JVM学习之JVM垃圾收集
垃圾回收历史,早在Lisp 就有了垃圾收集的功能.垃圾收集的问题主要在三个地方:哪些对象需要回收,在什么时候回收对象,如何回收对象.
一.哪些对象需要回收
判断哪些对象需要回收的算法主要有两种,引用计数算法,可达性分析算法.
1.引用计数算法:
一个变量引用一个对象的时候,该对象的引用计数器就加1,有多少个变量引用对象,那这个对象的引用计数器就是多少,少一个引用的时候就减1.直到引用计数器变成0,就成为可回收对象.
2.可达性分析算法
从一个名为ROOTGC出发遍历,只要从ROOTGC通过对象内的引用无法到达的对象就是可回收对象.可以选择类变量作为ROOTGC.

关于Java中的引用,java中分为强引用,软引用,弱引用,虚引用.
强引用:就是A a = new A();
软引用: 内存回收之前对软引用的对象进行回收 SoftReference
弱引用:下次垃圾回收一定会执行到. WeakReference
虚引用:无法通过虚引用去获取对象,只能在对象被回收的时候收到系统的一个通知.
二.怎么回收
垃圾回收算法:标记清除算法,复制算法,标记整理算法,分代算法
1.标记清理算法: 标记两次,第二次标记完成之后就清理,标记效率低下,会产生大量内存碎片.
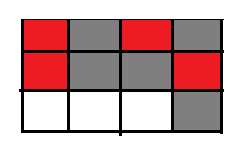
如图所示,红色是没被标记内存,灰色是标记内存.,第二次编辑完成之后清除灰色区域,然后会有很 多不连续的内存碎片.
2.复制算法
将内存分为两块,对象只放其中一块上面,在需要回收的时候,把所有对象移动到另一块内存上.然后回收之前的那块内存.有人经过分析,Eden:Survivor Fron:To = 8:1:1是比较合理的情况.
3.标记整理算法
将非标记的对象移动到一起,然后清理所有内存.
4.分代回收算法
根据对象存货周期不通,分成新生代,老年代,在新生代里面由于被回收的几率较大所以使用复制算法,在老年代里面由于被回收的几率较小使用标记标记整理算法.这样的组合使用大大的提高了垃圾回收的效率
在HotSpot中GC的时候需要停顿所有执行中的java线程,以保证可达性分析的准确性.
垃圾收集器
是由java虚拟机实现的垃圾算法的实现.
新生代中的垃圾收集器:
Serial收集器 : 使用复制算法,在进行垃圾回收的时候停顿所有java线程.简单高效.
ParNew收集器 : 复制算法,是Serial收集器多线程的实现. 默认线程数与CPU个数相同.通过 --XX:ParallelGCThreads设置线程大小.
Parallel Scavenge收集器: 和ParNew收集器差不多,但是关注点是达到可控制的吞吐量(用户代码运行时间/(用户代码运行时间+GC时间)). 通过--XXMaxGCPauseMills设置最大垃圾回收时间. --XX: MaxGcTimeRate设置吞吐量大小.
老年代中的垃圾收集器:
1.Serial Old收集器: 使用标记整理算法.是Serial收集器的老年代版本.
2.Parallet Old收集器:是Parallet Scavenge收集器的老年版本.
3.CMS收集器(Concurrent Mark Sweep) : 使用标记清楚算法,关注点是最短回收时间.适用于互联网和B/S系统的服务端
垃圾回收过程:
大多数情况对象在Eden去进行分配,(比较小的情况如对象比较大的时候会直接放到老年代中),当Eden区没有足够的空间的时候,会进行一次Minor GC(把Eden存活对象和非空的Servivor中存活对象复制到空的Servivor空间,然后清除Eden和之前的Servivor空间).每经过一次Minor GC还存活的对象的年龄加一,当年龄达到一定数(默认15)的时候进入老年代.在发生Minor GC之前会检查一下老年代空闲空间是否足够,不够的话进行一次Full GC.