SequoiaDB的数据分区操作
在SequoiaDB集群环境中,用户往往将数据存放在不同的逻辑节点与物理节点中,以达到并行计算的目的。
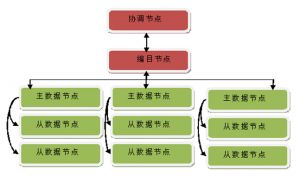
分区:把包含相同数据的一组数据节点叫一个分区,如上图绿色方块组成三个分区。
分区键:切分时,所依据的字段称为分区键。
SequoiaDB包含范围分区和Hash分区,根据上图所示进行部署,分别介绍两种分区的实际操作。
分配三台机器用于建立该集群,IP分配如下:
192.168.9.181
192.168.9.182
192.168.9.183
配置IP与主机名的对应关系如下:
192.168.9.181 bl465-1
192.168.9.182 bl465-2
192.168.9.183 bl465-3
然后规划主机与节点之间的对应关系如下:
coord(协调)节点:192.168.9.181 50000
catalog(编目)节点:192.168.9.182 30000
3个数据组,9个数据节点:
datagroup1
192.168.9.181 51000
192.168.9.182 51000
192.168.9.183 51000
datagroup2
192.168.9.181 52000
192.168.9.182 52000
192.168.9.182 52000
datagroup3
192.168.9.181 53000
192.168.9.182 53000
192.168.9.182 53000
请参照SequoiaDB官网的其它文章完成该集群的安装。
范围分区
1.创建集合时,指定分区类型为range和分区键{no:1}
>db.test.createCL(‘test’,{ShardingKey:{no:1},ShardingType:’range’})
localhost:50000.test.test
Take 2.431560s
2.确定当前集合所落的数据组,该数据组是切分的源,当前为datagroup2
> db.snapshot(4)
{
“Name”: ”test.test”,
“Details”: [
{
"GroupName": "datagroup2",
"Group": [
{
"ID": 0,
"LogicalID": 0,
"Sequence": 1,
"Indexes": 2,
"Status": "Normal",
"NodeName": "bl465-1:52000"
},
{
"ID": 0,
"LogicalID": 0,
"Sequence": 1,
"Indexes": 2,
"Status": "Normal",
"NodeName": "bl465-2:52000"
},
{
"ID": 0,
"LogicalID": 0,
"Sequence": 1,
"Indexes": 2,
"Status": "Normal",
"NodeName": "bl465-3:52000"
}
]
}
]
}
Return 1 row(s).
Takes 0.297931s.
3.切分,当前将no为[0,3333)之间的数据安排在datagroup1上,将no为[6666, ∞)之间的数据安排在datagroup3上,其它数据落在datagroup2上
> db.test.test.split("datagroup2", "datagroup1", {no:0},{no:3333})
Takes 0.4176s.
> db.test.test.split("datagroup2","datagroup3", {no:6666})
Takes 0.18957s.
4.查看数据分布情况
> db.snapshot(8)
{
"CataInfo": [
{
"GroupID": 1001,
"GroupName": "datagroup2",
"LowBound": {
"": {
"$minKey": 1
}
},
"UpBound": {
"": 0
}
},
{
"GroupID": 1000,
"GroupName": "datagroup1",
"LowBound": {
"": 0
},
"UpBound": {
"": 3333
}
},
{
"GroupID": 1001,
"GroupName": "datagroup2",
"LowBound": {
"": 3333
},
"UpBound": {
"": 6666
}
},
{
"GroupID": 1002,
"GroupName": "datagroup3",
"LowBound": {
"": 6666
},
"UpBound": {
"": {
"$maxKey": 1
}
}
}
],
“EnsureShardingIndex”: true,
“Name”: ”test.test”,
“ReplSize”: 1,
“ShardingKey”: {
“no”: 1
},
“ShardingType”: ”range”,
“Version”: 3,
“_id”: {
“$oid”: ”52665351fe13241aaa547a7f”
}
}
Return 1 row(s).
Takes 0.10201s.
5.插入数据,验证结果。
> for (i=0; i <10000; ++i){db.test.test.insert({no:i,nm:”name”+i, age:18 + i%3})}
Takes 3.418974s.
> db.getRG(‘datagroup1′).getMaster()
bl465-3:51000
Takes 0.2193s.
>datadb = new Sdb(‘ bl465-3′, 51000)
bl465-3:51000
Takes 4.4294532096s.
> datadb.test.test.find().sort({no:1}).limit(1)
{
“_id”: {
“$oid”: ”526655307a9e237453000000″
},
“no”: 0,
“nm”: ”name0″,
“age”: 18
}
Return 1 row(s).
Takes 0.1231s.
> datadb.test.test.find().sort({no:-1}).limit(1)
{
“_id”: {
“$oid”: ”526655317a9e237453000d04″
},
“no”: 3332,
“nm”: ”name3332″,
“age”: 20
}
Return 1 row(s).
Takes 0.1231s.
Hash分区
1.创建集合指定分区类型为hash和分区键{no:1}
> db.tst.createCL(‘tst’,{ShardingType:’hash’, ShardingKey:{no:1}})
localhost:50000.tst.tst
Takes 4.4294289444s.
2.确定当前集合所落的数据组,该数据组是切分的源,当前为datagroup2
> db.snapshot(4)
{
“Name”: ”tst.tst”,
“Details”: [
{
"GroupName": "datagroup2",
"Group": [
{
"ID": 0,
"LogicalID": 0,
"Sequence": 1,
"Indexes": 2,
"Status": "Normal",
"NodeName": "bl465-1:52000"
},
{
"ID": 0,
"LogicalID": 0,
"Sequence": 1,
"Indexes": 2,
"Status": "Normal",
"NodeName": "bl465-3:52000"
},
{
"ID": 0,
"LogicalID": 0,
"Sequence": 1,
"Indexes": 2,
"Status": "Normal",
"NodeName": "bl465-2:52000"
}
]
}
]
}
3.切分,针对分区键hash后落在分片[0,1365]之间的数据指定到datagroup1,针对分区键hash后落在分片[1365,2370]之间的数据指定到datagroup3,其它分片上的数据保留在datagroup2上。
> db.tst.tst.split(“datagroup2″, ”datagroup1″,{Partition:0},{Partition:1365})
Takes 0.2765s.
> db.tst.tst.split(“datagroup2″, ”datagroup3″,{Partition:1365},{Partition:2370})
Takes 0.2609s.
4.查看数据分布
> db.snapshot(8)
{
“CataInfo”: [
{
"GroupID": 1000,
"GroupName": "datagroup1",
"LowBound": {
"": 0
},
"UpBound": {
"Partition": 1365
}
},
{
"GroupID": 1002,
"GroupName": "datagroup3",
"LowBound": {
"Partition": 1365
},
"UpBound": {
"Partition": 2730
}
},
{
"GroupID": 1001,
"GroupName": "datagroup2",
"LowBound": {
"Partition": 2730
},
"UpBound": {
"": 4096
}
}
],
“EnsureShardingIndex”: true,
“Name”: ”tst.tst”,
“Partition”: 4096,
“ReplSize”: 1,
“ShardingKey”: {
“no”: 1
},
“ShardingType”: ”hash”,
“Version”: 3,
“_id”: {
“$oid”: ”5266d55efe13241aaa547a8f”
}
}
Return 1 row(s).
Takes 1.4294635948s.
5.插入数据,验证结果
插入4096条记录
> for (i = 0; i <4096; ++i) {db.tst.tst.insert({no:i,stu:”nm”+i,age:18+i%3})}
测试记录的分布情况
数据组 datagroup1
> db.getRG(‘datagroup1′).getMaster()
bl465-3:51000
Takes 1.4294407727s.
> datadb = new Sdb(‘bl465-3′,51000)
bl465-3:51000
Takes 0.24866s.
> datadb.tst.tst.count()
1355
数据组 datagroup2
> db.getRG(‘datagroup2′).getMaster()
bl465-2:52000
Takes 0.2485s.
> datadb = new Sdb(‘bl465-2′,52000)
bl465-2:52000
Takes 0.183708s.
> datadb.tst.tst.count()
1356
数据组 datagroup3
> db.getRG(‘datagroup3′).getMaster()
bl465-2:53000
Takes 0.188564s.
> datadb = new Sdb(‘bl465-2′,53000)
bl465-2:53000
Takes 0.195282s.
> datadb.tst.tst.count()
1385
Takes 0.20218s.
组所占分片数的比例与数据所占比例基本持平,则认为hash分布是比较均衡的。
小结:
需要注意的点:
1.在创建CL时,必须指定ShardingKey。
2.插入的记录必须含指定的ShardingKey才能实现切分。
3.分区键不存在时,split操作会导致数据全量转移。
4.范围切分中的百分比切分,要求集合不能为空。
5.百分比切分,是基于原数据组中的数据量而言的。
6.hash分区,要求分片数其值必须是2的幂。