编者按:图谱搜索(Graph Search)是基于社交图谱构建起来的搜索服务,与基于关键词匹配的传统网络搜索引擎相比,图谱搜索能够支持更自然、复杂的查询输入,并针对查询直接给出答案。在微软亚洲研究院副研究员段楠眼中,这样的高效个性化搜索会越来越多。文章中,他从基础架构、自然语言接口、相关研究、发展趋势等几个方面,对计算搜索的现在和未来进行了总结和展望。
作者微软亚洲研究院 段楠
脸谱(Facebook) 于2013 年1 月15 日推出了图谱搜索(graph search) 测试版[1],该功能可以看作是基于社交图谱(social graph) 的语义搜索[2] 服务。登录用户在使用脸谱搜索框时,能在下拉菜单中使用好友、照片、地点和兴趣等新的搜索选项。例如,当用户输入“Restaurants liked by my friends”(我朋友们喜欢的餐馆)时,图谱搜索将呈现用户的全部脸谱好友所推荐的餐厅列表。与基于关键词匹配的传统网络搜索引擎相比,图谱搜索能够支持更自然、复杂的查询输入,并针对查询直接给出答案。与搜索引擎关键词自动补足功能类似,图谱搜索会在用户输入时同步预测用户搜索意图,并根据用户选择进行查询扩展。例如,在用户输入“My friends who”后,图谱搜索会询问用户是否希望继续搜索“My friends who live in Beijing”或“My friends who work at Microsoft”等。对此,脸谱的凯斯·佩里斯(Keith Peiris) 表示:“我们希望用户能忘记以往使用搜索引擎的方式,即输入若干模糊的关键词;相反,他们可以准确表达希望获得什么。”此外,图谱搜索还具备个性化的特点,即针对用户提出的查询,图谱搜索仅仅在与用户直接相关的事物中进行搜索并给出答案。这样做既能解决潜在的隐私问题,又能为用户提供与其自身社交网络密切相关的信息。
目前,图谱搜索还处于测试阶段,仅支持英文查询,搜索内容也仅限于好友、照片、地点和兴趣等相对简单的数据源。当图谱搜索无法提供任何返回结果时,微软公司的必应搜索引擎就使用常规搜索结果填补空白。
社交图谱
图谱搜索是基于社交图谱构建起来的搜索服务。社交图谱由脸谱数据中的实体以及实体与实体之间的关系构成。其中,实体是节点,关系是边。脸谱中的用户、页面、地点、照片、网帖等信息均可由节点表示,实体之间的关系(例如朋友关系、雇佣关系等)则由边表示。从语言学的角度来描述,实体可以类比为名词短语,而边可以类比为动词短语[8]。根据2013 年1 月的统计,社交图谱包含约10 亿个用户、1500 亿条朋友链接、2400 亿张照片(照片以每天3.5 亿张的数量增加)以及27 亿条推荐信息。由此可见,社交图谱的数据量巨大。
基础架构
倒排索引系统Unicorn 是图谱搜索的核心。它基于倒排索引框架,提供从建立索引到从索引数据中查询结果的功能,每一个Unicorn 实例被称为一个vertical。由于索引数据的大小通常远超一台计算机的内存容量上限,因此vertical 会将索引数据分别部署在多个索引服务器上。当一次新的查询触发时,Unicorn 首先会将查询语句传递给vertical 聚合器(aggregator),并由此模块将该查询进一步分发至不同的索引服务器;然后,每台索引服务器根据接收到的查询进行检索,并将检索结果返回至聚合器;最后,聚合器负责对全部索引服务器的返回结果进行整合,并将最终整合结果返回。由于脸谱对不同类型实体的排序有不同的需求,图谱搜索会针对每类实体分别创建一个vertical。在所有vertical 的上层,一个名为顶级聚合器的模块负责对用户查询进行改写,并对改写后的查询按照类型进行切分,然后将切分结果分发至不同vertical 进行检索。在接收到全部vertical 的返回结果后,顶级聚合器还要负责对结果进行打分及合并操作。图1 是Unicorn 的工作流程图[3]。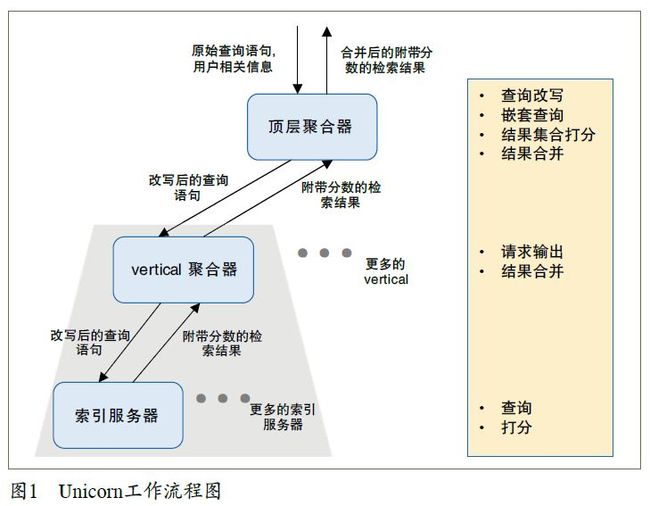
针对图谱搜索的特定需求,脸谱对Unicorn 进行了若干功能扩展,主要包括:
强化“or”操作,弱化“and”操作 在很多情况下,查询操作往往需要通过弱化“and”操作来避免因约束条件过强而造成的查询结果丢失,而需要强化“or”操作来获取更多的结果。
查询改写 由于用户输入的查询语句并不是Unicorn 标准查询语言,因此需要在对用户意图及其社交图谱上下文充分理解的基础上,将其转化为结构化的查询语言。
打分 默认情况下,Unicorn 按照返回实体的静态排名对搜索结果进行打分。图谱搜索对这一打分机制进行了扩展,更多地考虑了查询语句与实体之间的相关性信息。
向前索引 Unicorn 为每个实体保留与其相关的若干信息,用于辅助对查询结果的打分和排序。
合并 对不同vertical 返回的检索结果,顶级聚合器首先对结果打分进行归一化处理,然后将全部结果重新排序,并据此生成一组统一的结果集合。
嵌套查询 对于某些查询语句,需要进行多次检索并将检索结果合并才能得到最终结果。例如:对于查询“Restaurants liked by Facebook employees”,图谱搜索需要首先获得“Facebook employees”对应的中间结果“[internal results]”,然后再通过搜索“Restaurants liked by [internal results]”来获得最终结果。Unicorn 提供了对此类嵌套查询语句进行分解、多步搜索和结果合并的功能。
自然语言接口
社交图谱是以结构化方式存储的数据,而用户查询往往使用自然语言。因此,如何将自然语言查询转化为机器能够理解的结构化查询便成为图谱搜索的核心任务和挑战。图谱搜索的自然语言接口[4] 用于完成上述转化任务,其主要包括3 个模块:
实体识别和实体消歧 图谱搜索目前将实体划分成20 多个类别,包括用户、组别、应用、城市、大学等。给定输入查询语句,实体识别模块会对其进行切分,并基于n 元语言模型对查询片段标注类别及其对应的概率信息。实体消歧模块将具有较高可信度的实体候选发送给Typeahead,Typeahead 会根据实体静态排名以及查询上下文、用户社交和地理位置等返回与实体候选相对应的实体列表。
词汇分析 在自然语言中,相同含义的语句往往对应多种不同的表述方式。针对此问题,词汇分析模块能通过使用同义词表、相关词表、时态变换等相关资源和信息,对各种不同的表达方式进行“规范”。
语义解析 语义解析模块将自然语言输入查询转化为最有可能的N 条结构化查询语句。图2 描述了图谱搜索如何将自然语言查询转化为结构化查询。给定输入查询“Friends in San Francisco”,图谱搜索使用加权的上下文无关文法(weighted context free grammar, WCFG) 对其进行语义分析。该查询对应一个树形结构,该结构中每个非叶子节点都由3 部分信息构成:蓝色部分代表该节点对应的非终结符部分,黑色部分代表该节点对应的(规范化后的)自然语言查询语句,红色部分代表该节点对应的结构化查询语句。原始查询语句在经过自然语言接口模块处理后,对应的规范化自然语言查询语句和结构化查询语句分别为:“my friends who live in [id:12345]”和“intersect(friends(me),residents(12345))”。其中,“12345”代表“San Francisco”在社交图谱上对应的ID。在将结构化查询语句进一步转化为Unicorn 查询语言后,图谱搜索就可以在索引数据上执行搜索并获取最终结果了。

相关研究
图谱搜索与基于知识库的自动问答(knowledge base - question answering, KB-QA) 系统有很多相似之处:输入的都是自然语言;数据都以结构化的形式管理和存储;需要对输入查询(或问题)进行语义解析,将其转化为机器能够理解的结构化语言;从结构化的数据库中检索结果。KB-QA 系统的任务在于使用结构化的知识库对自然语言问题进行自动回答。在知识库方面,知识以三元组(< 主语,谓词/ 关系,宾语>)的形式进行存储和管理。其中,主语和宾语分别对应两个知识库实体,谓词/ 关系对应两个知识库实体间所存在的关系。例如,对应了知识库中的一个三元组,其含义为:实体“Bill Gates”和实体“Microsoft”之间存在“IsFounderOf”的关系。知识库中的每个实体都对应唯一的ID 标识,用于对具有相同名字的不同实体进行消歧。在自动问答方面,给定自然语言问题,例如,“the company founded by Bill Gates”,KB-QA 系统首先将自然语言问题转化为结构化查询语句“”,其中,自然语言的表述“the company founded by”被转化为抽象的知识库谓词/关系“IsFounderOf”。通过查找知识库,能够找到答案占位符“?”对应的实体“Microsoft”。由于用户描述问题的方式变化多样,问题复杂程度各有不同,自动问答系统同样需要引入诸如实体识别和消歧、结构化查询语句转化、推理、句法和语义分析等模块。可见,在技术层面上,图谱搜索和自动问答是极其相关的。
发展趋势
除脸谱外,信息技术领域的其他巨头也先后推出了类似的基于结构化数据的搜索产品或服务,作为其进军和探索下一代搜索引擎技术的桥头堡和试验田。
Watson 是由IBM 公司研发的自动问答系统 [6]。在对输入问题计算答案的过程中,基于知识库的问答模块起到了显著作用。实验表明,虽然该模块能够回答的问题数目占全部问题数目的比例并不大,但回答问题的准确度却远高于其他问答模块。可以预见,随着知识库的不断更新,以及对自然语言理解技术的研究深入,基于知识库的问答模块必定会在自动问答系统中起到越来越重要的作用。目前,Watson 已应用于医疗、金融等多个领域。
谷歌提出了知识图谱[5] 的概念,并推出了基于知识图谱的新型搜索服务。知识图谱从本质上讲是一个知识库,基于知识图谱的搜索服务则可以看作是一个典型的自动问答系统。与传统网页搜索相比,基于知识图谱的搜索能够更好地理解用户的搜索意图,并对相关内容和主题进行总结。例如,当输入“Bill Gates”时,用户不仅可以获得这个关键词的全部信息,还能获取关于Bill Gates 的介绍。知识图谱还能够提供搜索结果的详细知识体系,帮助用户从更多角度了解搜索结果的相关信息。
微软公司通过提取网页中的非结构化数据,构建了结构化的知识库Satori[7],用于从语义层面提高和改进必应的搜索质量。此外,与谷歌的知识图谱搜索类似,当用户输入的查询语句能够被后台自然语言处理模块解析时,必应将触发自动问答模块,基于Satori 知识库生成答案,并将生成的结果及其相关知识直接返回给用户。
互联网上知识的指数级增长使得人们已经不满足于传统搜索服务的模式,即仅仅返回与用户查询相关的若干文档链接,用户更渴望获得针对其所提出问题的准确回答。随着结构化数据库的规模扩大、自然语言理解技术的深化,针对查询进行精确理解和回答的搜索服务必将越来越实用化。基于结构化数据(知识库)和语义理解的搜索技术在一定程度上代表了搜索引擎技术的发展趋势,所具有的特点能够更好地满足用户对搜索服务新的需求:
能够对自然语言查询进行深入的理解,并从语义层面解析用户查询意图;
能够利用海量的结构化知识库,针对用户查询提供准确的答案。
充分利用结构化大数据,深入理解用户自然语言查询并针对查询给出准确的答案,能够更好地满足人类对知识获取的需求,同时也代表了计算和搜索的未来。
申明:《从图谱搜索看搜索技术的发展趋势》一文在微软研究院博客上转载经由《中国计算机学会通讯》同意,版权归《中国计算机学会通讯》所有。原文刊登于《中国计算机学会通讯》2013年8月第90期
作者介绍
段 楠
微软亚洲研究院副研究员。
主要研究方向为自然语言理解、自动问答和机器翻译。
参考文献
[1] http://www.facebook.com/about/graphsearch
[2] Berners-Lee Tim. The semantic Web. Scientific American.2001
[3] Sriram Sankar. Under the hood: indexing and ranking in graph search. 2013,https://www.facebook.com/notes/facebook-engineering/under-the-hood-indexing-andranking-in-graph-search/10151361720763920
[4] Li Xiao and Maxime Boucher. Under the hood: the natural language interface of graph search. 2013, https://www.facebook.com/notes/facebook-engineering/underthe-hood-the-natural-languageinterface-of-graphsearch/10151432733048920
[5] Sullivan, Danny. Google launches knowledge graph to provide answers, not just links, 2012.http://searchengineland.com/google-launches-knowledge-graph-121585
[6] David Ferrucci, Eric Brown, Jennifer Chu-Carroll, James Fan,David Gondek, Aditya A. Kalyanpur, Adam Lally, J. William Murdock, Eric Nyberg, John Prager, Nico Schlaefer, and Chris Welty. Building Watson: an overview of the DeepQA project. 2010
[7] Gallagher, Sean. How Google and Microsoft taught searchto understand the Web. 2012
[8] Sriram Sankar, Soren Lassen, and Mike Curtiss. Under the hood: building out the infrastructure for graph search. 2013
[9] Lars Eilstrup Rasmussen. Under the hood: building graph search beta. 2013