Nutch0.9安装指南
终于!我把Nutch0.9的安装文档贴出来了
首先提醒的是,按照这个步骤做还是会遇到各种莫名奇妙的问题,没关系,按照步骤查找,一定有地
方出错了,从出错的地方重新做吧。(连我自己每次重新安装的时候还是会遇到各种问题,所以过程
一定要细心啊!)
直接上过程:
1、首先,我的配置:JDK1.6,Tomcat6.0,Nutch0.9
2、添加JAVA_HOME和CATALINA_HOME系统变量(这个如果真不会的话自己百度吧)
3、安装Cygwin。
Nutch最初是在Linux系统下开发的,所以要在windows环境下部署,必须使用这个软件来模拟仿真
系统环境。
下载了Cygwin后,双击setup.exe运行,在“选择下载资源”的对话框处有几个选项:从
Internet安装、下载不安装、从本地安装。一般是第一个选项,如果已经安装包已经下载到了本地,
那么选择第三个。之后设置好安装路径按默认的设置安装即可。
安装成功运行如图:
4、Nutch是用Java语言开发的,在运行Nutch之前,必须告诉Nutch系统的JDK在哪。所以还需要设置
一个环境变量NUTCH_HOME,值同JAVA_HOME一致。
设置好了可以通过Cygwin测试Nutch是否可以运行。
1. 运行Cygwin。
2. 输入:cd /cygdrive/*/nutch-0.9 (nutch所在的路径) PS:Cygwin不支持Unicode字符
集,所以在设置Nutch路径时,要保证其中没有中文字符
3. 测试Nutch命令:bin/nutch。如果Nutch安装正确,则此命令会返回所有的Nutch可执行命
令结果
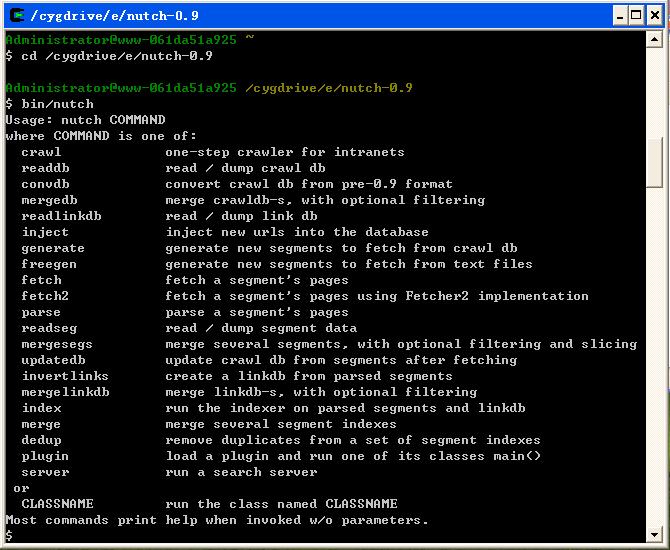
这时Nutch已经可以运行,通过Cygwin运行Nutch的底层命令,已经可以进行抓取、索引、排序、检索等功能。但是做进一步的开发还需要进一步的修改。
5、将Nutch导入Eclipse
同导入其他Eclipse工程的过程一样,不过要注意几点:
(1)将Nutch的配置文件加入到工程的Librares中,在Libraries选择Add Classic Folder。并在第
四个面板“Order and Export”中,把conf置顶
(2)将output dir改为:tmp_build
(3)导入完成
(4)但编译还是不会通过的,因为Nutch包含的rtf和mp3包和Nutch使用的是不同的开源协议,所以
我们需要单独下载这两个包,把他们添加进工程中。下载地址为:
http://nutch.cvs.sourceforge.net/nutch/nutch/src/plugin/parse-mp3/lib/
http://nutch.cvs.sourceforge.net/nutch/nutch/src/plugin/parse-rtf/lib/
6、Nutch的配置文件
Nutch的基本配置文件都在conf文件夹下,之前已经把它添加到Class Folder中了
nutch-default.xml:我们会用到最多的配置文件,一定要好好读读其中的内容
crawl-urlfilter.txt:Nutch抓取是的一些策略设置
nutch-site.xml:抓取时提交给被爬行网站的信息
………………
最好自己都读一下这些配置文件的内容并了解它们的作用
7、建立网页抓取入口
在工程文件夹下新建一个文本文件做为爬虫抓取网页的入口:weburl.txt。
这里我是在Tomcat下部署了一个网站用做测试,各位照样子填吧
http://localhost:8080/computernetwork/index.html
8、修改配置文件
(1)打开conf下的nutch-default.xml文件,这里我们要修改其中的一个属性:plugin.folders。
把它修改为“.\plugins”。它的设置告诉Nutch应该到哪里去查找插件。
(2)
修改crawl-urlfilter.txt:
# skip image and other suffixes we can't yet parse
-\.
(gif|GIF|jpg|JPG|png|PNG|ico|ICO|css|sit|eps|wmf|zip|ppt|mpg|xls|gz|rpm|tgz|mov|MOV|
exe|jpeg|JPEG|bmp|BMP|swf|doc)$
这是Nutch抓取网页时默认忽略的文件类型
# accept hosts in MY.DOMAIN.NAME
#+^http://([a-z0-9]*\.)*MY.DOMAIN.NAME/
这是Nutch抓取是的限制访问策略。比如我的是:+^http:// localhost:8080/computernetwork/
那么如果抓取的网页中含有链接到其他站点的URL,Nutch不会去抓取这些网页。
(3)
修改nutch-site.xml
<name>http.agent.name</name>
<value>Local</value>
<description>HTTP 'User-Agent' request header. MUST NOT be empty - please set this to a single word uniquely related to your organization. NOTE: You should also check other related properties:
http.robots.agents
http.agent.description
http.agent.url
http.agent.email
http.agent.version
and set their values appropriately.
</description>
</property>
<property>
<name>http.agent.description</name>
<value> Local web</value>
<description>Further description of our bot- this text is used in
the User-Agent header. It appears in parenthesis after the agent name.
</description>
</property>
<property>
<name>http.agent.url</name>
<value>http://MyCom.com</value>
<description>A URL to advertise in the User-Agent header. This will appear in parenthesis after the agent name. Custom dictates that this should be a URL of a page explaining the purpose and behavior of this crawler.
</description>
</property>
<property>
<name>http.agent.email</name>
<value> Your mail@*.com</value>
<description>An email address to advertise in the HTTP 'From' request header and User-Agent header. A good practice is to mangle this address (e.g. 'info at example dot com') to avoid spamming.
</description>
</property>
9、配置Eclipse运行参数
“Run as”—>“Run Configuration” —>“Java Application”
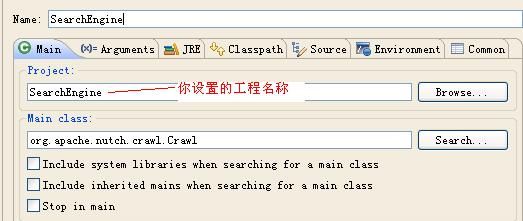
Arguments面板中:
在Program arguments中,参数为:
weburl.txt -dir Local –depth 5 –topN 100 –threads 100
指的是爬虫爬取网页的地址入口在weburl.txt中设置,爬取的网页、索引等信息存在本地Local文
件夹中,爬虫爬取的深度为:5,每层只爬取前100个网页,同时开100个线程进行爬取。
在VM arguments中,设置参数为:
-Dhadoop.log.dir=logs –Dhadoop.log.file=hadoop.log –Xmx512m
这设置的是爬取过程的Log日志记录地址。另外,爬取网页过多时Nutch会出现JavaVM溢出的错
误,因此经常还需在此处设置JavaVM参数,如:-Xmx512m,即为JAVA虚拟机分配内存大小为512M。
10、运行。
运行之后,在Nutch中的Local文件夹下会生成5个文件夹:
crawldb:下载的URL及下载日期,用于存放页面更新的检查时间。
linkdb:存放URL的互联关系,是下载完成后分析得到的。
segments:存放抓取的页面。下面的子目录数与获取页面层数有关。通常是一层一个文件夹。
indexs:存放每次下载的独立索引目录。
index:符合Lucene格式的索引目录,是indexs里所有index合并后的完整索引。
11、部署到tomcat
(1)打开ANT面板,打开添加Buildfiles对话框,将Nutch的build.xml添加进来。
(2)重新运行job(default)或者war。此处会出现一个build failed错误,出现在文件中的:
<touch datetime="01/25/1971 2:00 pm">
<fileset dir="${conf.dir}" includes="**/*.template"/>
</touch>
原因是因为在Nutch工程中没有*.template文件,所以可以把这几句删除掉(也不需要去下载这
几个文件。如果使用了这几个文件,每次编译后曾经修改过的配置文件会被改回模板中的原始值。)
(3)将build文件夹下的nutch-0.9.war复制到CATALINA_HOME下的webapps下,重新启动Tomcat,将生
成的nutch-0.9文件夹放到ROOT文件夹下。
访问:http://localhost:8080/nutch-0.9
(我是将nutch文件夹下的所有文件直接放在了ROOT文件夹下,所以直接访问http://localhost:8080/)
12、开始搜索
在CATALINA_HOME\webapps\ROOT\nutch-0.9\WEB-INF\classes下,找到nutch-site.xml,
添加属性:
<property>
<name>searcher.dir</name>
<value>E:\nutch-0.9\Local</value>----------注:nutch工程下抓取时设置的文件夹位置
</property>
这个属性告诉Tomcat到哪里去找Nutch索引。
------想搜索吗?No!还有东西要改!
这时要是直接搜索,Tomcat会提示你:
org.apache.jasper.JasperException: /search.jsp(151,22) Attribute value language + "/include/header.html" is quoted with " which must be escaped when used within the value
找到search.jsp下的151行,把引号转义吧。。。。
<jsp:include page="<%= language + \"/include/header.html\"%>"/>
想搜索吗?可以试一下
结果是——英文可以了,但是中文会出现乱码
还得改。。。。那就改吧
在CATALINA_HOME\conf下找到server.xml
修改Connector port="8080" protocol="HTTP/1.1"属性中的值,添加两句:
URIEncoding="UTF-8" useBodyEncodingForURI="true"
----------------------------------------
Oh My God!终于可以搜了!!!撒花庆祝吧!这里是真的可以了
可是只有这些吗?
No!这只是搭建一个基本的基于Nutch的搜索平台。实际上基于Nutch还有很多可以做和扩展。
PS:这些都是百度、Google出来的各种方法的整理,本人已经实践过多次,绝对可以部署实施,但是过程中可能还是会出现各种问题,大家耐心的修改吧!
由于时间稍久,中间可能存在疏漏,而且对Nutch学习也并不深入,如发现错误,欢迎大家交流指正!