TAIR批量导入数据问题与解决方案
TAIR批量导入数据问题与解决方案
1. 前言
分布式存储系统在TAIR阿里系内部有广泛的应用。随着业务的发展,特别是大数据处理技术飞速发展, 业务方对TAIR的应用场景也提出了新的需求。在这样情况下,TAIR也针对业务方的需求,作了大量的工作以满足业务方的需求。
在TAIR产品的发展过程中,特别是持久化TAIR在阿里系大规模应用后,希望TARI是数据孤岛,而希望TAIR中存储的数据能够在各个系统中快速流转。更好地为业务方提供灵活,高效,可靠的存储服务。
本文将介绍TAIR FASTDUMP集群的导入数据解决方案,该方案由TAIR开发团队完成。首先,描述一些典型的业务场景;其次,叙述导入数据所面临的挑战;接着,叙述现有方案,以及该方案所面临的困难;再次,给出新的批量导入数据方案;最后,实验对比。
2. 批量导入数据给TAIR带来的挑战
TAIR最初作为一个KV存储系统,对业务方提供PUT/GET这样基本接口。随着大数据时代的来临,业务方强烈需要TAIR能够支持快速导出导入数据能力。例如,业务方希望从云梯上处理过的数据快速导入到TAIR中,供其他应用使用这些数据。在这个场景中,TAIR是一个数据中转站,如图1所示。
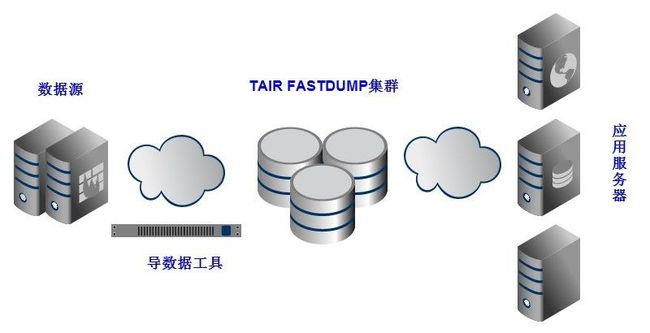
图1 TAIR FASTDUMP 集群使用场景
如图1所示,这是一个经典的应用场景,业务方希望数据能够快速导入到TAIR中。并且,在导入数据的过程中,允许对TAIR中数据增量更新。 在这样场景中,对TAIR提出了新的要求:
能够快速有效地批量导入数据。 云梯(类似hadoop集群)上产生的数据有较强的时效性,业务方希望这些数据能够尽快流向其他业务。并且这些数据随着业务的发展,数据量有可能是T级的。若导入数据速度太慢,显然不能满足要求。
批量导入数据尽可能保证TAIR集群正常服务。 从成本控制角度考虑,TAIR集群基本上是多业务方共同使用的。若一个业务在导入数据,其他业务方无法使用该集群,这也是不能接受的。也就是说,在批量导入数据的过程中,希望正常的KV数据读取的性能不会显著下降。
持久化TAIR底层存储引擎是leveldb(详细信息,请见这里); TAIR SERVER的工作线程处理客户端发来的请求,这些工作线程最终调用底层leveldb的API完成数据的读写。为了叙述TAIR所面临的挑战。将调用leveldb write接口的线程称之为Writer 线程,调用leveldb read接口的线程称之为Reader线程。另外,leveldb每个实例都有一个执行合并冗余数据的后台线程,称之为Compact线程。如图2所示。
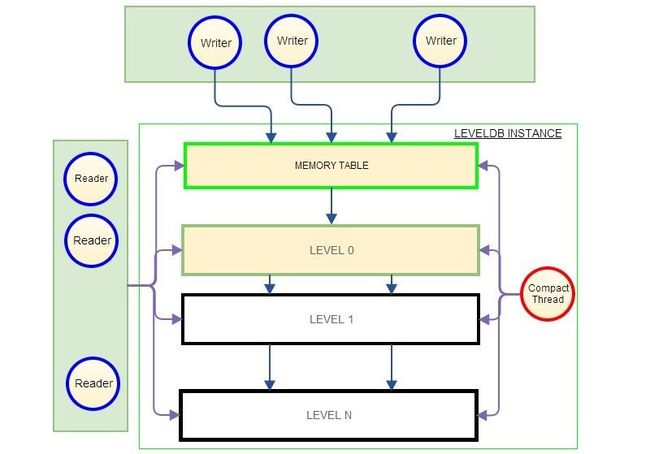
图2 Writer/Reader,Compact线程
本文并不打算详细介绍LEVELDB工作原理。如图2所示,Writer线程将数据首先写入内存Table中。当内存Table容量超过阈值后,Compact线程会将内存中数据生成SST文件,并写入磁盘。在leveldb处于稳定运行后,内存Table中的数据通常会写入LEVEL0,LEVEL0实际上是一个SST文件的集合;若LEVELn的数据容量超过阈值,compact线程将合并LEVELn 和 LEVELn+1上的一部分数据,形成新的文件记录在LEVELn+1中。这个过程会一直进行着,其结果是数据依次从内存Table中写入磁盘,记录在较高LEVEL中。在实际生成运维过程中,我们观测到Compact线程是非常耗时的,对LEVELDB的读写性能有很大影响。
显然,若快速导入数据,Writer线程需要占用更多CPU,快速处理写请求。而这很容易让内存Table容量超过阈值,Compact线程启动后,Writer线程会主动减缓写入数据的速度。并且,Compact线程在合并数据的时候,会占用CPU和持有全局锁,这也会显著降低Writer/Reader线程的处理能力,影响TAIR读写的RT。
3. TAIR现有解决方案以及问题
有随着业务方需求的变化,TAIR提供了批量处理接口MPUT/MGET。MPUT/MGET接口相比PUT/GET接口,可以一次性处理批量的KV数据。应用输入批量数据,TAIR客户端会将批量KV按其目标请求地址分类,处于同一目标地址的KV会在同一次RPC中完成请求。批量接口最好的情况是,所有的KV都发往同一个目标地址,在一次RPC中完成;最坏的情况是,分N个RPC完成请求。批量接口的优势在于节省了网络开销。如图3所示。

图3 MPUT接口示意图
为了避免LEVELDB作过多compact工作,对数据作排序,去重等预处理。这样数据到达SERVER端后,在compact过程中,只需要将SST文件从低level移动到高level, 从而减少CPU使用率。
在我们生产实践中,我们发现业务方使用我们提供的批量接口向持久化TAIR中导入数据效率不能满足我们的期望。MPUT接口的请求,最终有Writer线程处理。发现一些问题,列举如下三个:
问题1: Compact线程容易成为系统瓶颈。 将内存中的table转化为磁盘SST文件是由Compact Thread线程完成的。每个instance只有一个该线程。所以,当大量Writer线程写入数据的时候,compact 线程往往成为系统瓶颈。
问题2:导入数据时候容易导致读写延迟增加。Writer线程,Reader线程,Compact 线程会持有同一个锁来完成一些操作。若Compact线程频繁运行,持锁的时间就会变长,Reader/Writer线程会等待锁,增加了数据读写的延迟。
问题3: 流控复杂。在导入数据的过程中,很容易将网卡跑满。另一方面,若批量接口超时,业务逻辑试图去重试。我们知道超时并不意味着数据没有到达SERVER端,而重试后就可能导致有重复数据,使得Compact工作量显著增加,从而影响系统性能。
正是出于解决上述问题,TAIR团队提出新的批量导入数据方案,称之为BulkWrite方案.
4. BulkWrite解决方案以及实现
在数据导入的过程中,有2个因素会影响TAIR的服务能力:
1)网卡打满;
2)CPU占用用率高;
对于1)可以通过流控来解决,避免批量导入数据将网卡打满;对于2)来说,需要降低批量导入数据线程对CPU的使用率。
我们知道,在批量导入数据的时候,内存中的数据最终持久化到磁盘经过如下若干个步骤:
在内存中对对无序导入的数据有序化;
根据内存内容创建SST文件;
将文件写入磁盘;
并将文件加入到当前版本中;
在无序输入数据有序化的过程中,需要对key调用一次字符串比较函数;在创建sst文件的过程中,同样需要一次字符串比较函数。这些都是非常消耗CPU资源的。另外一方面,批量导入的数据通过TCP传入到Server端。Server端对这些协议的处理也是消耗CPU的。那么如何减少CPU的消耗,将有限的CPU留给其他读写线程。
新的方案是:将复杂的耗时计算迁移到客户端,客户端计算资源相对廉价而丰富。具体地:
在客户端对所有数据进行排序;
对有序的数据按一定size切分,创建SST文件;
在客户端,将SST文件通过TCP直接发给server端;
server端在内存中更新SST中部分字段内容,并将内存中的SST文件写入磁盘;
将SST文件加入到当前版本中;
在该方案中,我们可以看到,将数据排序,创建SST等耗时计算移动到客户端。server端只是一次遍历所有key 修改其sequence, 写入磁盘,并将sst纳入当前版本里。这2个步骤必须放在Server端完成。现有方案与BulkWrite访问对比如图所示。
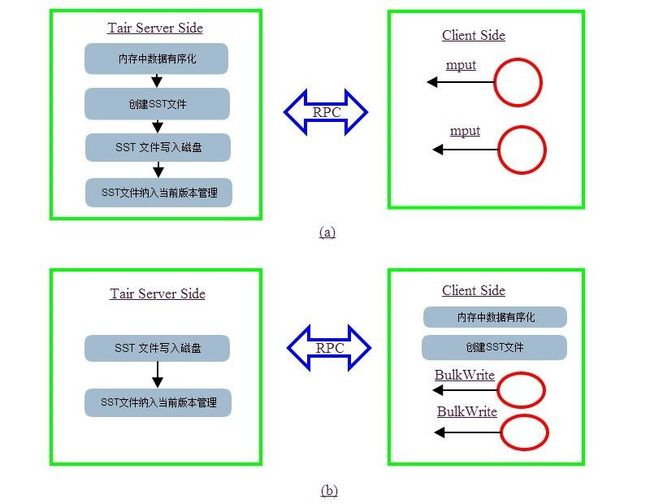
图4 BulkWrite方案与MPUT方案示意图
在leveldb目前实现中,并没有提供直接导入sst文件的接口。TAIR开发团队实现了上述方案。 这里给出BulkWrite实现的流程图,如图5所示。
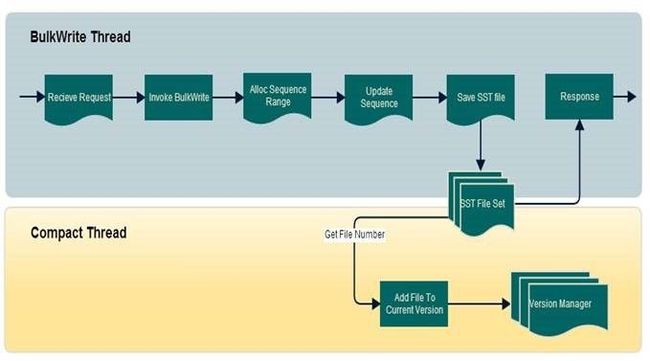
图5 BulkWrite流程图
5. 测试结果
测试机器配置为,48G内存,24cores, 500G SSD盘,千兆网卡(负载均衡模式)。在给定的导入数据速度情况下, 分别采用现有方案和BulkWrite方案,导入数据。然后起N个链接,分别作PUT和GET操作,统计PUT/GET的QPS以及RT。
在导入数据情况下,对PUT接口的测试步骤:
1)清理数据,重启DATA SERVER,取消流控限制;
2)启动systemtap统计接口QPS以及RT脚本,启动CPU采样脚本,启动网卡数据监控脚本;
3) 启动BulkWrite或者Mput压测程序(实验分4次进行);
4)启动YCSB(压测工具),写入1000000条数据,每条长度512B;
5)数据收集,绘制成统计图;
统计数据如图6所示,在该测试场景中,批量导入数据的速度为80M/s, 其中绿色曲线表示现有方案导入数据,红色曲线表示BulkWrite方案导入数据所对应的统计图。在这个测试场景下,导入数据速度是80M/s。最后,统计了在批量导入数据速度分别是80M/s和200M/s的请看下,CPU使用率情况。
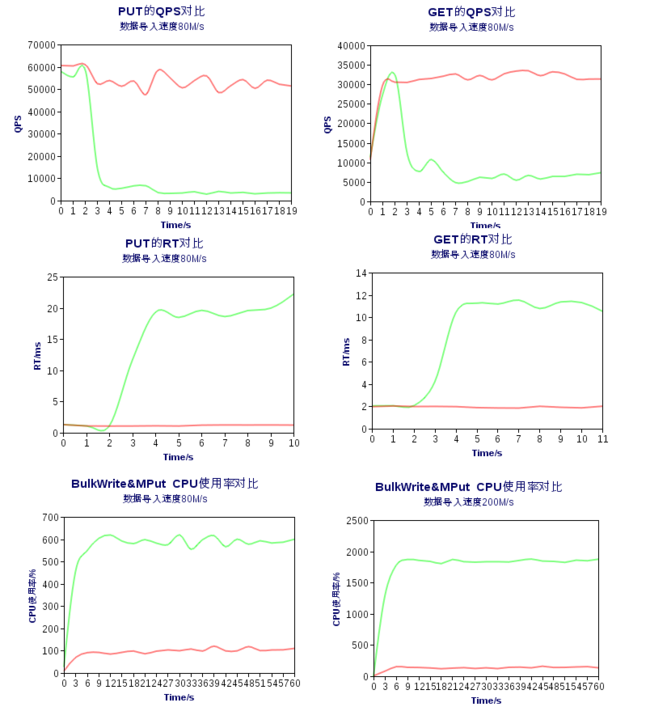
图6 PUT、GET接口的 QPS, RT以及CPU使用率对比的统计数据。
通过测试数据,可以看出BulkWrite方案有效地提高了导入数据的性能,并且对正常读写影响较小。同时,可以看到在同等速率导入数据的时候,BulkWrite占用CPU显著减少。随着导入数据速度的增加,BulkWrite方案要显著节约CPU。
6. 后续工作
目前,在千兆网卡下,BulkWrite方案跑满网卡时CPU使用率并不高。后续,可以在Client端对SST文件压缩,到Server端解压数据。占用少量CPU使用率的情况下,提高导入数据速度。
注意:版权归@丰茂所有,转载请注明出处。