http://blog.sina.com.cn/s/blog_4caedc7a0102ewpj.html
编者按:在过去几十年,人们曾尝试采用直接编辑知识、利用大众智慧、自动或半自动知识抽取三类方法来构建知识库。随着时代发展,直接编辑知识由于受时间和经济成本的约束,这种方式很难实现大规模知识库的构建。而利用大众智慧是指利用互联网众包机制,过于依赖激励机制将降低知识库运行稳定性。微软亚洲研究院主管研究员史树明在本文中重点讨论第三类方法——自动或半自动知识抽取,其基本思想是设计自动或半自动的算法,从现有的(自然语言)文档中提取知识。这个过程又被称为信息提取,定义为从非结构化和半结构化文本中提取结构化信息。
微软亚洲研究院主管研究员 史树明
正如动物依靠对环境和食物的认知来维持生存、人类依靠知识和技能来扮演社会角色一样,计算机应用程序和系统也依赖特定的“知识”来完成特定的功能。近些年,包括互联网搜索系统、自动导航系统、自动问答系统、机器翻译系统、语音识别系统等在内的智能系统取得了巨大进展,其背后是更深、更广、更新和更加准确的知识库的构建和使用。
人类通过五官来获取知识,并通过语言和文字来实现知识的交流、共享和传承,由此建立起人类庞大的知识体系。然而,这些丰富的知识并不能够被计算机系统自然而直接地使用,原因在于当前的计算机程序远未达到理解自然语言和洞悉人类智慧的程度和水平(甚至不少人怀疑这一天能否到来)。而我们又确实需要计算机系统能够具备一些知识,以便在不威胁到人类生存的前提下帮助人类完成一些“高级”任务。因此,我们的目标便自然地设定为以合理的代价构建一个尽可能丰富、准确和与时俱进的知识库。
在过去几十年,人们曾尝试采用直接编辑知识、利用大众智慧、自动或半自动知识抽取三类方法来构建知识库。
直接编辑知识是指知识编辑人员把自己头脑中的知识写成计算机能够处理的格式,例如把“狗是一种动物”写成“IsA(狗,动物)”。在这种情况下,知识的编辑工作通常由从事知识库构建的研发人员或者数据标定人员来完成。受时间和经济成本的约束,这种方式很难实现大规模知识库的构建。利用大众智慧是指利用互联网众包机制,把知识编辑工作交给成千上万的互联网志愿者大军,知识库Freebase的维护就依赖于这种机制。众包的核心是设计合理的激励机制,使互联网用户利用业余时间向知识库贡献一些信息。本文重点讨论第三类方法——自动或半自动知识抽取,其基本思想是设计自动或半自动的算法,从现有的(自然语言)文档中提取知识。这个过程又被称为信息提取,定义为从非结构化和半结构化文本中提取结构化信息。由于抽取算法的选择往往依赖于所要进行的知识提取任务,因此我们首先介绍知识类型和提取任务。
知识类型和知识提取任务
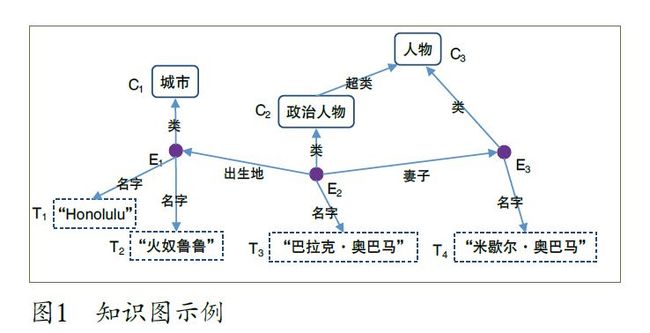
当前多数智能系统所涉及到的主要知识基本上可以表示为一个包含多种不同类型的结点和边的知识图以及图结点之间的关系集合。图1 展示了一个简单的知识子图,而表1 则列举了此子图上一些结点之间的关系。
知识类型
知识图中可能包含三类结点:
实体 如某一个人物、某一个国家、某一个机构、某一条狗、某一种编程语言、某一个学科等。图1 中的实体包括E1、E2 和E3。
语义类 一种类型的实体或一些实体的集合,如国家、亚洲国家、动物、山脉等。图1 中C1、C2、C3 为语义类。
文本 通常作为实体和语义类的名字、描述等,如图1 中的T1~T4。
知识图中结点之间的边的类型包括:
实体—语义类 从一个实体指向它所属的语义类。此类型的边在图1 中标记为“类”。
子类—父类 从一个语义类指向其父类,在图1 中用“超类”来标识。
属性 从一个实体指向它的属性值。不同的属性类型对应于不同类型的边,如图1 中“出生地”和“妻子”是两种不同的属性。所有实体和语义类都拥有一个特殊的属性“名字”,它指向文本类型的结点,表示此实体或语义类的名字或自然语言表达(如中文名、英文名等)。
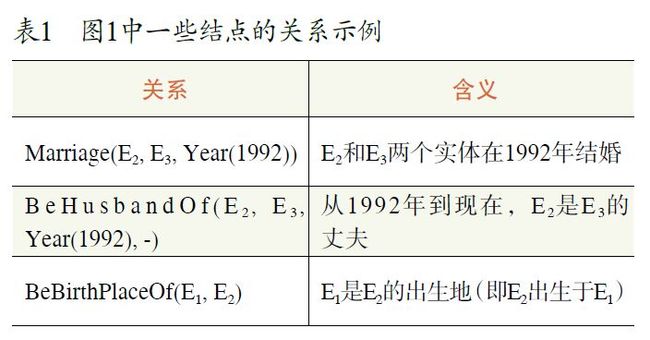
对于“关系”,维基百科给出了很好的定义和描述,即关系是一个函数,它把k 个点映射到一个布尔值。例如,假设关系R(X, Y, Z) 表示“X 认为Y 喜欢Z”,则当且仅当“张三认为李四喜欢王五”时,R( 张三, 李四, 王五)=TRUE。
如果把上述定义直接运用到知识库上,关系则是一个把k 个图结点(实体、语义类或文本结点)
映射到布尔值的函数。值得注意的是,有一类特殊的关系叫做事件,其特点是函数参数中包含时间,并且对应于一个或多个动作1。属性也可以看作是一种特殊的(二元)关系,即从实体和属性值到布尔值的映射。
权重的重要性
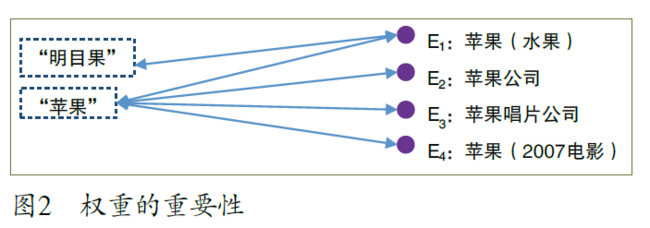
在知识图的结点和边上附加合适的权重对于上层应用至关重要。结点权重的重要性类似于互联网搜索中的网页等级,它通常标识着结点出现的频度或结点的先验概率。而将边的权重和结点的权重结合起来可以用来计算在给定一个结点的情况下其它结点出现的后验概率。例如在图2中,如果边和结点的权重都是合理的,上层应用就可以知道,对于实体E1 来说,“苹果”比“明目果”更常见,在文章中提到“苹果”时,在更多的情况下是指E1 或E2 而不是E3 或E4。权重信息通常需要通过自动或者半自动统计的方法而不是通过人的编辑而得到。
知识提取任务
知识提取的主要任务就是构建知识图以及生成图结点间的关系,具体子任务包括:
实体名提取 提取实体名并构造实体名列表。
语义类提取 构造语义类并建立实体(或实体名)和语义类的关联。
属性和属性值提取 为语义类构造属性列表,并提取类中所包含实体(或实体名)的属性值。
关系提取 构造结点间的关系函数,并提取满足关系的结点元组。
知识提取方法
知识提取方法的典型输入是自然语言文本(如句子)或带标记的自然语言文档(如网页、搜索引擎查询日志等),输出是知识图的子图或者关系集合的子集。针对每一种知识提取任务,都有大量的方法被提出来。本文重点选取了简单、有效、扩展性良好的方法,而避开那些看上去似乎很有技术含量实则堪称“鸡肋”的方法。
实体名提取
实体名提取的任务是构建一个词表,词表中主要包含实体名(如“中国”),同时也包括语义类的名称(或称类型名,如“国家”)。常见的词表构建方法有:从百科类站点中提取,从垂直站点中提取,利用模式从网页和句子中提取,以及利用命名实体识别(named entity recognition, NER)技术从自然语言句子中提取。
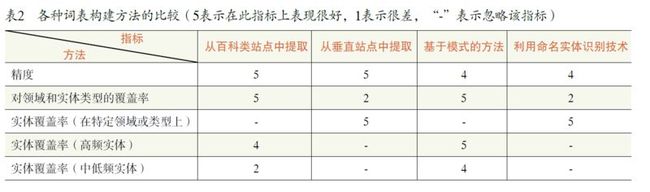
最简单的方法是从百科类站点(如维基百科、百度百科、互动百科等)的标题和链接中提取实体名。这种方法的优点是能够得到开放域上几乎所有类型的最常见的实体名,其缺点是对于中低频实体的覆盖率较低。相比而言,针对某些垂直网站而特别设计的抽取算法则可以在特定类型和领域上实现很高的覆盖率。例如,从亚马逊网站上可以抽取到几千万本书的信息,这个数量超过英文维基百科的词条数目。这种方法的缺点是在试图扩展到所有领域和实体类型时,会有比较大的开销(需要针对每个网站设计抽取算法)或牺牲精度(设计通用抽取算法),同时很难保证所有类型的实体都有对应的垂直站点。基于模式的方法从网页和句子中抽取词的并列相似度和上下位关系信息,其副产品是一个词表。这种方法能够覆盖比较广的领域和实体类型,与从百科类站点提取实体名的方法相比,对中低频词具有更高的覆盖率,但所得到的词表精度要低。
命名实体识别技术主要用来从句子中提取命名实体并标记它们的类型(研究比较多的类型包括人名、地名和机构名)。其输入是一个无结构的句子,输出是标记了命名实体类型的句子。只要将此技术作用于大量的句子并把所标记的命名实体聚集起来,便可以得到一个词表,因此该技术的一个直接应用就是构建词表(尽管其更为重要的应用是提取句子的特征和理解句子)。最早的命名实体识别主要采用手工定义的规则,后来出现了基于少量种子实体(对每种实体类型而言)的半监督方法,如自助法或者自举法。研究人员进一步提出了各种各样的基于监督的方法来提高性能。基于命名实体识别的词表构建方法能够得到不错的精度,并且能够在有训练数据的实体类型上达到较高的覆盖率。它的主要缺点是需要针对每种实体类型来提供种子实体或者其它训练数据,因此难以扩展到开放域和所有类型的对象。
各种词表构建方法的对比参见表2。多种方法的结合有望达到更好的综合效果。
、
语义类抽取
语义类抽取是指从文本中自动抽取信息来构造语义类并建立实体和语义类的关联。图3 列出了一个行之有效的语义类抽取流程,它包含三个模块:并列相似度计算、上下位关系提取以及语义类生成。
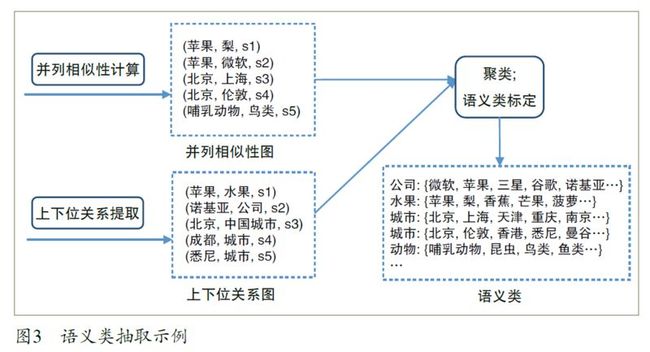
并列相似度计算 其结果是词和词之间的相似性信息,例如图3 中的三元组(苹果,梨,s1)表示苹果和梨的相似度是s1。两个词有较高的并列相似度的条件是它们具有并列关系(即同属于一个语义类),并且有较大的关联度。按照这样的标准,北京和上海具有较高的并列相似度,而北京和汽车的并列相似度很低(因为它们不属于同一个语义类)。对于海淀、朝阳、闵行三个市辖区来说,海淀和朝阳的并列相似度大于海淀和闵行的并列相似度(因为前两者的关联度更高)。
当前主流的并列相似度计算方法有分布相似度法(distributional similarity) 和模式匹配法(pattern Matching)。分布相似度方法基于哈里斯(Harris)的分布假设(distributional hypothesis),即经常出现在类似的上下文环境中的两个词具有语义上的相似性。分布相似度方法的实现分三个步骤:第一步,定义上下文;第二步,把每个词表示成一个特征向量,向量每一维代表一个不同的上下文,向量的值表示本词相对于上下文的权重;第三步,计算两个特征向量之间的相似度,将其作为它们所代表的词之间的相似度。
模式匹配法的基本思路是把一些模式作用于源数据,得到一些词和词之间共同出现的信息,然后把这些信息聚集起来生成单词之间的相似度。模式可以是手工定义的,也可以是根据一些种子数据而自动生成的。
分布相似度法和模式匹配法都可以用来在数以百亿计的句子中或者数以十亿计的网页中抽取词的相似性信息。有关分布相似度法和模式匹配法所生成的相似度信息的质量比较参见文献。
上下位关系提取 该模块从文档中抽取词的上下位关系信息,生成(下义词,上义词)数据对,例如(狗,动物)、(悉尼,城市)。提取上下位关系最简单的方法是解析百科类站点的分类信息(如维基百科的“分类”和百度百科的“开放分类”)。这种方法的主要缺点包括:并不是所有的分类词条都代表上位词,例如百度百科中“狗”的开放分类“养殖”就不是其上位词;生成的关系图中没有权重信息,因此不能区分同一个实体所对应的不同上位词的重要性;覆盖率偏低,即很多上下位关系并没有包含在百科站点的分类信息中。
在英文数据上用Hearst 模式和IsA 模式进行模式匹配被认为是比较有效的上下位关系抽取方法。下面是这些模式的中文版本(其中NPC 表示上位词,NP 表示下位词):
NPC { 包括| 包含| 有} {NP、}* [ 等| 等等]
NPC { 如| 比如| 像| 象} {NP、}*
{NP、}* [{ 以及| 和| 与} NP] 等 NPC
{NP、}* { 以及| 和| 与} { 其它| 其他} NPC
NP 是 { 一个| 一种| 一类} NPC
此外,一些网页表格中包含有上下位关系信息,例如在带有表头的表格中,表头行的文本是其它行的上位词。
语义类生成 该模块包括聚类和语义类标定两个子模块。聚类的结果决定了要生成哪些语义类以及每个语义类包含哪些实体,而语义类标定的任务是给一个语义类附加一个或者多个上位词作为其成员的公共上位词。此模块依赖于并列相似性和上下位关系信息来进行聚类和标定。有些研究工作只根据上下位关系图来生成语义类,但经验表明并列相似性信息对于提高最终生成的语义类的精度和覆盖率都至关重要。
属性和属性值提取
属性提取的任务是为每个语义类构造属性列表(如城市的属性包括面积、人口、所在国家等),而属性值提取则为一个语义类中所包含的实体(如北京)附加属性值(如其面积、人口、所在国家等)。常见的属性和属性值抽取方法包括从百科类站点中提取,从垂直网站中进行包装器归纳,从网页表格中提取,以及利用手工定义或自动生成的模式从句子和查询日志中提取。
常见的语义类/ 实体的常见属性/ 属性值可以通过解析百科类站点中的半结构化信息(如维基百科的信息盒和百度百科的属性表格)而获得。尽管通过这种简单手段能够得到高质量的属性,但同时需要采用其它方法来增加覆盖率(即为语义类增加更多属性以及为更多的实体添加属性值)。
由于垂直网站(如电子产品网站、图书网站、电影网站、音乐网站)包含有大量实体的属性信息,这类站点往往被看作知识抽取的“金矿”。例如图4的网页中包含了电影的导演、编剧、类型、片长等信息。在过去的十几年中,许多研究人员提出了各种各样的方法,以便从垂直站点中生成包装器(或称为模版),并根据包装器来提取属性信息。从包装器生成的自动化程度来看,这些方法可以分为手工法(即手工编写包装器)、监督方法、半监督法以及无监督法。考虑到需要从大量不同的网站中提取信息,并且网站模版可能会更新等因素,无监督包装器归纳方法显得更加重要和现实。无监督包装器归纳的基本思路是利用对同一个网站下面多个网页的超文本标签树的对比来生成模版。简单来看,不同网页的公共部分往往对应于模版或者属性名,不同的部分则可能是属性值,而同一个网页中重复的标签块则预示着重复的记录。
属性抽取的另一个信息源是网页表格,例如图5的表格中包含了中国主要河流的长度、流域面积、流量等属性信息。表格的内容对于人来说一目了然,而对于机器而言,情况则要复杂得多。由于表格类型千差万别,很多表格制作得不规则,加上机器缺乏人所具有的背景知识等原因,从网页表格中提取高质量的属性信息成为挑战。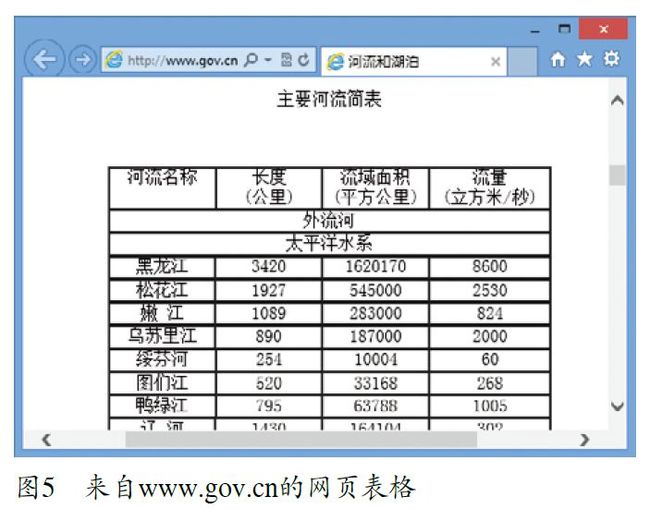
上述三种方法的共同点是通过挖掘原始数据中的半结构化信息来获取属性和属性值。与通过“阅读”句子来进行信息抽取的方法相比,这些方法绕开了自然语言理解这样一个“硬骨头”而试图达到以柔克刚的效果。在现阶段,计算机知识库中的大多数属性值确实是通过上述方法获得的。但现实情况是只有一部分的人类知识是以半结构化形式体现的,而更多的知识则隐藏在自然语言句子中,因此直接从句子中抽取信息成为进一步提高知识库覆盖率的关键。当前从句子和查询日志中提取属性和属性值的基本手段是模式匹配和对自然语言的浅层处理。图6 描绘了为语义类抽取属性名的主框架(同样的过程也适用于为实体抽取属性值)。图中虚线左边的部分是输入,它包括一些手工定义的模式和一个作为种子的(词,属性)列表。模式的例子参见表3,(词,属性)的例子如(北京,面积)。在只有语义类无关的模式作为输入的情况下,整个方法是一个在句子中进行模式匹配而生成(语义类,属性)关系图的无监督的知识提取过程。此过程分两个步骤,第一个步骤通过将输入的模式作用到句子上而生成一些(词,属性)元组,这些数据元组在第二个步骤中根据语义类进行合并而生成(语义类,属性)关系图。在输入中包含种子列表或者语义类相关模式的情况下,整个方法是一个半监督的自举过程,分三个步骤:
1 模式生成:在句子中匹配种子列表中的词和属性从而生成模式。模式通常由词和属性的环境信息而生成。
2 模式匹配。
3 模式评价与选择:通过生成的(语义类,属性)关系图对自动生成的模式的质量进行自动评价并选择高分值的模式作为下一轮匹配的输入。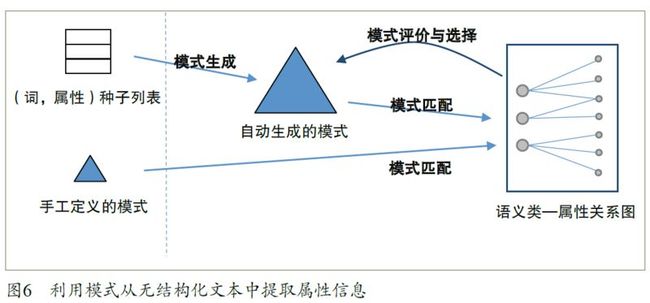

关系提取
关系的基本信息包括参数类型、满足此关系的元组、自然语言表达方式(称为模式)等。例如关系BeCurrencyOf(表示一种货币是一个国家的货币)的基本信息如下:
参数类型:(Business.Currency, Loc.Country)

关系抽取算法可以分为有监督方法、半监督法(或称弱监督法)和无监督法。有监督的关系抽取方法(supervised relation extraction)把关系抽取看作一个分类问题,并根据关系实体在句子中的出现情况提取特征来训练分类器。有监督方法的主要问题是需要大量的训练数据,这使得其很难有效地扩展到支持很多种类型的关系。半监督关系抽取的主要思路是自举法,即对每类关系提供少量模式或实体元组作为种子,然后利用类似图6 的过程得到更多的模式和元组。不同的半监督关系抽取方法遵循类似的流程,但采用不同的模式生成、模式匹配以及模式评价和选择策略,因此会得到不同的抽取效果。在有监督和半监督方法中,一般假定关系的参数类型和一部分元组是已知的。这些方法的输入还可能包含一些模式(作为种子)或者标定好的句子(作为训练数据)。
有监督和半监督的方法只能为已知的手工定义的关系提供新的信息(如新的元组和新的表达方式),而无监督方法则有能力自动发现新的关系。无监督方法的输入是句子或从句子中抽取出来的三元组(对于k 元关系则是k+1 元组),如:
(“{0} 是{1} 的流通货币”,人民币,中国)
(“{0} be legal tender in {1}”, Dinar, Iraq)
(“{0} be the currency of {1}”, Euro, Germany)
(“{0} be the currency of {1}”, Authorship, Science)
同样的模式有可能对应于不同的关系,例如“{0} be the currency of {1}”在最后一个三元组中并不表示{0} 是{1} 的货币。无监督方法一般依赖于某种聚类机制把这些三元组聚集成不同的簇,每一个簇对应一种关系。簇中所包含的每个三元组的第一个元素所构成的集合便是此关系的模式集合,而第二个和第三个元素便构成了此关系的一个元组。
当前在建知识库
部分学术界和工业界的在建知识库见表4。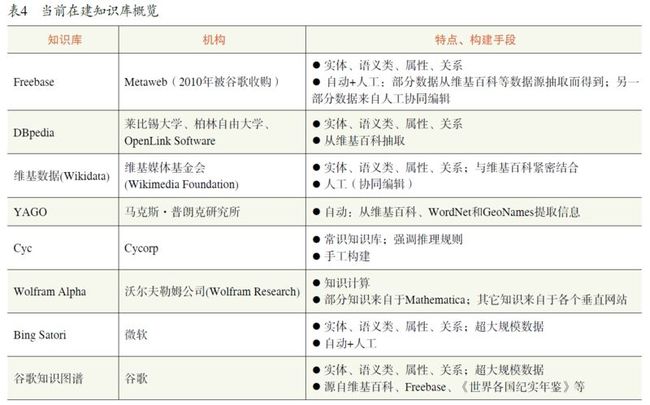
结语
为满足人类信息消费和信息交流的需要而产生的海量互联网电子文档已成为自动知识抽取的重要信息源。与手工编辑和互联网众包这两种机制相比,自动知识抽取的最大优势是良好的可扩展性,即快速构建大规模知识库的能力,但这种可扩展性常常以牺牲精度和某些知识类型上的覆盖率为代价。所以需要很多研究工作来提升抽取的精度和覆盖率(尤其是属性和关系提取的精度和覆盖率),同时需要研究如何将自动抽取、手工编辑与互联网众包相结合而得到高性价比的知识库构建方案。此外,从抽取的知识类型来看,目前的知识类型和知识结构可能尚不足以有效支持自然语言理解等应用。相比于人类的知识结构,计算机知识库中所包含的常识和与动作相关的知识还不足。而且对这两类知识的研究还远未达到令人满意的程度。在将来的研究工作中需要回答的开放性问题包括:
● 需要为现有的知识库增加哪些知识类型?
● 如何存储和表示这些知识类型?
● 如何设计高精度、高覆盖率的算法来提取这些类
型的知识?
● 如何表示常识和与动作有关的知识?
● 如何自动提取常识和与动作有关的知识?
● 需要对知识库做哪些改进来支持推理和计算?
上述开放性问题的存在和知识库对于上层应用的支持现状决定了目前知识提取和知识库构建尚处在初级阶段,期待更多的研究人员在此领域取得突破性进展。
申明:《知识库构建前沿:自动和半自动知识提取》(原名《自动和半自动知识提取》)一文在微软研究院博客上转载经由《中国计算机学会通讯》同意,版权归《中国计算机学会通讯》所有。原文刊登于《中国计算机学会通讯》2013年8月第90期
作者介绍
史树明
微软亚洲研究院主管研究员。
主要研究方向为知识挖掘和语义计算。
参考文献
[1] 罗杰·瑞迪(Raj Reddy). 图灵未竟的事业(常虹整理).中国计算机学会通讯, 第9卷第1期, 2013年1月
[2] ACE, http://www.itl.nist.gov/iad/mig/tests/ace/
[3] E. Agichtein and L. Gravano, Snowball: extracting relations from large plain-text collections, In Proc. 5th ACM International Conference on Digital Libraries (ACM DL), 2000
[4] A. Arasu, and H. Garcia-Molina. Extracting structured data from Web pages. Proceedings of the ACM SIGMOD International Conference on Management of Data, San Diego, California, 2003, 337~348
[5] D.M. Bikel, S. Miller, R. Schwartz, R. Weischedel. Nymble: a high-performance learning name-finder. In Proc. Conference on Applied Natural Language Processing. 1997
____________________________________________________________________________________
相关阅读