kafka 基础01
总结:
1.kafka 中可以分步不同的组,消息可以被不同组里面的消费者多次消费,也可以使用queue的方式
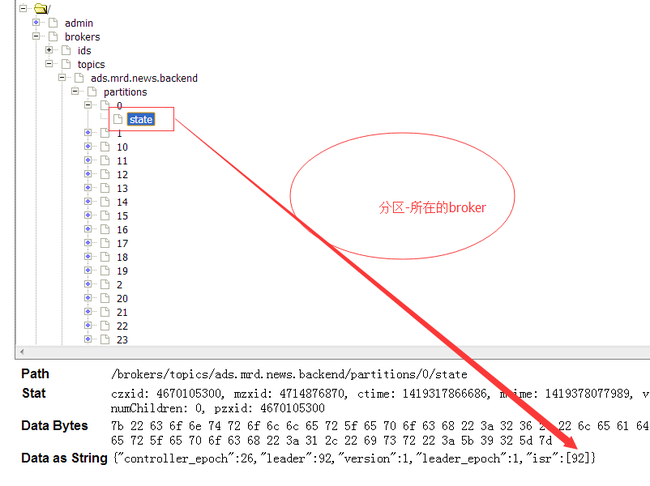
2. 观察zookeeper中kafka中的信息:
[zk: air00:2181(CONNECTED) 8] ls /
[consumers, config, controller, admin, brokers, zookeeper, controller_epoch]
[zk: air00:2181(CONNECTED) 9] ls /consumers
[test01, test02]
[zk: air00:2181(CONNECTED) 10] ls /consumers/test01
[offsets, owners, ids]
[zk: air00:2181(CONNECTED) 11] ls /consumers/test01/offsets
[test]
[zk: air00:2181(CONNECTED) 12] ls /consumers/test01/offsets/test
[1, 0]
[zk: air00:2181(CONNECTED) 13]
可以看出消费者的信息存在于zookeeper中的节点里面
3. 新来的消费者,不能获取老的数据
4. 一个话题而言,无论有多少使用者订阅了它,一条条消息都只会存储一次
5. 线性读取,使用磁盘缓存,消息默认保存一周
6. Linux中这是通过sendfile这个系统调用实现的。通过Java中的API,FileChannel.transferTo
7. Kafka对这种压缩方式提供了支持。 一批消息可以打包到一起进行压缩,然后以这种形式发送给服务器。这批消息都会被发送给同一个消息使用者,并会在到达使用者那里之前一直保持为被压缩的形式。
8.在Kafka中,我们将该最高水位标记称为“偏移量”(offset)标记消息的状态
9.在Kafka中,由使用者负责维护反映哪些消息已被使用的状态信息(偏移量)(Zookeeper中)
10.pull 的处理方式
11. 每个代理都可以在Zookeeper(分布式协调系统)中注册的一些元数据(例如,可用的主题)。生产者和消费者可以使用Zookeeper发现主题和相互协调。
12.采用客户端基于zookeeper的负载均衡可以解决部分问题。如果这么做就能让生产者动态地发现新的代理,并按请求数量进行负载均衡。类似的,它还能让生产者按照某些键值(key)对数据进行分区(partition)而不是随机乱分,
生产者:
13.。在Kafka中,生产者有个选项(producer.type=async)可用指定使用异步分发出产请求(produce request)。这样就允许用一个内存队列(in-memory queue)把生产请求放入缓冲区,然后再以某个时间间隔或者事先配置好的批量大小将数据批量发送出去。因为一般来说数据会从一组以不同的数据速度生产数据的异构的机器中发布出,所以对于代理而言,这种异步缓冲的方式有助于产生均匀一致的流量,因而会有更佳的网络利用率和更高的吞吐量
14.kafak.producer.Partitioner接口,可以对分区函数进行定制。在缺省情况下使用的是随即分区函数
15.提供基于zookeeper的代理自动发现功能 —— 通过使用zk.connect配置参数指定zookeeper的连接url,就能够使用基于zookeeper的代理发现和负载均衡功能。在有些应用场合,可能不太适合于依赖zookeeper。在这种情况下,生产者可以从broker.list这个配置参数中获得一个代理的静态列表,每个生产请求会被随即的分配给各代理分区。如果相应的代理宕机,那么生产请求就会失败。
16.使用者重新复杂均衡的算法可用让小组内的所有使用者对哪个使用者使用哪些分区达成一致意见。使用者重新负载均衡的动作每次添加或移除代理以及同一小组内的使用者时被触发。对于一个给定的话题和一个给定的使用者小组,代理分区是在小组内的所有使用者中进行平均划分的。一个分区总是由一个单个的使用者使用。这种设计方案简化了实施过程。假设我们运行多个使用者以并发的方式同时使用同一个分区,那么在该分区上就会形成争用(contention)的情况,这样一来就需要某种形式的锁定机制。如果使用者的个数比分区多,就会出现有写使用者根本得不到数据的情况。在重新进行负载均衡的过程中,我们按照尽量减少每个使用者需要连接的代理的个数的方式,尝尝试着将分区分配给使用者。
package com.kafka.test;
import java.util.*;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.javaapi.producer.Producer;
public class Producer01 {
public static void main(String[] args) {
String topic="test";
Properties props = new Properties(); //9092
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "air00:9092");
ProducerConfig config = new ProducerConfig(props);
Producer<String, String> producer = new Producer<String, String>(config);
producer.send(new KeyedMessage<String, String>(topic, "test" ));
producer.close();
}
}
消费者:
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
public class Consumer01 {
static String groupId="test01";
static String topic="test";
public static void main(String[] args) {
Properties props = new Properties();
props.put("zookeeper.connect","air00:2181,air01:2181,air02:2181");
props.put("group.id", groupId);
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
kafka.javaapi.consumer.ConsumerConnector consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
new ConsumerConfig(props));
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while(it.hasNext())
System.out.println(new String(it.next().message()));
}
}