廉颇老矣,尚可饭否?然也!
Mongodb的研究总是断断续续,需要持续经营,将其积累,为日后的工作提供参考。
年底了,把今年用到的东西做个收敛。把这个年初就写了点的东西再好好收拾收拾。
今天尝试一把复制集群ReplicateSet模式,做个小总结,后续在这个帖子上不断填充。
集群配置相关链接:
征服 Mongodb 之 安装与系统服务配置
征服 Mongodb 之 主从复制&集群复制
基本操作相关链接:
征服 Mongodb 之 常用命令、基本数据类型
征服 Mongodb 之 Modifier初识
征服 Mongodb 之 Modifier增强
征服 Mongodb 之 CRUD
一、主从复制
一般数据库都会用到这种最通用的模式——主从模式。这种方式简单灵活,可用于备份、故障恢复,读扩展。为了平衡负载,一般通过读写分离模式,即主库写、从库读。
假设我们有两台MongoDB服务器,10.11.20.140和10.11.20.139。如果要配置主从复制,可参考如下实现:
Master(10.11.20.140):
port = 27017 dbpath = /data/db logpath = /var/log/mongodb.log logappend = true journal = true pidfile = /var/run/mongodb.pid fork = true master = true
注意:
master=true
Slave(10.11.20.139):
port=27017 dbpath = /data/db logpath = /var/log/mongodb.log logappend = true journal = true fork = true slave = true source = 10.11.20.140:27017
注意:
slave=true
source=10.11.20.140:27017
上述配置,即可完成Master-Slave
简单测试下,在Master(10.11.20.140)上写数据,在Slave(10.11.20.139)上读出。
Master写入:
MongoDB shell version: 2.0.7
connecting to: 10.11.20.140:27017/test
> db.test.save( { a: 1 } )
Slave 读出:
MongoDB shell version: 2.0.7
connecting to: 10.11.20.139:27017/test
> db.test.find()
{ "_id" : ObjectId("502cccaf2d44738c3b181391"), "a" : 1 }
>
完成主从同步!
注意:如果这是配置了“auth = false”,主从同步可能失败。
二、集群复制
主从复制虽然可以承受一定的负载压力,但这种方式仍然是一个单点,如果主库挂了,数据写入就成了风险。如果,当主库挂掉的时候,可以在访问ip不变的前提下,自动将从库作为主库使用,是不是就能避免这种风险?貌似这又涉及到Linux上的服务KeepAlive等等。
在Mongodb中,提供了一种优于主从模式的集群复制(ReplicateSet)。最理想的模式是,节点之间不分特定的主从。任何一个节点都可以是主节点primary,而其他节点都是secondary,甚至可以通过投票方式选出主节点。
一般的集群复制,可以是如下这个结构: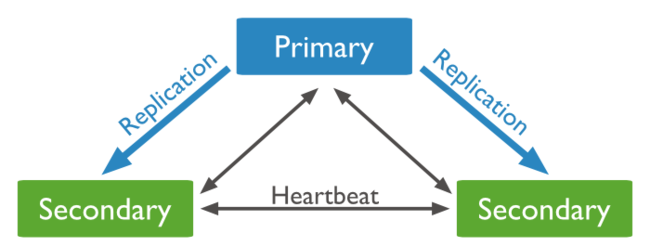
假设我们拥有3台Mongodb,192.168.158.130、192.168.158.131和192.168.158.132。我们希望这3台Mongodb能够构建ReplicateSet模式,可以依照如下操作实现:
1. 配置副本集
假设我们这里的副本集定为snowolf,需要在mongodb配置文件中进行如下配置:
replSet = snowolf
然后,我们启动这两台Mongodb,查看状态。
$ mongo 192.168.158.130
MongoDB shell version: 2.0.4
connecting to: 192.168.158.130/test
> rs.status()
{
"startupStatus" : 3,
"info" : "run rs.initiate(...) if not yet done for the set",
"errmsg" : "can't get local.system.replset config from self or any seed (EMPTYCONFIG)",
"ok" : 0
}
>
这时候,复制集群还没有达到可用,需要进一步配置。
2. 配置成员
这里可以在任一节点进行,通过rs.initiate(cfg)完成配置。
先配置一个中间变量:
> cfg={_id:'snowolf',members:[
... {_id:0,host:'192.168.158.130:27017'},
... {_id:1,host:'192.168.158.131:27017'}]
... }
{
"_id" : "snowolf",
"members" : [
{
"_id" : 0,
"host" : "192.168.158.130:27017"
},
{
"_id" : 1,
"host" : "192.168.158.131:27017"
}
]
}
接下来,需要让配置生效:
> rs.initiate(cfg)
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}
如果如上所示,说明配置成功。
这时候,再看看当前的状态:
> rs.status()
{
"set" : "snowolf",
"date" : ISODate("2013-11-14T08:33:58Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "192.168.158.130:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"optime" : {
"t" : 1384417894000,
"i" : 1
},
"optimeDate" : ISODate("2013-11-14T08:31:34Z"),
"self" : true
},
{
"_id" : 1,
"name" : "192.168.158.131:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 137,
"optime" : {
"t" : 1384417894000,
"i" : 1
},
"optimeDate" : ISODate("2013-11-14T08:31:34Z"),
"lastHeartbeat" : ISODate("2013-11-14T08:33:57Z"),
"pingMs" : 348
}
],
"ok" : 1
}
我们在一开始,并没有强制设定哪个IP是primary节点,哪个是secondary节点。这完全由Mongodb集群来决定。
这时在命令行下,提示符也发生了变化。
Primary节点:
PRIMARY>
Secondary节点:
SECONDARY>
别急,这时候还没有大功告成,如果直接在secondary上操作,会发生如下错误:
SECONDARY> db.t.find()
error: { "$err" : "not master and slaveok=false", "code" : 13435 }
需要告知Mongodb集群,从哪台机器上进行读操作:
SECONDARY> rs.slaveOk() not master and slaveok=false
这时就不会有刚才的错误了。
测试:
在primary节点写入操作:
PRIMARY> db.t.insert({uid:12345})
PRIMARY> db.t.find()
{ "_id" : ObjectId("52848f782c6dd18b00fdf65d"), "uid" : 12345 }
在secondary节点读操作:
SECONDARY> db.t.find()
{ "_id" : ObjectId("52848f782c6dd18b00fdf65d"), "uid" : 12345 }
似乎大功告成,如果这时候我们把primary节点停掉,在secondary节点执行写操作,就会发生如下错误提示:
SECONDARY> db.t.insert({uid:12345})
not master
如果只有2台Mongodb,配置复制集群还不够安全,需要1个外在角色调整各个节点的角色。
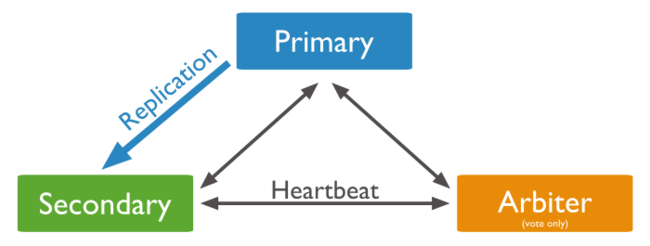
这些节点包括:
- statndard 常规节点,存储一份完整的数据副本,参与投票,可以成为活跃节点,即primary节点
- passive 只做存储,参与投票
- arbiter 仲裁者只投票,不复制数据,也不能成为活跃节点
当Primary宕掉后,可以通过Arbiter在Secodarys中选举一个Primary节点,避免单点故障。
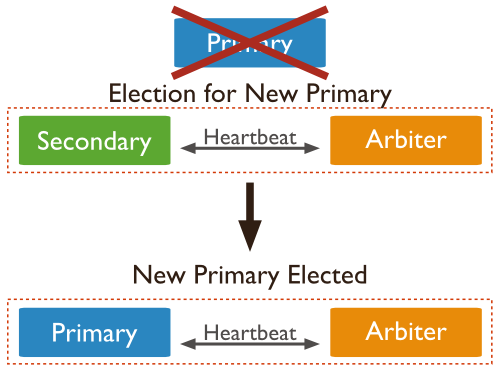
现在,我们可以增加一个仲裁节点,只负责仲裁,不做数据存储。