mahout算法源码分析之零:搭建环境及Canopy获得输入数据
使用软件:VMware6.5 、redhat、hadoop-1.0.4、eclipse、mahout-0.7(主机 为win7);
1.首先使用虚拟机搭建一个伪分布式hadoop集群,在主机的浏览器中输入: 虚拟机名:50030 ,查看集群状态(可以参考配置hosts文件);
2. 下载两个版本的mahout(以1.7为例),如下图所示:
其中mahout-distribution-0.7-src.zip 是等下要拷贝到eclipse工程下面的,mahout-distribution-0.7.zip中的mahout-* .jar要拷贝到集群的hadoop_home/lib下面的;
其中拷贝到eclipse工程下面的文件包括:E:\software\mahout-distribution-0.7-src\mahout-distribution-0.7\core\src\main\java 、E:\software\mahout-distribution-0.7-src\mahout-distribution-0.7\examples\src\main\java、E:\software\mahout-distribution-0.7-src\mahout-distribution-0.7\integration\src\main\java、E:\software\mahout-distribution-0.7-src\mahout-distribution-0.7\math\src\main\java;
3. 在eclipse的java工程中编写一个wordcount的简单测试程序,看是否可以调用虚拟机的hadoop集群,若可以即说明环境基本搭建ok。
由于本来是想分析KMeansDriver这个程序的,但是之前先分析CannopyDriver会好点,所以就先看这个类,最开始的想法是直接下载数据,然后跑出来结果,再根据结果来 分析源码;但是第一次没有跑通,原因是数据不对,数据要经过转换才行;
我使用的数据是Reuters dataset,根据mahout官网上面的 说明,需要经过下面的转换:

ExtractReuters这个类直接去网上下载即可,放入工程中相应的位置,然后编写一个简单的程序把刚才下载的数据转换,即第二步:
package mahout.test.kmeans.transform;
import java.io.File;
import org.apache.lucene.benchmark.utils.ExtractReuters;
public class SegToOut {
public static void main(String[] args) {
// TODO Auto-generated method stub
File in=new File("E:\\workspace\\MathTest1.0\\src\\mahout\\test\\kmeans\\transform\\in");
File out=new File("E:\\workspace\\MathTest1.0\\src\\mahout\\test\\kmeans\\transform\\out");
ExtractReuters eas=new ExtractReuters (in,out);
eas.extract();
}
}
第三步的seqdirectory 对应于SequenceFilesFromDirectory这个类,同样编写一个测试的小程序,进行数据的转换:
package mahout.test.kmeans.transform;
import org.apache.mahout.text.SequenceFilesFromDirectory;
public class TestFile2Seq {
public static void main(String[] args) throws Exception {
String[] arg={
"-fs hadoop:9000 ","-jt hadoop:9001"
," --input hdfs://hadoop:9000/user/fansy/hadoop/input/canopy"
," --output hdfs://hadoop:9000/user/fansy/out/canopy"};
System.out.println(args);
SequenceFilesFromDirectory se=new SequenceFilesFromDirectory();
se.run(arg);
System.out.println("job is done.");
}
}
但是上面的程序提示错误:
ERROR common.AbstractJob: Unexpected –fs通过进一步的调试,可以发现是在AbstractJob的347行出错,这个等于是识别不了-fs的前缀了(若arg={"--h"},那么可以打印该类的使用帮助),既然使用不了这个参数,那如何指定jobtracker呢?一种方法可以是:修改 SequenceFilesFromDirectory,把77行的
Configuration conf = getConf();替换为:
Configuration conf=new Configuration();
conf.set("mapred.job.tracker", "hadoop:9001");在此运行上面的测试小程序,即可在hdfs文件系统上看到转换后的结果,如下:
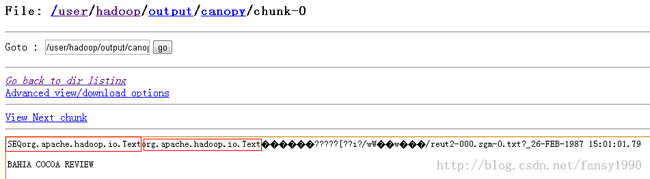
这说明文件已经被转换为序列文件了,并且他的key是Text类型,Value也是Text类型的,第三步完成;
下面进行最后一步,即把seq转换为vector,其对应的类是:SparseVectorsFromSequenceFiles,这个转换和上面的差不多,如果不改Configuration的话直接运行会出现下面的错误:
13/07/20 22:48:57 INFO vectorizer.SparseVectorsFromSequenceFiles: Maximum n-gram size is: 1 13/07/20 22:48:57 INFO vectorizer.SparseVectorsFromSequenceFiles: Minimum LLR value: 1.0 13/07/20 22:48:57 INFO vectorizer.SparseVectorsFromSequenceFiles: Number of reduce tasks: 1 Exception in thread "main" java.lang.NullPointerException at org.apache.hadoop.conf.Configuration.<init>(Configuration.java:264) at org.apache.mahout.vectorizer.DocumentProcessor.tokenizeDocuments(DocumentProcessor.java:72) at org.apache.mahout.vectorizer.SparseVectorsFromSequenceFiles.run(SparseVectorsFromSequenceFiles.java:253) at mahout.test.kmeans.transform.TestSeq2Vec.main(TestSeq2Vec.java:16)同样修改 SparseVectorsFromSequenceFiles的250行的 Configuration conf=getConf(); 改为Configuration conf=new Configuration();
conf.set("mapred.job.tracker", "hadoop:9001");即可,这样即可获得CanopyDriver需要的输入数据格式了。
这个有三个job的,但是跑最后一个job的时候运行错误:
13/07/20 22:57:00 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 13/07/20 22:57:01 INFO input.FileInputFormat: Total input paths to process : 1 13/07/20 22:57:02 INFO mapred.JobClient: Running job: job_201306162355_0004 13/07/20 22:57:03 INFO mapred.JobClient: map 0% reduce 0% 13/07/20 22:57:24 INFO mapred.JobClient: map 8% reduce 0% 13/07/20 22:57:27 INFO mapred.JobClient: map 32% reduce 0% 13/07/20 22:57:30 INFO mapred.JobClient: map 100% reduce 0% 13/07/20 22:57:51 INFO mapred.JobClient: Task Id : attempt_201306162355_0004_r_000000_0, Status : FAILED java.lang.IllegalStateException: /user/hadoop/output/canopyvec/dictionary.file-0 at org.apache.mahout.common.iterator.sequencefile.SequenceFileIterable.iterator(SequenceFileIterable.java:63) at org.apache.mahout.vectorizer.term.TFPartialVectorReducer.setup(TFPartialVectorReducer.java:130) at org.apache.hadoop.mapreduce.Reducer.run(Reducer.java:174) at org.apache.hadoop.mapred.ReduceTask.runNewReducer(ReduceTask.java:649) at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:417) at org.apache.hadoop.mapred.Child$4.run(Child.java:255) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1121) at org.apache.hadoop.mapred.Child.main(Child.java:249) Caused by: java.io.FileNotFoundException: File file:/user/hadoop/output/canopyvec/dictionary.file-0 does not exist. at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:397) at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:251) at org.apache.hadoop.fs.FileSystem.getLength(FileSystem.java:796) at org.apache.hadoop.io.SequenceFile$Reader.<init>(SequenceFile.java:1475) at org.apache.hadoop.io.SequenceFile$Reader.<init>(SequenceFile.java:1470) at org.apache.mahout.common.iterator.sequencefile.SequenceFileIterator.<init>(SequenceFileIterator.java:58) at org.apache.mahout.common.iterator.sequencefile.SequenceFileIterable.iterator(SequenceFileIterable.java:61) ... 9 more我去hdfs上面看确实是有这个错误的,但是还是提示找不到这个文件? 看他的路径怎么好像是访问本地的?,根据提示找到TFPartialVectorReducer.java:130可以看到引用了一个SequenceFileIterable,那我直接把这里的path打印出来看看是什么先,修改SequenceFileIterable的构造函数加上一个打印的语句,但是这个没有效果,打印不了()
所以再继续看,找到TFPartialVectorReducer的第118行可以看到:
URI[] localFiles = DistributedCache.getCacheFiles(conf);所以我们要把 找不到的那个文件的目录添加一个cacheFiles,具体做法是在:
Configuration conf=new Configuration();
conf.set("mapred.job.tracker", "hadoop:9001");后面加上:
DistributedCache.addCacheFile(new Path("hdfs://hadoop:9000/user/hadoop/output/canopyvec04/dictionary.file-0").toUri(), conf);但是还是不行,明天继续。。。
分享,快乐,成长
转载请注明出处:http://blog.csdn.net/fansy1990