今天在将hdfs的数据插入数据库时 报错:
java.io.IOException: ORA-00911: invalid character
咋一看此乃ORACLE的独家错误啊 , 难道是SQL写错了?
再仔细看 这个报的错是IO的问题!
顿时头大啊 这.... 怎么一回事啊!
没办法只有打断点跟程序 一步一步的运行了
在org.apache.hadoop.mapreduce.lib.db.DBOutputFormat.DBRecordWriter.close(TaskAttemptContext context)throws IOException ; 的第110行报错.throw new IOException(ex.getMessage());
public void close(TaskAttemptContext context) throws IOException {
try {
statement.executeBatch();
connection.commit();
} catch (SQLException e) {
try {
connection.rollback();
}
catch (SQLException ex) {
LOG.warn(StringUtils.stringifyException(ex));
}
throw new IOException(e.getMessage());
} finally {
try {
statement.close();
connection.close();
}
catch (SQLException ex) {
throw new IOException(ex.getMessage());
}
}
}
根据断点可以判断程序是在结束所有的reduce方法(?存在疑问因为测试数据较少无法检测多reduce的情况)
后执行的批量数据插入操作,故需要查看设置SQL是否有问题。
继续往下看到了reduce方法中 Context.write的实现
public void write(K key, V value) throws IOException {
try {
key.write(statement);
statement.addBatch();
} catch (SQLException e) {
e.printStackTrace();
}
}
在上面的方法中可以发现 传入的value根本没有用; 真正用到的只有key。因此在导出数据库的reduce中可以使用常量来表示value,从而避免无畏的内存消耗。
继续往下看org.apache.hadoop.mapreduce.lib.db.DBOutputFormat的其它方法,发现了constructQuery ()
观其方法内的拼接 SQL字符串的实现,判断:此方法就是插入操作的具体实现
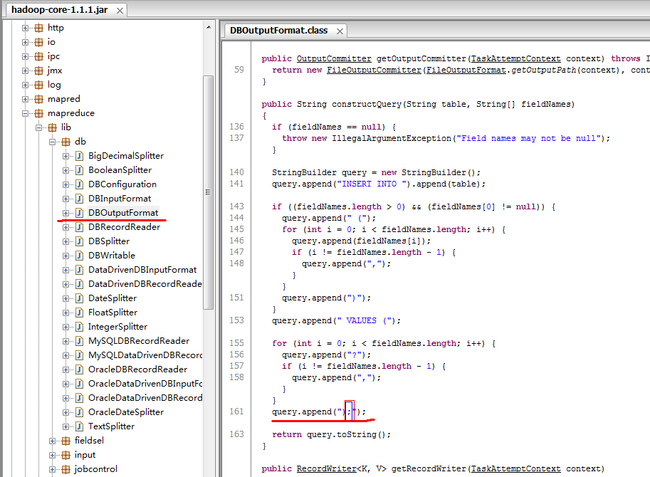
在返回拼接字符串的最后 发现了括号内红色标记的分号;
我们知到在JAVA程序中拼接的SQL末尾是不能 加分号的,会不会就是这货造成的SQL错误呢?
由于源代码只读,因此需要在项目中添加同名DBOutputFormat.java文件
并放在当前项目的与源文件同名的org.apache.hadoop.mapreduce.lib.db.DBOutputFormat的包下
去除 刚刚找到的分号 运行程序 一切正常,接着查看出数据库 发现数据已成功添加.
结论:罪魁祸首 就是这个不起眼的分号!
后记 将自己写的DBOutputFormat.ava 打JAR包,然后用压缩文件的格式打开找到DBOutputFormat.class并替换hadoop-core-1.1.1.jar中的DBOutputFormat.class,而不用每次都重写它的方法了。直接javac 会报依赖错误。