Lucene学习总结之七:Lucene搜索过程解析(6)
2.4、搜索查询对象
2.4.3、进行倒排表合并
在得到了Scorer对象树以及SumScorer对象树后,便是倒排表的合并以及打分计算的过程。
合并倒排表在此节中进行分析,而Scorer对象树来进行打分的计算则在下一节分析。
BooleanScorer2.score(Collector) 代码如下:
| public void score(Collector collector) throws IOException { collector.setScorer(this); while ((doc = countingSumScorer.nextDoc()) != NO_MORE_DOCS) { collector.collect(doc); } } |
从代码我们可以看出,此过程就是不断的取下一篇文档号,然后加入文档结果集。
取下一篇文档的过程,就是合并倒排表的过程,也就是对多个查询条件进行综合考虑后的下一篇文档的编号。
由于SumScorer是一棵树,因而合并倒排表也是按照树的结构进行的,先合并子树,然后子树与子树再进行合并,直到根。
按照上一节的分析,倒排表的合并主要用了以下几个SumScorer:
- 交集ConjunctionScorer
- 并集DisjunctionSumScorer
- 差集ReqExclScorer
- ReqOptSumScorer
下面我们一一分析:
2.4.3.1、交集ConjunctionScorer(+A +B)
ConjunctionScorer中有成员变量Scorer[] scorers,是一个Scorer的数组,每一项代表一个倒排表,ConjunctionScorer就是对这些倒排表取交集,然后将交集中的文档号在nextDoc()函数中依次返回。
为了描述清楚此过程,下面举一个具体的例子来解释倒排表合并的过程:
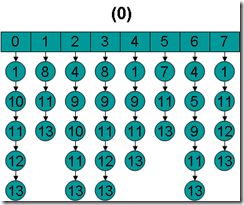
(1) 倒排表最初如下:
(2) 在ConjunctionScorer的构造函数中,首先调用每个Scorer的nextDoc()函数,使得每个Scorer得到自己的第一篇文档号。
| for (int i = 0; i < scorers.length; i++) { if (scorers[i].nextDoc() == NO_MORE_DOCS) { //由于是取交集,因而任何一个倒排表没有文档,交集就为空。 lastDoc = NO_MORE_DOCS; return; } } |
(3) 在ConjunctionScorer的构造函数中,将Scorer按照第一篇的文档号从小到大进行排列。
| Arrays.sort(scorers, new Comparator<Scorer>() { public int compare(Scorer o1, Scorer o2) { return o1.docID() - o2.docID(); } }); |
倒排表如下:

(4) 在ConjunctionScorer的构造函数中,第一次调用doNext()函数。
| if (doNext() == NO_MORE_DOCS) { lastDoc = NO_MORE_DOCS; return; } |
| private int doNext() throws IOException { int first = 0; int doc = scorers[scorers.length - 1].docID(); Scorer firstScorer; while ((firstScorer = scorers[first]).docID() < doc) { doc = firstScorer.advance(doc); first = first == scorers.length - 1 ? 0 : first + 1; } return doc; } |
姑且我们称拥有最小文档号的倒排表称为first,其实从doNext()函数中的first = first == scorers.length - 1 ? 0 : first + 1;我们可以看出,在处理过程中,Scorer数组被看成一个循环数组(Ring)。
而此时scorer[scorers.length - 1]拥有最大的文档号,doNext()中的循环,将所有的小于当前数组中最大文档号的文档全部用firstScorer.advance(doc)(其跳到大于或等于doc的文档)函数跳过,因为既然它们小于最大的文档号,而ConjunctionScorer又是取交集,它们当然不会在交集中。
此过程如下:
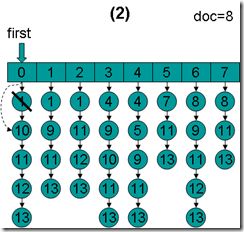
- doc = 8,first指向第0项,advance到大于8的第一篇文档,也即文档10,然后设doc = 10,first指向第1项。
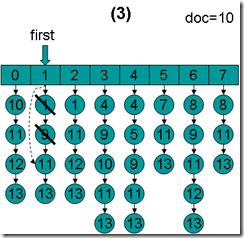
- doc = 10,first指向第1项,advance到文档11,然后设doc = 11,first指向第2项。
- doc = 11,first指向第2项,advance到文档11,然后设doc = 11,first指向第3项。

- doc = 11,first指向第3项,advance到文档11,然后设doc = 11,first指向第4项。
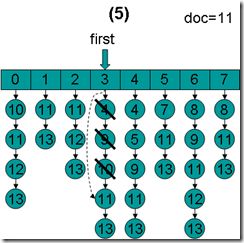
- doc = 11,first指向第4项,advance到文档11,然后设doc = 11,first指向第5项。

- doc = 11,first指向第5项,advance到文档11,然后设doc = 11,first指向第6项。
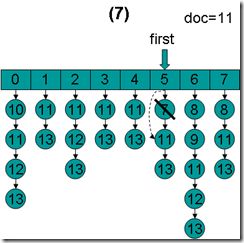
- doc = 11,first指向第6项,advance到文档11,然后设doc = 11,first指向第7项。

- doc = 11,first指向第7项,advance到文档11,然后设doc = 11,first指向第0项。
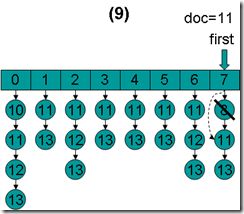
- doc = 11,first指向第0项,advance到文档11,然后设doc = 11,first指向第1项。
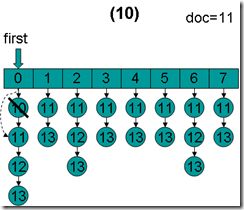
- doc = 11,first指向第1项。因为11 < 11为false,因而结束循环,返回doc = 11。这时候我们会发现,在循环退出的时候,所有的倒排表的第一篇文档都是11。
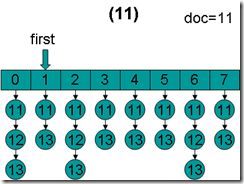
(5) 当BooleanScorer2.score(Collector)中第一次调用ConjunctionScorer.nextDoc()的时候,lastDoc为-1,根据nextDoc函数的实现,返回lastDoc = scorers[scorers.length - 1].docID()也即返回11,lastDoc也设为11。
| public int nextDoc() throws IOException { if (lastDoc == NO_MORE_DOCS) { return lastDoc; } else if (lastDoc == -1) { return lastDoc = scorers[scorers.length - 1].docID(); } scorers[(scorers.length - 1)].nextDoc(); return lastDoc = doNext(); } |
(6) 在BooleanScorer2.score(Collector)中,调用nextDoc()后,collector.collect(doc)来收集文档号(收集过程下节分析),在收集文档的过程中,ConjunctionScorer.docID()会被调用,返回lastDoc,也即当前的文档号为11。
(7) 当BooleanScorer2.score(Collector)第二次调用ConjunctionScorer.nextDoc()时:
- 根据nextDoc函数的实现,首先调用scorers[(scorers.length - 1)].nextDoc(),取最后一项的下一篇文档13。

- 然后调用lastDoc = doNext(),设doc = 13,first = 0,进入循环。
- doc = 13,first指向第0项,advance到文档13,然后设doc = 13,first指向第1项。
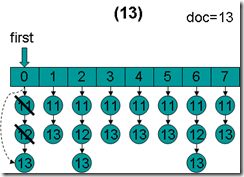
- doc = 13,first指向第1项,advance到文档13,然后设doc = 13,first指向第2项。
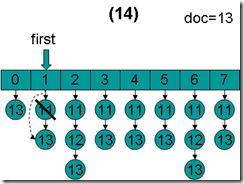
- doc = 13,first指向第2项,advance到文档13,然后设doc = 13,first指向第3项。

- doc = 13,first指向第3项,advance到文档13,然后设doc = 13,first指向第4项。
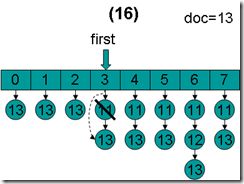
- doc = 13,first指向第4项,advance到文档13,然后设doc = 13,first指向第5项。

- doc = 13,first指向第5项,advance到文档13,然后设doc = 13,first指向第6项。
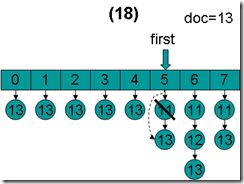
- doc = 13,first指向第6项,advance到文档13,然后设doc = 13,first指向第7项。
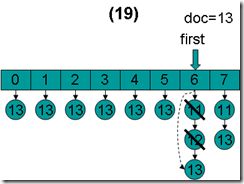
- doc = 13,first指向第7项,advance到文档13,然后设doc = 13,first指向第0项。
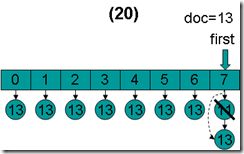
- doc = 13,first指向第0项。因为13 < 13为false,因而结束循环,返回doc = 13。在循环退出的时候,所有的倒排表的第一篇文档都是13。
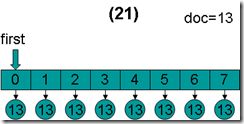
(8) lastDoc设为13,在收集文档的过程中,ConjunctionScorer.docID()会被调用,返回lastDoc,也即当前的文档号为13。
(9) 当再次调用nextDoc()的时候,返回NO_MORE_DOCS,倒排表合并结束。