redis cluster百万QPS的挑战
最近在做redis cluster性能测试过程中,发现当集群吞吐量到达一定程度后(4台12core的redis服务器,80wQPS左右),集群整体性能不能线性增长。也就是说,通过加机器不能提升集群的整体吞吐。以下是详细记录了一下这个case的排查并最终解决的过程。
先来看一个压测图:
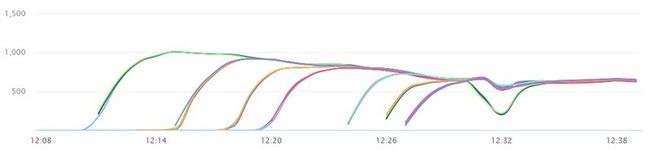
上图中每一条线代表一个起压端进程的压测QPS(一台起压机上开4个起压端),可以看到随着起压机的增多,每个起压机的QPS却在下滑。而此时redis的CPU、内存、网卡都还没有跑满。另外尝试增多redis服务器,发现增多一倍服务器后,每台服务器上每个redis实例的CPU大幅降低。总的QPS却基本没有变化。
由于起压机是无状态的,只是简单的mock随机请求到redis cluster,并且请求的路由策略会在起压机内部调jedis的过程中做好,直接请求到目标redis实例,并且在起压过程中没有槽迁移导致的ASK/MOVED动作。所以排除了起压机的影响,只能怀疑是redis cluster服务端导致的问题。
一开始怀疑是服务端连接数过多的问题,看了一下,服务端连接数在1w以下,每个客户端与每个redis实例的连接数也就在几十个长连接,远没有到达系统瓶颈。
难道是CPU的问题?但是top看每个核的CPU也就打到60%左右,而且如果是CPU到瓶颈了,通过增加redis服务器应该可以线性伸缩才对,但并没有。
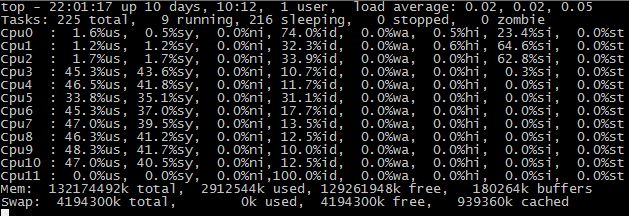
再仔细观察top信息,发现每个核的CPU都有一定的si开销,也就是软中断,中断开销在10%以上:

怀疑是软中断导致抢占了Redis的CPU资源,软中断耗在哪里了可以用以下命令看到:
发现中断开销主要集中在网卡中断上,也就是eth0-TxRx上面。解决思路是将网卡中断和Redis进程使用的CPU隔离开,这样避免网卡中断抢占CPU拖慢Redis服务。另外,由于Redis是单线程模型,在多核服务器上,可以将多个Redis实例绑定到不同的CPU上,使每个Redis进程独占一个CPU。
先将网卡的中断号绑定到特定CPU上:
再将Redis master实例绑定到CPU3-CPU10上。这里没有绑定Redis slave,是因为观察到slave占用的CPU极低,每个slave占用大概一个核的5%以下。当然如果CPU核数够多的话也可以考虑绑slave到其它多余的核。
绑定好后再压,看top会发现,前三个CPU主要耗在si上(网卡中断),后8个CPU耗在us/sy上(redis master服务):
至此,解决了单机CPU的问题,但是集群不能线性增长的问题还是解释不通。因为即使单台redis服务器的软中断导致单机性能受影响,在加Redis机器时总吞吐也不应该上不去呀。所以,开始怀疑redis cluster的通讯总线导致线性增长受阻。
每个redis cluster实例都会开一个集群通讯总线端口,并且redis cluster会用gossip协议,每隔一秒钟将集群 一部分节点的信息发送给某个实例的总线端口。利用这种传播方式,可以将集群节点的变更以无中心的方式传播到整个集群。这里关键是总线传播的数据量,数据量的大小取决于PING消息携带的gossip数组的长度和大小,这个长度就是具体要捎带多少个其它节点的信息:
以上函数定义了发送PING包的逻辑,重点是wanted变量的计算方式,也就是每次PING包内要携带多少个其他节点信息发送。可以看到,wanted最小3个,最大不超过集群总实例数-2个,一般情况是 集群实例数的1/10个。
再来看看每个gossip包的大小:
看到这里就明白了,总线传播的数据量wanted是一个变量,会随着集群实例数的增多而增多。当集群节点数不多时不会造成影响,但随着节点数变多,每次wanted要携带的节点信息也就随之变多,会导致对网卡的消耗越来越大。我压测时每台Redis服务器8主8从共16个节点,四台服务器共64个节点,每个节点每秒钟PING包都要携带6个gossip包的信息(64/10)。如果扩大到十台,就是每个节点每秒钟PING包要携带16个gossip包的信息(160/10)。
解决了网卡中断问题后,Redis实例的CPU不会再被中断抢走,QPS基本可以线性增长。在6台12coreCPU的Redis服务器上,总QPS可以到达200w/s以上,单机QPS在30w以上。
ps:
推荐一篇有关软中断的文章: http://huoding.com/2013/10/30/296
先来看一个压测图:
上图中每一条线代表一个起压端进程的压测QPS(一台起压机上开4个起压端),可以看到随着起压机的增多,每个起压机的QPS却在下滑。而此时redis的CPU、内存、网卡都还没有跑满。另外尝试增多redis服务器,发现增多一倍服务器后,每台服务器上每个redis实例的CPU大幅降低。总的QPS却基本没有变化。
由于起压机是无状态的,只是简单的mock随机请求到redis cluster,并且请求的路由策略会在起压机内部调jedis的过程中做好,直接请求到目标redis实例,并且在起压过程中没有槽迁移导致的ASK/MOVED动作。所以排除了起压机的影响,只能怀疑是redis cluster服务端导致的问题。
一开始怀疑是服务端连接数过多的问题,看了一下,服务端连接数在1w以下,每个客户端与每个redis实例的连接数也就在几十个长连接,远没有到达系统瓶颈。
难道是CPU的问题?但是top看每个核的CPU也就打到60%左右,而且如果是CPU到瓶颈了,通过增加redis服务器应该可以线性伸缩才对,但并没有。
再仔细观察top信息,发现每个核的CPU都有一定的si开销,也就是软中断,中断开销在10%以上:
怀疑是软中断导致抢占了Redis的CPU资源,软中断耗在哪里了可以用以下命令看到:
watch -d -n 1 'cat /proc/softirqs'
发现中断开销主要集中在网卡中断上,也就是eth0-TxRx上面。解决思路是将网卡中断和Redis进程使用的CPU隔离开,这样避免网卡中断抢占CPU拖慢Redis服务。另外,由于Redis是单线程模型,在多核服务器上,可以将多个Redis实例绑定到不同的CPU上,使每个Redis进程独占一个CPU。
先将网卡的中断号绑定到特定CPU上:
# 如果开了irqbalance服务,需要先停止服务,否则后续的绑定将无效: service irqbalance stop # 将网卡中断号绑定到CPU0-CPU2上: echo "1" > /proc/irq/78/smp_affinity echo "1" > /proc/irq/79/smp_affinity echo "2" > /proc/irq/80/smp_affinity echo "2" > /proc/irq/81/smp_affinity echo "2" > /proc/irq/82/smp_affinity echo "4" > /proc/irq/83/smp_affinity echo "4" > /proc/irq/84/smp_affinity echo "4" > /proc/irq/85/smp_affinity
再将Redis master实例绑定到CPU3-CPU10上。这里没有绑定Redis slave,是因为观察到slave占用的CPU极低,每个slave占用大概一个核的5%以下。当然如果CPU核数够多的话也可以考虑绑slave到其它多余的核。
# 绑定master的pid到CPU3-CPU10上: taskset -cp 3 [pid1] taskset -cp 4 [pid2] taskset -cp 5 [pid3] ...
绑定好后再压,看top会发现,前三个CPU主要耗在si上(网卡中断),后8个CPU耗在us/sy上(redis master服务):
至此,解决了单机CPU的问题,但是集群不能线性增长的问题还是解释不通。因为即使单台redis服务器的软中断导致单机性能受影响,在加Redis机器时总吞吐也不应该上不去呀。所以,开始怀疑redis cluster的通讯总线导致线性增长受阻。
每个redis cluster实例都会开一个集群通讯总线端口,并且redis cluster会用gossip协议,每隔一秒钟将集群 一部分节点的信息发送给某个实例的总线端口。利用这种传播方式,可以将集群节点的变更以无中心的方式传播到整个集群。这里关键是总线传播的数据量,数据量的大小取决于PING消息携带的gossip数组的长度和大小,这个长度就是具体要捎带多少个其它节点的信息:
/** cluster.c的clusterSendPing函数 **/
/* Send a PING or PONG packet to the specified node, making sure to add enough
* gossip informations. */
void clusterSendPing(clusterLink *link, int type) {
unsigned char *buf;
clusterMsg *hdr;
int gossipcount = 0; /* Number of gossip sections added so far. */
int wanted; /* Number of gossip sections we want to append if possible. */
int totlen; /* Total packet length. */
/* freshnodes is the max number of nodes we can hope to append at all:
* nodes available minus two (ourself and the node we are sending the
* message to). However practically there may be less valid nodes since
* nodes in handshake state, disconnected, are not considered. */
int freshnodes = dictSize(server.cluster->nodes)-2;
/* How many gossip sections we want to add? 1/10 of the number of nodes
* and anyway at least 3. Why 1/10?
*
* If we have N masters, with N/10 entries, and we consider that in
* node_timeout we exchange with each other node at least 4 packets
* (we ping in the worst case in node_timeout/2 time, and we also
* receive two pings from the host), we have a total of 8 packets
* in the node_timeout*2 falure reports validity time. So we have
* that, for a single PFAIL node, we can expect to receive the following
* number of failure reports (in the specified window of time):
*
* PROB * GOSSIP_ENTRIES_PER_PACKET * TOTAL_PACKETS:
*
* PROB = probability of being featured in a single gossip entry,
* which is 1 / NUM_OF_NODES.
* ENTRIES = 10.
* TOTAL_PACKETS = 2 * 4 * NUM_OF_MASTERS.
*
* If we assume we have just masters (so num of nodes and num of masters
* is the same), with 1/10 we always get over the majority, and specifically
* 80% of the number of nodes, to account for many masters failing at the
* same time.
*
* Since we have non-voting slaves that lower the probability of an entry
* to feature our node, we set the number of entires per packet as
* 10% of the total nodes we have. */
wanted = floor(dictSize(server.cluster->nodes)/10);
if (wanted < 3) wanted = 3;
if (wanted > freshnodes) wanted = freshnodes;
/* Compute the maxium totlen to allocate our buffer. We'll fix the totlen
* later according to the number of gossip sections we really were able
* to put inside the packet. */
totlen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
totlen += (sizeof(clusterMsgDataGossip)*wanted);
/* Note: clusterBuildMessageHdr() expects the buffer to be always at least
* sizeof(clusterMsg) or more. */
if (totlen < (int)sizeof(clusterMsg)) totlen = sizeof(clusterMsg);
buf = zcalloc(totlen);
hdr = (clusterMsg*) buf;
/* Populate the header. */
if (link->node && type == CLUSTERMSG_TYPE_PING)
link->node->ping_sent = mstime();
clusterBuildMessageHdr(hdr,type);
/* Populate the gossip fields */
int maxiterations = wanted*3;
while(freshnodes > 0 && gossipcount < wanted && maxiterations--) {
dictEntry *de = dictGetRandomKey(server.cluster->nodes);
clusterNode *this = dictGetVal(de);
clusterMsgDataGossip *gossip;
int j;
/* Don't include this node: the whole packet header is about us
* already, so we just gossip about other nodes. */
if (this == myself) continue;
/* Give a bias to FAIL/PFAIL nodes. */
if (maxiterations > wanted*2 &&
!(this->flags & (REDIS_NODE_PFAIL|REDIS_NODE_FAIL)))
continue;
/* In the gossip section don't include:
* 1) Nodes in HANDSHAKE state.
* 3) Nodes with the NOADDR flag set.
* 4) Disconnected nodes if they don't have configured slots.
*/
if (this->flags & (REDIS_NODE_HANDSHAKE|REDIS_NODE_NOADDR) ||
(this->link == NULL && this->numslots == 0))
{
freshnodes--; /* Tecnically not correct, but saves CPU. */
continue;
}
/* Check if we already added this node */
for (j = 0; j < gossipcount; j++) {
if (memcmp(hdr->data.ping.gossip[j].nodename,this->name,
REDIS_CLUSTER_NAMELEN) == 0) break;
}
if (j != gossipcount) continue;
/* Add it */
freshnodes--;
gossip = &(hdr->data.ping.gossip[gossipcount]);
memcpy(gossip->nodename,this->name,REDIS_CLUSTER_NAMELEN);
gossip->ping_sent = htonl(this->ping_sent);
gossip->pong_received = htonl(this->pong_received);
memcpy(gossip->ip,this->ip,sizeof(this->ip));
gossip->port = htons(this->port);
gossip->flags = htons(this->flags);
gossip->notused1 = 0;
gossip->notused2 = 0;
gossipcount++;
}
/* Ready to send... fix the totlen fiend and queue the message in the
* output buffer. */
totlen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
totlen += (sizeof(clusterMsgDataGossip)*gossipcount);
hdr->count = htons(gossipcount);
hdr->totlen = htonl(totlen);
clusterSendMessage(link,buf,totlen);
zfree(buf);
}
以上函数定义了发送PING包的逻辑,重点是wanted变量的计算方式,也就是每次PING包内要携带多少个其他节点信息发送。可以看到,wanted最小3个,最大不超过集群总实例数-2个,一般情况是 集群实例数的1/10个。
再来看看每个gossip包的大小:
typedef struct {
/* REDIS_CLUSTER_NAMELEN是常量40 */
char nodename[REDIS_CLUSTER_NAMELEN];
uint32_t ping_sent;
uint32_t pong_received;
char ip[REDIS_IP_STR_LEN]; /* IP address last time it was seen */
uint16_t port; /* port last time it was seen */
uint16_t flags; /* node->flags copy */
uint16_t notused1; /* Some room for future improvements. */
uint32_t notused2;
} clusterMsgDataGossip;
看到这里就明白了,总线传播的数据量wanted是一个变量,会随着集群实例数的增多而增多。当集群节点数不多时不会造成影响,但随着节点数变多,每次wanted要携带的节点信息也就随之变多,会导致对网卡的消耗越来越大。我压测时每台Redis服务器8主8从共16个节点,四台服务器共64个节点,每个节点每秒钟PING包都要携带6个gossip包的信息(64/10)。如果扩大到十台,就是每个节点每秒钟PING包要携带16个gossip包的信息(160/10)。
解决了网卡中断问题后,Redis实例的CPU不会再被中断抢走,QPS基本可以线性增长。在6台12coreCPU的Redis服务器上,总QPS可以到达200w/s以上,单机QPS在30w以上。
ps:
推荐一篇有关软中断的文章: http://huoding.com/2013/10/30/296