Oracle分析函数简述
基本上所有的分析函数均是这种格式:
函数名称 ([参数]) OVER (analytic_clause)
analytic_clause包含:[partition 子句][ order 子句 [window子句]]
● Partition 子句:Partition by exp1[ ,exp2]...
Partition没啥说的,功能强大参数少,主要用于分组,可以理解成select中的group by。不过它跟select语句后跟的group by 子句并不冲突。
● Order子句:Order by exp1[asc|desc] [ ,exp2 [asc|desc]]... [nulls first|last]。部分函数支持window子句。
Order by的参数基本与select中的order by相同。大家按那个理解就是了。Nulls first|last是用来限定nulls在分组序列中的所在位置的,我们知道oracle中对于null的定义是未知,所以默认ordery的时候nulls总会被排在最前面。如果想控制值为null的列的话呢,nulls first|last参数就能派上用场了。
● Window子句:En,贴个图吧
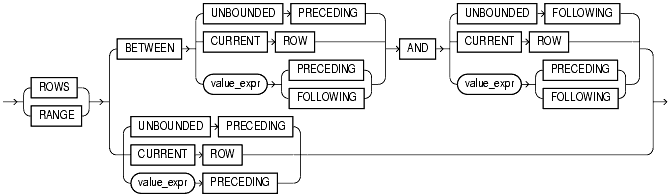
看起来复杂其实简单,而且应用的机率相当的低,不详细介绍了。
● AVG( [ DISTINCT | ALL] expr) OVER(analytic_clause) 计算平均值。
例如:
● SUM ( [ DISTINCT | ALL ] expr ) OVER ( analytic_clause )
例如:见上例。
● COUNT({* | [DISTINCT | ALL] expr}) OVER (analytic_clause) 查询分组序列中各组行数。
例如:
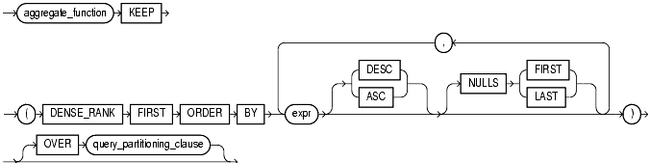
● FIRST() 从DENSE_RANK返回的集合中取出排在第一的行。
例如:
可以看到二者结果基本相似,但是ex1的结果是group by后的列,而ex2则是每一行都有返回。
● LAST()与上同,不详述。
例如:见上例。
● FIRST_VALUE (col) OVER ( analytic_clause ) 返回over()条件查询出的第一条记录
例如:
● LAST_VALUE (col) OVER ( analytic_clause ) 返回over()条件查询出的最后一条记录
例如:见上例。
● LAG(col[,n][,n]) over([partition_clause] order_by_clause) lag是一个相当有意思的函数,其功能是返回指定列col前n1行的值(如果前n1行已经超出比照范围,则返回n2,如不指定n2则默认返回null),如不指定n1,其默认值为1。
例如:
● LEAD(col[,n][,n]) over([partition_clause] order_by_clause) 与上函数正好相反,本函数返回指定列col后n1行的值。
例如:见上例
● MAX (col) OVER (analytic_clause) 获取分组序列中的最大值。
例如:
● MIN (col) OVER (analytic_clause) 获取分组序列中的最小值。
例如:见上例。
● RANK() OVER([partition_clause] order_by_clause) 关于RANK和DENSE_RANK前面聚合函数处介绍过了,这里不废话不,大概直接看示例吧。
例如:
● DENSE_RANK () OVER([partition_clause] order_by_clause)
例如:见上例。
● ROW_NUMBER () OVER([partition_clause] order_by_clause) 这个函数需要多说两句,通过上述的对比相信大家应该已经能够看出些端倪。前面讲过,dense_rank在做排序时如果遇到列有重复值,则重复值所在行的序列值相同,而其后的序列值依旧递增,rank则是重复值所在行的序列值相同,但其后的序列值从+重复行数开始递增,而row_number则不管是否有重复行,(分组内)序列值始终递增
例如:见上例。
● CUME_DIST() OVER([partition_clause] order_by_clause) 返回该行在分组序列中的相对位置,返回值介于0到1之间。注意哟,如果order by的列是desc,则该分组内最大的行返回列值1,如果order by为asc,则该分组内最小的行返回列值1。
例如:
● NTILE(n) OVER([partition_clause] order_by_clause)
ntile是个很有意思的统计函数。它会按照你指定的组数(n)对记录做分组
例如:
● PERCENT_RANK() OVER([partition_clause] order_by_clause) 与CUME_DIST类似,本函数返回分组序列中各行在分组序列的相对位置。其返回值也是介于0到1之间,不过其起始值始终为0而终结值始终为1。
例如:
● PERCENTILE_CONT(n) WITHIN GROUP (ORDER BY col [DESC|ASC]) OVER(partition_clause)
本函数功能与前面聚合函数处介绍的完全相同,只是一个是聚合函数,一个是分析函数。
例如:
● PERCENTILE_DISC(n) WITHIN GROUP (ORDER BY col [DESC|ASC]) OVER(partition_clause)
本函数功能与前面聚合函数处介绍的完全相同,只是一个是聚合函数,一个是分析函数。
例如:
● RATIO_TO_REPORT(col) over ([partition_clause]) 本函数计算本行col列值在该分组序列sum(col)中所占比率。如果col列为空,则返回空值。
例如:
● STDDEV ([distinct|all] col) OVER (analytic_clause) 返回列的标准偏差。
例如:
● STDDEV_SAMP(col) OVER (analytic_clause) 功能与上相同,与STDDEV不同地方在于如果该分组序列只有一行的话,则STDDEV_SAMP函数返回空值,而STDDEV则返回0。
例如:
● STDDEV_POP(col) OVER (analytic_clause) 返回该分组序列总体标准偏差
例如:
● VAR_POP(col) OVER (analytic_clause) 返回分组序列的总体方差,VAR_POP进行如下计算:(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / COUNT(expr)
例如:
● VAR_SAMP(col) OVER (analytic_clause) 与上类似,该函数返回分组序列的样本方差,,其计算公式为:(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / (COUNT(expr) - 1)
例如:
● VARIANCE(col) OVER (analytic_clause) 该函数返回分组序列方差,Oracle计算该变量如下:
如果表达式中行数为1,则返回0,如果表达式中行数大于1,则返回VAR_SAMP
例如:
函数名称 ([参数]) OVER (analytic_clause)
analytic_clause包含:[partition 子句][ order 子句 [window子句]]
● Partition 子句:Partition by exp1[ ,exp2]...
Partition没啥说的,功能强大参数少,主要用于分组,可以理解成select中的group by。不过它跟select语句后跟的group by 子句并不冲突。
● Order子句:Order by exp1[asc|desc] [ ,exp2 [asc|desc]]... [nulls first|last]。部分函数支持window子句。
Order by的参数基本与select中的order by相同。大家按那个理解就是了。Nulls first|last是用来限定nulls在分组序列中的所在位置的,我们知道oracle中对于null的定义是未知,所以默认ordery的时候nulls总会被排在最前面。如果想控制值为null的列的话呢,nulls first|last参数就能派上用场了。
● Window子句:En,贴个图吧
看起来复杂其实简单,而且应用的机率相当的低,不详细介绍了。
● AVG( [ DISTINCT | ALL] expr) OVER(analytic_clause) 计算平均值。
例如:
--聚合函数 SELECT col, AVG(value) FROM tmp1 GROUP BY col ORDER BY col; --分析函数 SELECT col, AVG(value) OVER(PARTITION BY col ORDER BY col) FROM tmp1 ORDER BY col;
● SUM ( [ DISTINCT | ALL ] expr ) OVER ( analytic_clause )
例如:见上例。
● COUNT({* | [DISTINCT | ALL] expr}) OVER (analytic_clause) 查询分组序列中各组行数。
例如:
--分组查询col的数量 SELECT col,count(0) over(partition by col order by col) ct FROM tmp1;
● FIRST() 从DENSE_RANK返回的集合中取出排在第一的行。
例如:
--聚合函数 SELECT col, MIN(value) KEEP(DENSE_RANK FIRST ORDER BY col) "Min Value", MAX(value) KEEP(DENSE_RANK LAST ORDER BY col) "Max Value" FROM tmp1 GROUP BY col; --分析函数 SELECT col, MIN(value) KEEP(DENSE_RANK FIRST ORDER BY col) OVER(PARTITION BY col), MAX(value) KEEP(DENSE_RANK LAST ORDER BY col) OVER(PARTITION BY col) FROM tmp1 ORDER BY col;
可以看到二者结果基本相似,但是ex1的结果是group by后的列,而ex2则是每一行都有返回。
● LAST()与上同,不详述。
例如:见上例。
● FIRST_VALUE (col) OVER ( analytic_clause ) 返回over()条件查询出的第一条记录
例如:
insert into tmp1 values ('test6','287');
SELECT col,
FIRST_VALUE(value) over(partition by col order by value) "First",
LAST_VALUE(value) over(partition by col order by value) "Last"
FROM tmp1;
● LAST_VALUE (col) OVER ( analytic_clause ) 返回over()条件查询出的最后一条记录
例如:见上例。
● LAG(col[,n][,n]) over([partition_clause] order_by_clause) lag是一个相当有意思的函数,其功能是返回指定列col前n1行的值(如果前n1行已经超出比照范围,则返回n2,如不指定n2则默认返回null),如不指定n1,其默认值为1。
例如:
SELECT col, value, LAG(value) over(order by value) "Lag", LEAD(value) over(order by value) "Lead" FROM tmp1;
● LEAD(col[,n][,n]) over([partition_clause] order_by_clause) 与上函数正好相反,本函数返回指定列col后n1行的值。
例如:见上例
● MAX (col) OVER (analytic_clause) 获取分组序列中的最大值。
例如:
--聚合函数 SELECT col, Max(value) "Max", Min(value) "Min" FROM tmp1 GROUP BY col; --分析函数 SELECT col, value, Max(value) over(partition by col order by value) "Max", Min(value) over(partition by col order by value) "Min" FROM tmp1;
● MIN (col) OVER (analytic_clause) 获取分组序列中的最小值。
例如:见上例。
● RANK() OVER([partition_clause] order_by_clause) 关于RANK和DENSE_RANK前面聚合函数处介绍过了,这里不废话不,大概直接看示例吧。
例如:
insert into tmp1 values ('test2',120);
SELECT col,
value,
RANK() OVER(order by value) "RANK",
DENSE_RANK() OVER(order by value) "DENSE_RANK",
ROW_NUMBER() OVER(order by value) "ROW_NUMBER"
FROM tmp1;
● DENSE_RANK () OVER([partition_clause] order_by_clause)
例如:见上例。
● ROW_NUMBER () OVER([partition_clause] order_by_clause) 这个函数需要多说两句,通过上述的对比相信大家应该已经能够看出些端倪。前面讲过,dense_rank在做排序时如果遇到列有重复值,则重复值所在行的序列值相同,而其后的序列值依旧递增,rank则是重复值所在行的序列值相同,但其后的序列值从+重复行数开始递增,而row_number则不管是否有重复行,(分组内)序列值始终递增
例如:见上例。
● CUME_DIST() OVER([partition_clause] order_by_clause) 返回该行在分组序列中的相对位置,返回值介于0到1之间。注意哟,如果order by的列是desc,则该分组内最大的行返回列值1,如果order by为asc,则该分组内最小的行返回列值1。
例如:
SELECT col, value, CUME_DIST() OVER(ORDER BY value DESC) FROM tmp1;
● NTILE(n) OVER([partition_clause] order_by_clause)
ntile是个很有意思的统计函数。它会按照你指定的组数(n)对记录做分组
例如:
SELECT t.*,ntile(5) over(order by value desc) FROM tmp1 t;
● PERCENT_RANK() OVER([partition_clause] order_by_clause) 与CUME_DIST类似,本函数返回分组序列中各行在分组序列的相对位置。其返回值也是介于0到1之间,不过其起始值始终为0而终结值始终为1。
例如:
SELECT col, value, PERCENT_RANK() OVER(ORDER BY value) FROM tmp1;
● PERCENTILE_CONT(n) WITHIN GROUP (ORDER BY col [DESC|ASC]) OVER(partition_clause)
本函数功能与前面聚合函数处介绍的完全相同,只是一个是聚合函数,一个是分析函数。
例如:
--聚合函数 SELECT col, max(value), min(value), sum(value), PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY value) a, PERCENTILE_CONT(0.8) WITHIN GROUP(ORDER BY value) b FROM TMP1 group by col; --分析函数 SELECT col, value, sum(value) over(partition by col) "Sum", PERCENTILE_CONT(0.5) WITHIN GROUP( ORDER BY value) OVER(PARTITION BY col) "CONTa", PERCENTILE_CONT(0.8) WITHIN GROUP( ORDER BY value) OVER(PARTITION BY col) "CONTb" FROM TMP1;
● PERCENTILE_DISC(n) WITHIN GROUP (ORDER BY col [DESC|ASC]) OVER(partition_clause)
本函数功能与前面聚合函数处介绍的完全相同,只是一个是聚合函数,一个是分析函数。
例如:
--聚合函数 SELECT col, max(value), min(value), sum(value), PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY value) a, PERCENTILE_DISC(0.8) WITHIN GROUP(ORDER BY value) b FROM TMP1 group by col; --分析函数 SELECT col, value, sum(value) over(partition by col) "Sum", PERCENTILE_DISC(0.5) WITHIN GROUP( ORDER BY value) OVER(PARTITION BY col) "CONTa", PERCENTILE_DISC(0.8) WITHIN GROUP( ORDER BY value) OVER(PARTITION BY col) "CONTb" FROM TMP1;
● RATIO_TO_REPORT(col) over ([partition_clause]) 本函数计算本行col列值在该分组序列sum(col)中所占比率。如果col列为空,则返回空值。
例如:
SELECT col, value, RATIO_TO_REPORT(value) OVER(PARTITION BY col) "RATIO_TO_REPORT" FROM TMP1
● STDDEV ([distinct|all] col) OVER (analytic_clause) 返回列的标准偏差。
例如:
--聚合函数 SELECT col, STDDEV(value) FROM TMP1 GROUP BY col; --分析函数 SELECT col, value, STDDEV(value) OVER(PARTITION BY col ORDER BY value) "STDDEV" FROM TMP1;
● STDDEV_SAMP(col) OVER (analytic_clause) 功能与上相同,与STDDEV不同地方在于如果该分组序列只有一行的话,则STDDEV_SAMP函数返回空值,而STDDEV则返回0。
例如:
--聚合函数 SELECT col, STDDEV(value),STDDEV_SAMP(value) FROM TMP1 GROUP BY col; --分析函数 SELECT col, value, STDDEV(value) OVER(PARTITION BY col ORDER BY value) "STDDEV", STDDEV_SAMP(value) OVER(PARTITION BY col ORDER BY value) "STDDEV_SAMP" FROM TMP1;
● STDDEV_POP(col) OVER (analytic_clause) 返回该分组序列总体标准偏差
例如:
--聚合函数 SELECT col, STDDEV_POP(value) FROM TMP1 GROUP BY col; --分析函数 SELECT col, value, STDDEV_POP(value) OVER(PARTITION BY col ORDER BY value) "STDDEV_POP" FROM TMP1;
● VAR_POP(col) OVER (analytic_clause) 返回分组序列的总体方差,VAR_POP进行如下计算:(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / COUNT(expr)
例如:
--聚合函数 SELECT col, VAR_POP(value) FROM TMP1 GROUP BY col; --分析函数 SELECT col, value, VAR_POP(value) OVER(PARTITION BY col ORDER BY value) "VAR_POP" FROM TMP1;
● VAR_SAMP(col) OVER (analytic_clause) 与上类似,该函数返回分组序列的样本方差,,其计算公式为:(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / (COUNT(expr) - 1)
例如:
--聚合函数 SELECT col, VAR_SAMP(value) FROM TMP1 GROUP BY col; --分析函数 SELECT col, value, VAR_SAMP(value) OVER(PARTITION BY col ORDER BY value) "VAR_SAMP" FROM TMP1;
● VARIANCE(col) OVER (analytic_clause) 该函数返回分组序列方差,Oracle计算该变量如下:
如果表达式中行数为1,则返回0,如果表达式中行数大于1,则返回VAR_SAMP
例如:
--聚合函数 SELECT col, VAR_SAMP(value),VARIANCE(value) FROM TMP1 GROUP BY col; --分析函数 SELECT col, value, VAR_SAMP(value) OVER(PARTITION BY col ORDER BY value) "VAR_SAMP", VARIANCE(value) OVER(PARTITION BY col ORDER BY value) "VARIANCE" FROM TMP1;