()方法创建一个TableFiller的实例,并调用它的addCustomer()方法去创建1000个用户。它也调用addOrder()方法去创建10000条定单信息。为了显示进度,它打印顾客编号和’.’到系统输出中。
public static void main(String args[])
throws Exception {
TableFiller tf = new TableFiller();
tf.loadDrivers();
int orderNum = 1;
for (int i=1; i<1001; i ) {
String custNum = "" i;
tf.addCustomer(
custNum, "customer #" i);
System.out.print("\n"
custNum);
for (int j=1; j<11; j ) {
tf.addOrder( "" orderNum,
custNum, j * 99);
orderNum ;
System.out.print(".");
}
}
tf.closeAll();
}
addCustomer()方法获得参数并执行insertCust的预编译语句。
public void addCustomer(
String id, String custname)
throws SQLException {
insertCust.setString(1, id);
insertCust.setString(2, custname);
insertCust.executeUpdate();
}
addOrder()方法获得参数并执行insertOrder的预编译语句。
public void addOrder(String id,
String custid, int total)
throws SQLException {
insertOrder.setString(1, id);
insertOrder.setString(2, custid);
insertOrder.setInt(3, total);
insertOrder.executeUpdate();
}
closeAll()整理和关闭两个预编译语句和JDBC连接,通知Derby释放被控制的资源。
public void closeAll()
throws SQLException {
insertCust.close();
insertOrder.close();
conn.close();
}
}
当顾客和定单被创建,程序将打印顾客编号到屏幕上。编号从1到1000表明每个顾客被创建。而打印的每个’.’则表明定单被创建。
要编译这个代码,你仅仅需要确信你已经设置了classpath,并且使用标准的Java编译命令:
java TableFiller.java
你要确保没有ij或其他Derby会话在运行。在嵌入式模式你需要唯一的访问数据库。在编译成功后,需要复制TableFiller.class文件到你的工作目录下,然后从那里运行TableFiller:
java TableFiller
你应该看见打印出来的状态和写入数据库的记录。
检验被创建的记录
现在,去看看你创建的顾客和定单信息,确保你在工作目录并再次登录到ij。连接vsjdb数据库。
connect ‘jdbc:derby:vsjdb’;
然后使用下面的SELECT语句查看所有1000条顾客信息。
select * from custs;
同样的使用下面的SELECT语句查看所有10000条定单信息。
select * from orders;
当然,使用类似于FillTable.java里的标准JDBC代码,你可以整合Derby的关系数据库的访问功能到你的任何一个工程中。当你的项目需要一个嵌入式数据库时,有能力简单和快速处理产生大量的数据的Derby是你最好的选择。Derby的自由Apache许可允许你绑定它到你的程序上,即使你决定把你的产品进行商业买卖。
探索Derby的高级特性
由于Derby是从IBM中分离出来的,Derby有许多高级功能--具有代表性的仅仅建立在高端的关系数据库管理系统中。插图3展现了几个有趣的特性。

插图3:Derby的数据库特性
在插图3中,该数据库存储包括数据表,图表,关系信息--这是所有关系数据库所必须有的。另外,你可以看见它也可以包含触发器,存储过程,甚至Java代码。这些高级特性将在文章的后面部分探究。Derby的网络模式的操作也将被提及。
配置Derby的网络模式
要访问Derby的网络服务器模式,首先你需要把下面的JAR文件地址添加到你的classpath值里。
derby_installation_directory\lib\derbynet.jar
你还需要为客户端访问下载一个网络JDBC驱动。如果你使用IBM DB2 JDBC普通驱动,你则需要把下面的JAR文件地址添加到你的classpath值里:
derby_installation_directory\lib\db2_jcc.jar
derby_installation_directory\lib\db2_jcc_license_c.jar
batch子目录里的sp.bat文件里的classpath值已经包含了这些JARs文件地址。
启动网络服务器,使用下面的命令:
java org.apache.derby.drda.NetworkServerControl start
你也可以使用batch子目录下的netsvr.bat文件。
在默认情况下,服务器将监听TCP1527端口来接收客户端请求。你可以使用”-p <port number>”参数来改变端口。
如果你需要关闭服务器,使用下面的命令:
java org.apache.derby.drda.NetworkServerControl shutdown
或者你可以使用batch子目录下的netstop.bat文件。
现在服务器已经准备好了,为我们下面的探究铺上了台阶。
自动层叠删除
现在你有超过一万条的定单数据,你需要保证这些在数据库里的数据没有被破坏。固定这些数据是毫无疑问的。
让我举例说明一个潜在的问题,这个问题的中心是围绕在删除一个顾客后。问题就有可能会出现。
使用标准的SQL语句,只从custs表中删除顾客信息:
delete from custs where id='838';
这是从数据库中删除顾客编号为838的消费者。好极了!
如果这是你所做的,数据库的数据正式被破坏了。为什么呢?这是因为在数据库里有10定单信息没有关联到消费者!
这可能引起应用程序各种各样的错误。所有应用程序取得定单信息并尝试打印顾客信息时,都会涉及到这个异常。当你列出所有用户和他们的定单信息时,有些定单信息永远都不会显示出来。
在关系数据库管理系统的条款中,数据库引用完整性是不允许这样的情况的。这是因为一条顾客记录被删除,而没有删除相应的定单信息。
因此,我们需要这样做:
delete from custs where id='838';
delete from orders where custid='838';
而且,我们需要确保两条删除命令在同一个事务中执行。要么两条语句都执行成功,要么都执行失败。
这个称为删除层叠,因为删除顾客记录导致删除定单信息。
Derby有能力处理引用完整性。
Derby触发器
保证引用完整性的方法是定义一个触发器。一个触发器是一段代码或SQL语句,当数据发生修改或存取时,它将在数据库服务器里执行。Derby支持定义触发器(使用SQL语句或Java代码),当顾客记录被删除时,可以编码实现删除关联的定单信息。然而,在Derby里有一个更简单的方法。
它可以告诉Derby,使用标准的SQL DDL(数据定义)语句,这涉及到orders表和custs表。你也可以告诉Derby去完成自动层叠删除。
添加参考约束
要添加自动层叠删除,就要修改原始的createdb.sql里的语句。在db\ref子目录下找到createdbref.sql文件。你需要对orders表定义进行修改。添加下面兰色字体的内容:
create table orders
(id char(8) not null,
custid char(5) not null
references custs (id) on delete
cascade, total integer,
primary key(id,custid));
另外一个不同是连接数据库的URL值。这时,网络驱动器是指定的。一定要注意网络驱动器是需要用户名和密码的,默认的用户名和密码都是APP,所以URL值将修改为:
connect 'jdbc:derby:net://localhost/
vsjdb:user=APP;password=APP;';
你现在可以强行创建带参考约束的新表。确保复制createdbref.sql到你的工作目录。再次启动ij。现在,使用下面的命令可以删除所有记录并创建新表:
run 'createdbref.sql';
在创建了表后,你可以再次运行TableFiller.java文件去在表中添加10000条定单数据。使用network子目录的修改版本。在原始的TableFiller.java里修改的部分如下面兰色字体显示的:内容:
import java.sql.*;
import java.util.Properties;
public class TableFiller {
Connection conn = null;
PreparedStatement insertCust
= null;
PreparedStatement insertOrder
= null;
String driverName=
“com.ibm.db2.jcc.DB2Driver”;
String url =
“jdbc:derby:net://localhost/
vsjdb:user=APP;password=APP;”;
...
装载的驱动器将要改为网络驱动器(com.ibm.db2.jcc.DBDriver),URL值最好还是改成访问网络JDBC驱动器的值。否则,这个代码将与原始的TableFill.java文件一样。如果你要写你自己的JDBC代码,你可以设置一个string从外部文本文件里读取参数,这样你将不需要修改代码就能在嵌入式关系数据库管理系统和网络关系数据库管理系统之间转换。
多用户并发访问
现在,来关注多用户连接,在另一个控制台窗口启动ij会话,并连接到服务器使用下面的命令:
connect 'jdbc:derby:net://localhost/
vsjdb:user=APP;password=APP;';
在原始的控制台窗口,编译并运行新的TableFiller.java文件。这将创建1000个顾客记录和10000条定单记录。当这些操作执行完毕后,回到新的ij窗口并使用下面的命令:
select * from custs;
…and:
select * from orders;
当你执行这个命令的时候,你将发现所有用户和定单信息都已经被创建。网络服务器允许多用户并发访问数据。
测试层叠删除
一旦你创建了数据记录,试着在ij里执行下面的语句:
select * from custs where id='700';
接着执行下面的语句:
select * from orders where
custid='700';
你将看到顾客记录和这个顾客的10条定单信息。
现在,尝试删除顾客,使用下面的命令:
delete from custs where id='700';
这将删除用户记录,层叠将会删除关联的定单信息。现在尝试再次使用上面的select语句查看,你将发现那10条定单信息也被删除了。
写一个Derby存储过程
在实验的最后,你将用Java编程语言创建一个Derby存储过程。你也可以存储代码到存储过程进入Derby数据库内部,Derby能轻松的区分数据和代码。
该存储过程将调用deleteAll(),从它的名字可以理解到,它将删除数据库里的所有记录。在stored子目录下可以找到实现该存储过程的Java代码
分享到:


评论