首先,有必要了解下记事本文件的几种编码方式:
四种常见文本文件编码方式研究
ANSI、UNICODE 、UNICODE big endian、UTF-8四种格式编码存在差别,简要介绍如下:
ANSI编码:
无文件头(文件编码开头标志性字节)
ANSI编码字母数字占一个字节,汉字占两个字节,
回车换行符 单字节 十六进制表示为0d 0a
UNICODE编码:
文件头,十六进制表示为FF FE
每一个字符都用两个字节编码
回车换行符 双字节 000d 000a
Unicode big endian编码:
文件头十六进制表示为FE FF ,
后面编码是把字符的高位放在前面,低位放在后面,正好和Unicode编码颠倒。
回车换行符,双字节,十六进制表示为0d00 0a00
UTF-8 编码:
文件头,十六进制表示为EF BB BF。
UTF-8是Unicode的一种变长字符编码,数字、字母、回车、换行都用一个字节表示,汉字占3个字节.
回车换行符,单字节,十六进制表示为0d 0a
以中文"你好"二字为例,各种类型的编码对应的十六进制格式(可由EditPlus查看)如下图所示:
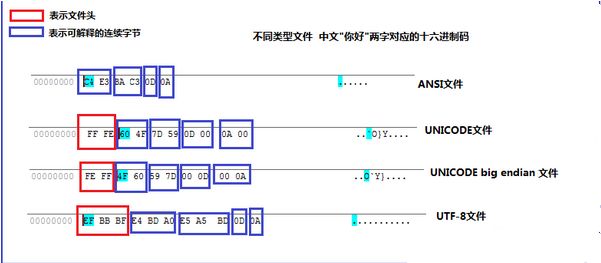
一个汉字在Unicode中用两个字节表示,a-z等字母也是两个字节。
UTF-8是Unicode的一种表现形式(Unicode编码值使用UTF-8方式编码存储),是一种变长的表达方式,把字符的Unicode编码在文件中表现出来,从一个字节到三个字节不等(为了减少如a-z等ascii码字符占用的空间,因为他们出现太频繁了).
UTF-8编码范围为:
0000 - 007F : 0xxxxxxx
0080 - 07FF : 110xxxxx 10xxxxxx
0800 - FFFF : 1110xxxx 10xxxxxx 10xxxxxx
如"汉"的Unicode编码为6C49,在0800 - FFFF之间,所以要使用3字节模板: 1110xxxx 10xxxxxx 10xxxxxx
6C49的二进制是: 0110 110001 001001
用这个二进制流依次代替3字节模板中的x得: 1110 0110 10110001 10001001,即E6 B1 89
保存到文件中的就是3个字节E6 B1 89,而不是2个字节6C 49
// 给InputStreamReader指定要读取的文件的编码,读取时就不会出现乱码了.
public class TextFileReader {
public static void main(String[] args) throws Exception {
String filename = "source/demo.txt";
String encoding = "Unicodelittle";
printFile(filename, encoding);
}
// 打印出文件的文本内容, 使用指定的编码读入文件
public static void printFile(String filename, String encoding) throws IOException {
InputStreamReader isr = new InputStreamReader(new FileInputStream(filename), encoding);
BufferedReader reader = new BufferedReader(isr);
String line = null;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
}
}
文本编码方式是unicode,在读取文件流时需要指定encoding为unicodelittle。
文本编码方式是unicode big endian, 在读取文件时指定encoding为unicode。
在写文件时,当encoding指定为unicode时,生成的文本文件的编码格式为unicode big endian,故需指定为unicodelittle。
若为ANSI 编码,在文件流操作时,不需要指定编码方式,使用默认即可。
参考文献:
http://www.cppblog.com/biao/archive/2012/10/19/137637.html
http://blog.csdn.net/soleghost/article/details/959832
http://bbs.csdn.net/topics/330045908
http://www.chengxuyuans.com/code/C++/63390.html