openstack
介绍OpenStack这一IaaS平台的起源、发展历史和核心项目,以OpenStack Compute为例,剖析计算资源管理部分的实现构架,最后简要阐述了OpenStack的发展动向。
什么是OpenStack
OpenStack是一个起源于NASA和Rackspace,定位于IaaS(Infrastructure as a Service) 的开源云计算项目。作为云领域的Apache,OpenStack以建立一个同时适用于不同规模的公有云和私有云,并具备高伸缩性的开源云计算平台为目标。
OpenStack的历史
作为一个非常年轻的开源项目,OpenStack于2010的7月成立,源代码来自于NASA的Nebula云平台和Rackspace的Cloud Files实现。
其中,NASA的Nebula项目原来基于另一个叫做Eucalyptus的云计算平台。但是NASA发现Eucalyptus已经不能满足他们所需要的云计算规模,而Eucalyptus也不是完全的开源项目,这导致NASA无法将他们对代码的改进加入Eucalyptus的实现中。NASA最终重写了Nebula的代码并贡献给了OpenStack,也就是后来的OpenStackCompute项目。
而Cloud Files则是在OpenStack成立之前就已经由Rackspace (NYSE: RAX) 用于其对象存储的商业运营,在加入OpenStack之后CloudFiles的实现就成为了其中的Object Storage项目。
在成立后短短四个月,OpenStack的第一个版本Austin发布。在以下的版本历史中可以看到,OpenStack每几个月就会有一个新的发布,目前最新的版本今年9月发布的Diablo:
· Austin 10月21日,2010
· Bexar 2月3日,2011
· Cactus 4月15日,2011
· Diablo 9月22日,2011
OpenStack的组成
从功能来划分,OpenStack包含了以下三个项目:
· Compute (Nova)
OpenStack Compute是OpenStack中通过创建、配置和管理虚拟机来建立具有高伸缩度的云计算平台项目。OpenStack Compute可以用来管理云环境中的虚拟机和网络,而且具备不依赖于某些特定硬件和虚拟机hypervisor的优点。目前,已经支持大量的标准化硬件设备和多个主流的hypervisor。
· Object Storage (Swift)
OpenStack Object Storage是OpenStack中利用标准化硬件来创建具有冗余和高伸缩性的peta-byte级对象存储的开源项目。不同于文件系统或是一些实时数据存储系统,对象存储更适合于长期的静态数据的存储,提取和更新。像虚拟机镜像,照片,邮件,备份数据都适合于这种对象存储的方式。由于采用了非集中式的设计,OpenStack Object Storage具备了更好的可伸缩性和性能。
利用Object Storage, 数据对象被写入到云环境中的多个硬件设备上,而数据在整个集群中的复制与同步完全由软件来负责。存储集群可以很容易的通过增加新结点完成水平扩展,另一方面,如果发生结点故障,该结点的内容能够被自动复制到其他活跃结点处(从其他数据副本)。从云平台的成本角度,由于OpenStack使用软件来确保数据在集群中的分布,使用的是标准化的硬件,因此具有成本上的优势。
· Image Service (Glance)
OpenStack ImageService 提供了对虚拟机磁盘镜像注册,发现和读取服务。该服务可以采用包括OpenStack Object Storage在内的多种后端存储方式来存储虚拟机磁盘镜像,同时在前端 提供了相应的REST API来支持镜像相关信息的查询。
OpenStack Compute构架剖析
下面就以OpenStack Compute为例,剖析其构架设计及相关实现细节。
OpenStackCompute中的组件主要可以分成以下3类:(其中第3类数据库和消息队列使用的是现有软件,其他组件是OpenStack的Python实现)
·前端API模块,也就是nova-api
·负责资源协调调度的守护进程,包括nova-compute, nova-network, nova-schedule等
·负责消息传递和信息共享的组件,也就是数据库和消息队列
而这些OpenStack组件之间的交互关系可以由以下的构架来描述:
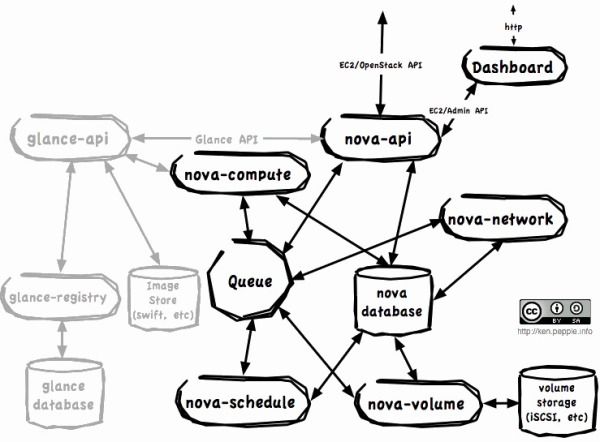
查看大图
(图片来源:http://ken.pepple.info/openstack/2011/04/22/openstack-nova-architecture/)
OpenStack的前端是nova-api, 作为外部访问计算资源的web services接口,nova-api除了自身的OpenStack API以外也支持EC2 API。Nova-api负责发起相应的类似运行新虚拟机实例这样的资源调度活动,在实现层面,nova-api是Pythhon实现的WSGI应用,同其他相应资源管理模块的交互通过Message Queue进行传递。
Nova-schedule在OpenStack中负责为虚拟机实例指定运行的物理服务器,目前有多种调度方法可供选择,比如简单负载均衡方法和随机方法,当然OpenStack也提供了插件机制允许用户使用自己实现的调度算法。Nova-schedule和下面要介绍的nova-compute, nova-network类似,都是由Python实现的守护进程。
Nova-compute负责对虚拟机实例的生命周期管理:包括虚拟机的创建及终止。其运作方式是从消息队列读取所要完成的操作,执行相应的命令,并及时将虚拟机实例的状态信息更新至数据库。相类似的,nova-network也是从消息队列读取操作,然后执行网络相关的配置操作。在数据存储方面,nova-volume提供了volume管理,为虚拟机实例提供额外的volume访问。
正如前面所提到的,消息队列本身并不由OpenStack实现,而是使用了RabbitMQ,负责所有这些守护进程之间的消息传递。在理论上,任何具有Python ampqlib支持的AMPQ消息队列都可以在OpenStack中替代RabbitMQ使用。另外,OpenStack云环境的配置和运行信息被存储在SQL数据库中,理论上OpenStack可以使用任何支持SQL-Alchemy的数据库。
OpenStack发展动向
随着新版本Diablo的发布,Identity (Keystone)和Dashboard(Horizon)这样一些新的核心项目被加入到OpenStack。作为OpenStack的identity服务的python实现, Keystone 提供了云计算环境中authentication, authorization和servicecatalog的功能。而Horizon提供的是一个OpenStack服务管理的基本用户界面。可以看到随着OpenStack的不断演进,一个越来越完整的云计算平台正逐步呈现出来。从IaaS的概念模型上来看,OpenStack在计费,日志和policy管理等方面还没有完整的实现, 相信OpenStack社区也会很快在后继的版本中加入这部分功能的支持,或者通过plug-in方式支持与云服务提供商的第三方实现集成。