Hadoop入门进阶步步高(三)-配置Hadoop
三、配置Hadoop
1、设置$HADOOP_HOME/conf/hadoop-env.sh
这个文件中设置的是Hadoop运行时需要的环境变量,在1.2.1版中共有19个环境变量,如下:
变量名称 |
默认值 |
说明 |
JAVA_HOME |
|
设置JDK的路径,这个必须设置,否则Hadoop无法启动,值如: /usr/local/jdk1.6.0_33 |
HADOOP_CLASSPATH |
空 |
这个用以设置用户的类路径,也可以在执行计算之前设置 |
HADOOP_HEAPSIZE |
1000m |
设置Hadoop堆的大小,根据自己环境的实际情况进行设置了。 |
HADOOP_OPTS |
-server |
Hadoop启动时的JVM参数,默认是以server模式启动,可以加入-X或-XX之类的参数 |
HADOOP_NAMENODE_OPTS |
-Dcom.sun.management.jmxremote $HADOOP_NAMENODE_OPTS |
该选项的值会附加到HADOOP_OPTS之后,在启动NameNode时设置的JVM参数。 如想手动设置NameNode的堆、垃圾回收等信息,可以在这里设置: export HADOOP_NAMENODE_OPTS="-Xmx2g -XX:+UseParallelGC ${HADOOP_NAMENODE_OPTS}" 其它的节点类似设置。 |
HADOOP_SECONDARYNAMENODE_OPTS |
-Dcom.sun.management.jmxremote $HADOOP_SECONDARYNAMENODE_OPTS |
该选项的值会附加到HADOOP_OPTS之后,在启动SecondaryNameNode时设置的JVM参数 |
HADOOP_DATANODE_OPTS |
-Dcom.sun.management.jmxremote $HADOOP_DATANODE_OPTS |
该选项的值会附加到HADOOP_OPTS之后,在启动DataNode时设置的JVM参数 |
HADOOP_BALANCER_OPTS |
-Dcom.sun.management.jmxremote $HADOOP_BALANCER_OPTS |
该选项的值会附加到HADOOP_OPTS之后,在启动BalancerNode时设置的JVM参数 |
HADOOP_JOBTRACKER_OPTS |
-Dcom.sun.management.jmxremote $HADOOP_JOBTRACKER_OPTS |
该选项的值会附加到HADOOP_OPTS之后,在启动JobTracker时设置的JVM参数 |
HADOOP_TASKTRACKER_OPTS |
空 |
该选项的值会附加到HADOOP_OPTS之后,在启动TaskTracker时设置的JVM参数 |
HADOOP_CLIENT_OPTS |
空 |
该选项增加的参数,将会作用于多个命令,如fs, dfs, fsck, distcp等 |
HADOOP_SSH_OPTS |
空 |
SSH连接的选项,值可以是如下这样: -o ConnectTimeout=1 -o SendEnv=HADOOP_CONF_DIR |
HADOOP_LOG_DIR |
${HADOOP_HOME}/logs |
日志文件存放的目录 |
HADOOP_SLAVES |
$HADOOP_HOME/conf/slaves |
Slaves所在的配置文件,每行配置一个slave |
HADOOP_MASTER |
master:/home/$USER/src/hadoop |
用于设置Hadoop代码的同步目录。 |
HADOOP_SLAVE_SLEEP |
0.1
|
用于设置slave往master发送命令的时间停顿,单位为秒。 这个在大型的集群之中非常有用,master才有足够的时间来处理这些请求。 |
HADOOP_PID_DIR |
/tmp |
Hadoop PID文件的存放目录,这个最好是修改一下,因为/tmp目录通常来说是任何人都可以访问的,有可能存在符合链接攻击的风险。 |
HADOOP_IDENT_STRING |
$USER |
用于代表当前的Hadoop实例。 |
HADOOP_NICENESS |
10 |
Hadoop守护进行的定时优先级,可以通过“man nice”获取更多信息 |
通常来说,我们只需要关注JAVA_HOME、HADOOP_HEAP_SIZE、HADOOP_PID_DIR这几个,当然其它的也需要注意了,对其全部了解了才能够更加充分的发挥其能力,面临问题的时候才会知道从哪些方面去入手解决。
JAVA_HOME:
JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器,设置JAVA_HOME环境变量:
export JAVA_HOME=/usr/local/jdk1.6.0_33 |
如果使用的是Mac OS X系统,那么在启动hdsf的NameNode和secondaryNameNode时,会报出Unable to load realm info from SCDynamicStore 的错误提示,解决该问题的办法是,在hadoop-env.sh文件里面增加一行:
export HADOOP_OPTS="-Djava.security.krb5.realm=OX.AC.UK -Djava.security.krb5.kdc=kdc0.ox.ac.uk:kdc1.ox.ac.uk" |
详见文章:http://gauss-deng.iteye.com/blog/1370295
HADOOP_HEAPSIZE:
还可根据实际情况设置HADOOP_HEAPSIZE的值,单为mb,如果不设置默认值是1000,我的内存没有这么大并且测试用例不会用到那么大的堆,所以我也设置了一个这个值。
export HADOOP_HEAPSIZE=20 |
HADOOP_PID_DIR:
Hadoop PID文件的存放目录,这个最好是修改一下,因为/tmp目录通常来说是任何人都可以访问的,有可能存在符合链接攻击的风险。
export HADOOP_PID_DIR=/home/fenglibin/hadoop_tmp |
2、配置$HADOOP_HOME/conf/core-site.xml
参数如下(部分):
参数 |
默认值 |
说明 |
fs.default.name |
file:/// |
NameNode的URI,如: hdfs://locahost:9000/ |
hadoop.tmp.dir |
/tmp/hadoop-${user.name} |
其它临时目录的基本目录, /home/fenglibin/hadoop_tmp |
hadoop.native.lib |
true |
是否使用hadoop的本地库 |
hadoop.http.filter.initializers |
空 |
设置Filter初使器,这些Filter必须是hadoop.http.filter.initializers的子类,可以同时设置多个,以逗号分隔。这些设置的Filter,将会对所有用户的jsp及servlet页面起作用,Filter的顺序与配置的顺序相同。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
配置示例:
<configuration> <property> <!-- 用于设置Hadoop的文件系统,由URI指定 --> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <property> <!-- 配置Hadoop的临时目录,默认在/tmp目录下,但是/tmp上面可能会被系统自动清理掉。--> <name>hadoop.tmp.dir</name> <!-- 目录如果不存在,需要手动创建 --> <value>/home/fenglibin/hadoop_tmp</value> <description>A base for other temperary directory</description> </property> </configuration> |
3、配置$HADOOP_HOME/conf/mapred-site.xml文件
参数如下(部分):
参数 |
说明 |
示例 |
mapred.job.tracker |
配置JobTracker,以Host和IP的形式 |
localhost:9001 |
mapred.system.dir |
MapReduce框架在HDFS存放系统文件的路径,必须能够被server及client访问得到,默认值: ${hadoop.tmp.dir}/mapred/system |
${hadoop.tmp.dir}/mapred/system |
mapred.local.dir |
MapReduce框架在本地的临时目录,可以是多个,以逗号作分隔符,多个路径有助于分散IO的读写,默认值: ${hadoop.tmp.dir}/mapred/local |
${hadoop.tmp.dir}/mapred/local |
mapred.tasktracker.{map|reduce}.tasks.maximum |
在同一台指定的TaskTacker上面同时独立的执行的MapReduce任务的最大数量,默认值是2(2个maps及2个reduces),这个与你所在硬件环境有很大的关系,可分别设定。 |
2 |
dfs.hosts/dfs.hosts.exclude |
允许/排除的NataNodes,如果有必要,使用这些文件控制允许的DataNodes。 |
|
mapred.hosts/mapred.hosts.exclude |
允许/排除的MapReduces,如果有必要,使用这些文件控制允许的MapReduces。 |
|
mapred.queue.names |
可用于提交Job的队列,多个以逗号分隔。MapReduce系统中至少存在一个名为“default”的队列,默认值就是“default”。 Hadoop中支持的一些任务定时器,如“Capacity Scheduler”,可以同时支持多个队列,如果使用了这种定时器,那么使用的队列名称就必须在这里指定了,一旦指定了这些队列,用户在提交任务,通过在任务配置时指定“mapred.job.queue.name”属性将任务提交到指定的队列中。 这些属于这个队列的属性信息,需要有一个单独的配置文件来管理。 |
default |
mapred.acls.enabled |
这是一个布尔值,用于指定授权用于在执行队列及任务操作时,是否需要校验队列及任务的ACLs。如果为true,在执行提交及管理性的任务时会检查队列的ACL,在执行授权查看及修改任务时任务的会检查任务ACLs。队列的ACLs通过文件mapred-queue-acls.xml中的mapred.queue.queue-name.acl-name这样格式的参数进行指定,queue-name指的是特定的队列名称;任务的ACLs在mapred中会有说明。 默认值为false。 |
false |
配置示例:
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration> |
4、配置$HADOOP_HOME/conf/mapred-queen-acks.xml文件
参数如下(部分):
参数 |
说明 |
示例 |
mapred.queue.queue-name.acl-submit-job |
这里配置可以提交任务到默认队列(the ‘default’ queue)的用户名和组名。 注:这里的queue-name指的是一个特定的队列名称。 有两种指定的方式: 1、同时指定用户名和组名 值的格式是用户名和用户名以逗号分隔,组与组之间用逗号分隔,用户名和组之间使用空格分隔,如: user1,user2 group1,group2 2、只指定组名 在组名的前名留一下空格,如: group1,group2 3、允许所有的用户都可以提交任务,此时的值设为“*”; 4、如果设置为空格,表示不允许任何用户提交任务;
要使这些配置生效,必须设置Map/Reduce的mapred.acls.enabled的值为true。 不过不管这里的ACL的配置是怎么样,启动集群的用户以及通过通过mapreduce.cluster.administrators设置的集群管理员,都可以提交任务到队列中。 |
user1,user2 group1,group2 |
mapred.queue.queue-name.acl-administer-jobs |
列出可以对指定的队列执行任务管理的用户名和组名,如查看任务详情、修改任务优先级或者是杀掉任务。 设置的格式同上面一样。 注:任务的拥者是可以对其自己的任务进行优先级的调整或者杀掉该任务的。
与上面的配置一样,要使这些配置生效,必须设置Map/Reduce的mapred.acls.enabled的值为true。 不过不管这里的ACL的配置是怎么样,启动集群的用户以及通过通过mapreduce.cluster.administrators设置的集群管理员,都可以对该队列中的任务执行任何操作。 |
user1,user2 group1,group2 |
配置示例:
<configuration> <property> <name>mapred.queue.default.acl-submit-job</name> <value> </value> </property>
<property> <name>mapred.queue.default.acl-administer-jobs</name> <value> </value> </property> </configuration> |
5、配置$HADOOP_HOME/conf/hdfs-site.xml文件
这个文件的内容,可通过将$HADOOP_HOME/src/hdfs/hdfs-default.xml中的文件拷贝过来,然后再修改,如果这个文件中没有内容,那么使用的默认值就和$HADOOP_HOME/src/hdfs/hdfs-default.xml中设置的一样,如果在这里设置了就会覆盖系统中相应名称的默认值,如这里将内容的复制份数设置为1,而系统默认的复制份数为3,如下:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> |
6、格式化namenode
hadoop namenode -format |
7、启动Hadoop
./bin/start-all.sh |
如果是出现如下结果,那就说明Hadoop已经成功启动了:
fenglibin@ubuntu1110 :/usr/local/hadoop-1.2.1$ jps 29339 SecondaryNameNode 29661 Jps 28830 JobTracker 29208 DataNode 28503 NameNode 29514 TaskTracker |
此时我们可以通过WEB方式查看NameNode及Jobtracker的状态了:
NameNode:http://localhost:50070/
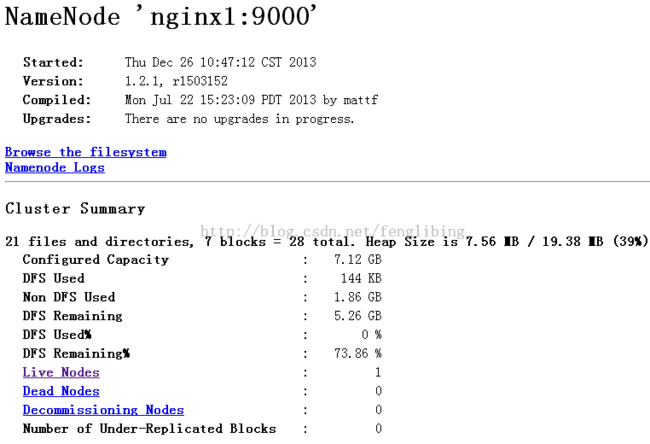
JobTracker:http://localhost:50030/

如果只是测试map/reduce,这里只需要启动如下命令:
./bin/start-mapred.sh |
8、启动Hadoop可能会遇到的问题
后面会提到。
版权声明:本文为博主原创文章,未经博主允许不得转载。