【原创】MySQL blackhole 存储引擎简记
14.7. The BLACKHOLE Storage Engine
The BLACKHOLE storage engine acts as a “black hole” that accepts data but throws it away and does not store it. Retrievals always return an empty result:
和其 blackhole 名字的含义一样,该存储引擎会将所有接收到的数据”吞没“,在本地不会保存所接收到的数据。所以当然也无法从对应的表中回去到相应的结果集。
mysql> CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE; Query OK, 0 rows affected (0.03 sec) mysql> INSERT INTO test VALUES(1,'record one'),(2,'record two'); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM test; Empty set (0.00 sec)
To enable the BLACKHOLE storage engine if you build MySQL from source, invoke CMake with the -DWITH_BLACKHOLE_STORAGE_ENGINE option.
编译阶段使能 BLACKHOLE 存储引擎。
To examine the source for the BLACKHOLE engine, look in the sql directory of a MySQL source distribution.
源文件查看。
When you create a BLACKHOLE table, the server creates a table format file in the database directory. The file begins with the table name and has an .frm extension. There are no other files associated with the table.
创建 BLACKHOLE 表会产生相应的表格式文件:.frm。并且仅会产生该文件。
The BLACKHOLE storage engine supports all kinds of indexes. That is, you can include index declarations in the table definition.
BLACKHOLE 存储引擎吃吃各种类型索引。
You can check whether the BLACKHOLE storage engine is available with the SHOW ENGINES statement.
通过mysql命令行查看是否可以使用 BLACKHOLE 存储引擎创建表。
Inserts into a BLACKHOLE table do not store any data, but if statement based binary logging is enabled, the SQL statements are logged and replicated to slave servers. This can be useful as a repeater or filter mechanism.
向 BLACKHOLE 表中 insert 数据时,实际不会存储到表中,但在使能了基于语句的 binlog 时,会记录下 SQL 语句,并可用于 slave 复制。这也就是 BLACKHOLE 会被用作复制结构中 中继器 或 过滤机制 的原因。
When using the row based format for the binary log, updates and deletes are skipped, and neither logged nor applied. For this reason, you should use STATEMENT for the binary logging format, and not ROW or MIXED.
注意:在使用基于行的 binlog 时,update 和 delete 会被忽略,既不会被记录到log中也不会被真正执行。基于这个原因,应该使用基于语句的 binlog 而不是基于行或者混合模式的 binlog 。
Suppose that your application requires slave-side filtering rules, but transferring all binary log data to the slave first results in too much traffic. In such a case, it is possible to set up on the master host a “dummy” slave process whose default storage engine is BLACKHOLE, depicted as follows:
在考虑 slave 侧需要过滤功能的应用场景时,如果将完整 binlog 传输到 slave 的代价是非常大的,则可以在 master 服务器上建立一个 使用 BLACKEHOLE 存储引擎的 ”dummy“ slave 进程,如下图:
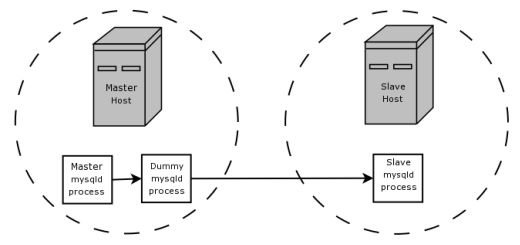
The master writes to its binary log. The “dummy” mysqld process acts as a slave, applying the desired combination of replicate-do-* and replicate-ignore-* rules, and writes a new, filtered binary log of its own. (See Section 16.1.4, “Replication and Binary Logging Options and Variables”.) This filtered log is provided to the slave.
master 会写自己的 binlog 文件,而”dummy“ mysqld 进程扮演了 slave 的角色,根据配置的 replicate-do-* 和 replicate-ignore-* 规则,记录被自身过滤后的 binlog 日志。而这个 binlog 日志就可以作为其他真正 slave 进行复制的源。
The dummy process does not actually store any data, so there is little processing overhead incurred by running the additional mysqld process on the replication master host. This type of setup can be repeated with additional replication slaves.
由于 dummy 进程实际上没有存储任何数据,所以几乎不会为 master 主机带来额外开销。
INSERT triggers for BLACKHOLE tables work as expected. However, because the BLACKHOLE table does not actually store any data, UPDATE and DELETE triggers are not activated: The FOR EACH ROW clause in the trigger definition does not apply because there are no rows.
Other possible uses for the BLACKHOLE storage engine include:
-
Verification of dump file syntax.
-
Measurement of the overhead from binary logging, by comparing performance using BLACKHOLE with and without binary logging enabled.
-
BLACKHOLE is essentially a “no-op” storage engine, so it could be used for finding performance bottlenecks not related to the storage engine itself.
BLACKHOLE 的其他可能用途:
- 校验转储文件语法。
- 测量开启 binlog 日志所带来的额外开销。
- 查找和存储引擎无关的其他方面的性能瓶颈。