SequoiaDB 与 Hive 集成
SequoiaDB与Hadoop部署
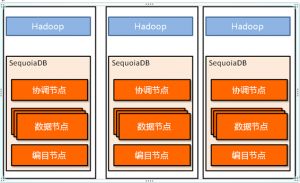
SequoiaDB与Hadoop在物理上部署方案如下图所示,部署建议如下:
l SequoiaDB与Hadoop部署在相同的物理设备上,以减少Hadoop与SequoiaDB之间的网络数据传输;
l 每个物理设备上都部署一个协调节点和多个数据节点,编目节点可选在任意三台物理设备各部署一个编目节点;
SequoiaDB支持的Hive 版本列表
n Hive 0.11.0
n Hive 0.10.0
配置方法
- 安装和配置好Hadoop/Hive 环境,启动hadoop环境;
- 拷贝sequoiadb安装目录下(默认在/opt/sequoiadb) 的hadoop/hive-sequoiadb.jar 和 java/sdbdriver.jar 两个文件拷贝到 hive/lib 安装目录下;
- 修改hive 安装目录下的 bin/hive-site.xml文件(如果不存在,可拷贝$HIVE_HOME/conf/hive-default.xml.template为 hive-site.xml文件 ),增加如下属性(假设Hive 安装在 /opt/hive 目录):
<property>
<name>hive.aux.jars.path</name> <value>file:///opt/hive/lib/hive-sequoiadb.jar,file:///opt/hive/lib/sdbdirver.jar</value>
<description>Sequoiadb store handler jar file</description>
</property>
<property>
<name> hive.auto.convert.join</name>
<value>false</value>
</property>
使用方法
创建基于SequoiaDB的表:
启动hive shell 命令行窗口,执行如下命令创建数据表;
hive> create external table sdb_tab(id INT, name STRING, value DOUBLE) stored by “com.sequoiadb.hive.SdbHiveStorageHandler” tblproperties(“sdb.address” = “localhost:50000”;)
OK
Time taken: 0.386 seconds
其中:
Sdb.address 用于指定SequoiaDB协调节点的IP和端口,如果有多个协调节点,可以写入多个,之间用逗号隔开;
从HDFS文件中倒入数据到SequoiaDB表:
hive> insert overwrite table sdb_tab select * from hdfs_tab;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there’s no reduce operator
Starting Job = job_201310172156_0010, Tracking URL = http://bl465-5:50030/jobdetails.jsp?jobid=job_201310172156_0010
Kill Command = /opt/hadoop-hive/hadoop-1.2.1/libexec/../bin/hadoop job -kill job_201310172156_0010
Hadoop job information for Stage-0: number of mappers: 1; number of reducers: 0
2013-10-18 04:44:47,733 Stage-0 map = 0%, reduce = 0%
2013-10-18 04:44:49,763 Stage-0 map = 100%, reduce = 0%, Cumulative CPU 1.85 sec
2013-10-18 04:44:50,777 Stage-0 map = 100%, reduce = 0%, Cumulative CPU 1.85 sec
2013-10-18 04:44:51,795 Stage-0 map = 100%, reduce = 100%, Cumulative CPU 1.85 sec
MapReduce Total cumulative CPU time: 1 seconds 850 msec
Ended Job = job_201310172156_0010
10 Rows loaded to sdb_tab
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.85 sec HDFS Read: 2301 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 850 msec
OK
Time taken: 12.201 seconds
说明:在导入数据到SequoiaDB表之前,请确保已经创建基于HDFS文件的 hdfs_tab数据表,并Load了数据;
查询数据:
hive> select * from new_tab;
OK
0 false 0.0 ALGERIA
1 true 1.0 ARGENTINA
2 true 1.0 BRAZIL
3 true 1.0 CANADA
4 true 4.0 EGYPT
5 false 0.0 ETHIOPIA
6 true 3.0 FRANCE
7 true 3.0 GERMANY
8 true 2.0 INDIA
9 true 2.0 INDONESIA
Time taken: 0.306 seconds, Fetched: 10 row(s)