【转】深入剖析ConcurrentHashMap(1)
原文是09年时写的,在公司的邮件列表发过,同事一粟 和清英 创建的并发编程网 对这方面概念和实战有更好的文章,贴出来仅供参考。pdf格式在:http://www.slideshare.net/hongjiang/concurrent-hashmap 可以获取
ConcurrentHashMap是Java5中新增加的一个线程安全的Map集合,可以用来替代HashTable。对于ConcurrentHashMap是如何提高其效率的,可能大多人只是知道它使用了多个锁代替HashTable中的单个锁,也就是锁分离技术(Lock Stripping)。实际上,ConcurrentHashMap对提高并发方面的优化,还有一些其它的技巧在里面(比如你是否知道在get操作的时候,它是否也使用了锁来保护?)。
我会试图用通俗一点的方法讲解一下 ConcurrentHashMap的实现方式,不过因为水平有限,在整理这篇文档的过程中,发现了更多自己未曾深入思考过的地方,使得我不得不从新调整了自己的讲解方式。我假设受众者大多是对Java存储模型(JMM)认识并不很深的(我本人也是)。如果我们不断的对ConcurrentHashMap中一些实现追问下去,最终还是要归到JMM层面甚至更底层的。这篇文章的关注点主要在同步方面,并不去分析HashMap中的一些数据结构方面的实现。
ConcurrentHashMap实现了ConcurrentMap接口,先看看 ConcurrentMap 接口的文档说明:
提供其他原子 putIfAbsent、remove、replace 方法的 Map。
内存一致性效果:当存在其他并发 collection 时,将对象放入 ConcurrentMap 之前的线程中的操作 happen-before 随后通过另一线程从 ConcurrentMap 中访问或移除该元素的操作。
我们不关心ConcurrentMap中新增的接口,重点理解一下内存一致性效果中的“happens-before”是怎么回事。因为要想从根本上讲明白,这个是无法避开的。这又不得不从Java存储模型来谈起了。
1. 理解JAVA存储模型(JMM)的Happens-Before规则。
在解释该规则之前,我们先看一段多线程访问数据的代码例子:
public class Test1 {
private int a=1, b=2;
public void foo(){ // 线程1
a=3;
b=4;
}
public int getA(){ // 线程2
return a;
}
public int getB(){ // 线程2
return b;
}
}
上面的代码,当线程1执行foo方法的时候,线程2访问getA和getB会得到什么样的结果?
答案:
A:a=1, b=2 // 都未改变 B:a=3, b=4 // 都改变了 C:a=3, b=2 // a改变了,b未改变 D:a=1, b=4 // b改变了,a未改变
上面的A,B,C都好理解,但是D可能会出乎一些人的预料。
一些不了解JMM的同学可能会问怎么可能 b=4语句会先于 a=3 执行?
这是一个多线程之间内存可见性(Visibility)顺序不一致的问题。有两种可能会造成上面的D选项。
1) Java编译器的重排序(Reording)操作有可能导致执行顺序和代码顺序不一致。
关于Reording:
Java语言规范规定了JVM要维护内部线程类似顺序化语义(within-thread as-is-serial semantics):只要程序的最终结果等同于它在严格的顺序化环境中执行的结果,那么上述所有的行为都是允许的。
上面的话是《Java并发编程实践》一书中引自Java语言规范的,感觉翻译的不太好。简单的说:假设代码有两条语句,代码顺序是语句1先于语句2执行;那么只要语句2不依赖于语句1的结果,打乱它们的顺序对最终的结果没有影响的话,那么真正交给CPU去执行时,他们的顺序可以是没有限制的。可以允许语句2先于语句1被CPU执行,和代码中的顺序不一致。
重排序(Reordering)是JVM针对现代CPU的一种优化,Reordering后的指令会在性能上有很大提升。(不知道这种优化对于多核CPU是否更加明显,也或许和单核多核没有关系。)
因为我们例子中的两条赋值语句,并没有依赖关系,无论谁先谁后结果都是一样的,所以就可能有Reordering的情况,这种情况下,对于其他线程来说就可能造成了可见性顺序不一致的问题。
2) 从线程工作内存写回主存时顺序无法保证。
下图描述了JVM中主存和线程工作内存之间的交互:
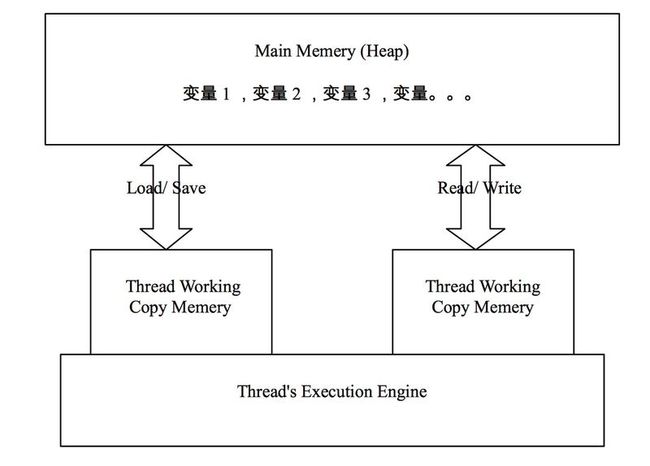
JLS中对线程和主存互操作定义了6个行为,分别为load,save,read,write,assign和use,这些操作行为具有原子性,且相互依赖,有明确的调用先后顺序。这个细节也比较繁琐,我们暂不深入追究。先简单认为线程在修改一个变量时,先拷贝入线程工作内存中,在线程工作内存修改后再写回主存(Main Memery)中。
假设例子中Reording后顺序仍与代码中的顺序一致,那么接下来呢?
有意思的事情就发生在线程把Working Copy Memery中的变量写回Main Memery的时刻。
线程1把变量写回Main Memery的过程对线程2的可见性顺序也是无法保证的。
上面的列子,a=3; b=4; 这两个语句在 Working Copy Memery中执行后,写回主存的过程对于线程2来说同样可能出现先b=4;后a=3;这样的相反顺序。
正因为上面的那些问题,JMM中一个重要问题就是:如何让多线程之间,对象的状态对于各线程的“可视性”是顺序一致的。
它的解决方式就是 Happens-before 规则:
JMM为所有程序内部动作定义了一个偏序关系,叫做happens-before。要想保证执行动作B的线程看到动作A的结果(无论A和B是否发生在同一个线程中),A和B之间就必须满足happens-before关系。
我们现在来看一下“Happens-before”规则都有哪些(摘自《Java并发编程实践》):
① 程序次序法则:线程中的每个动作A都happens-before于该线程中的每一个动作B,其中,在程序中,所有的动作B都能出现在A之后。
② 监视器锁法则:对一个监视器锁的解锁 happens-before于每一个后续对同一监视器锁的加锁。
③ volatile变量法则:对volatile域的写入操作happens-before于每一个后续对同一个域的读写操作。
④ 线程启动法则:在一个线程里,对Thread.start的调用会happens-before于每个启动线程的动作。
⑤ 线程终结法则:线程中的任何动作都happens-before于其他线程检测到这个线程已经终结、或者从Thread.join调用中成功返回,或Thread.isAlive返回false。
⑥ 中断法则:一个线程调用另一个线程的interrupt happens-before于被中断的线程发现中断。
⑦ 终结法则:一个对象的构造函数的结束happens-before于这个对象finalizer的开始。
⑧ 传递性:如果A happens-before于B,且B happens-before于C,则A happens-before于C
(更多关于happens-before描述见附注2)
我们重点关注的是②,③,这两条也是我们通常编程中常用的。
后续分析ConcurrenHashMap时也会看到使用到锁(ReentrantLock),Volatile,final等手段来保证happens-before规则的。
使用锁方式实现“Happens-before”是最简单,容易理解的。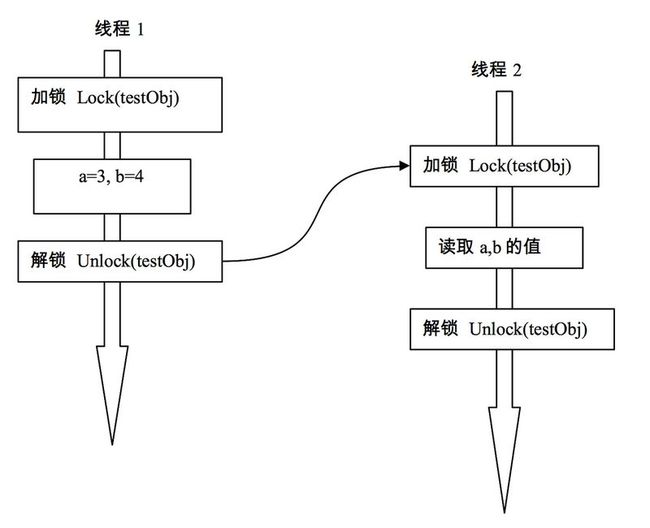
早期Java中的锁只有最基本的synchronized,它是一种互斥的实现方式。在Java5之后,增加了一些其它锁,比如ReentrantLock,它基本作用和synchronized相似,但提供了更多的操作方式,比如在获取锁时不必像synchronized那样只是傻等,可以设置定时,轮询,或者中断,这些方法使得它在获取多个锁的情况可以避免死锁操作。
而我们需要了解的是ReentrantLock的性能相对synchronized来说有很大的提高。(不过据说Java6后对synchronized进行了优化,两者已经接近了。)在ConcurrentHashMap中,每个hash区间使用的锁正是ReentrantLock。
Volatile可以看做一种轻量级的锁,但又和锁有些不同。
a) 它对于多线程,不是一种互斥(mutex)关系。
b) 用volatile修饰的变量,不能保证该变量状态的改变对于其他线程来说是一种“原子化操作”。
在Java5之前,JMM对Volatile的定义是:保证读写volatile都直接发生在main memory中,线程的working memory不进行缓存。
它只承诺了读和写过程的可见性,并没有对Reording做限制,所以旧的Volatile并不太可靠。
在Java5之后,JMM对volatile的语义进行了增强。就是我们看到的③ volatile变量法则
那对于“原子化操作”怎么理解呢?看下面例子:
private static volatile int nextSerialNum = 0;
public static int generateSerialNumber(){
return nextSerialNum++;
}
上面代码中对nextSerialNum使用了volatile来修饰,根据前面“Happens-Before”法则的第三条Volatile变量法则,看似不同线程都会得到一个新的serialNumber
问题出在了 nextSerialNum++ 这条语句上,它不是一个原子化的,实际上是read-modify-write三项操作,这就有可能使得在线程1在write之前,线程2也访问到了nextSerialNum,造成了线程1和线程2得到一样的serialNumber。
所以,在使用Volatile时,需要注意
a) 需不需要互斥;
b)对象状态的改变是不是原子化的。
最后也说一下final 关键字。
不变模式(immutable)是多线程安全里最简单的一种保障方式。因为你拿他没有办法,想改变它也没有机会。
不变模式主要通过final关键字来限定的。
在JMM中final关键字还有特殊的语义。Final域使得确保初始化安全性(initialization safety)成为可能,初始化安全性让不可变形对象不需要同步就能自由地被访问和共享。
2)经过前面的了解,下面我们用Happens-Before规则理解一个经典问题:双重检测锁(DCL)为什么在java中不适用?
public class LazySingleton {
private int someField;
private static LazySingleton instance;
private LazySingleton(){
this.someField = new Random().nextInt(200) + 1; // (1)
}
public static LazySingleton getInstance() {
if (instance == null) {// (2)
synchronized (LazySingleton.class) { // (3)
if (instance == null) { // (4)
instance = new LazySingleton(); // (5)
}
}
}
return instance; // (6)
}
public int getSomeField() {
return this.someField; // (7)
}
}
这里例子的详细解释可以看这里:http://www.javaeye.com/topic/260515?page=1
他解释的太详细了,是基于数学证明来分析的,看似更严谨一些,他的证明是因为那几条语句之间不存在Happens-before约束,所以它们不能保证可见性顺序。理解起来有些抽象,对于经验不多的程序员来说缺乏更有效的说服力。
我想简单的用对象创建期间的实际场景来分析一下:(注意,这种场景是我个人的理解,所看的资料也是非官方的,不完全保证正确。如果发现不对请指出。见附注1)
假设线程1执行完(5)时,线程2正好执行到了(2);
看看 new LazySingleton(); 这个语句的执行过程: 它不是一个原子操作,实际是由多个步骤,我们从我们关注的角度简化一下,简单的认为它主要有2步操作好了:
a) 在内存中分配空间,并将引用指向该内存空间。
b) 执行对象的初始化的逻辑(和操作),完成对象的构建。
此时因为线程1和线程2没有用同步,他们之间不存在“Happens-Before”规则的约束,所以在线程1创建LazySingleton对象的 a),b)这两个步骤对于线程2来说会有可能出现a)可见,b)不可见
造成了线程2获取到了一个未创建完整的lazySingleton对象引用,为后边埋下隐患。
之所以这里举到 DCL这个例子,是因为我们后边分析ConcurrentHashMap时,也会遇到相似的情况。
对于对象的创建,出于乐观考虑,两个线程之间没有用“Happens-Before规则来约束”另一个线程可能会得到一个未创建完整的对象,这种情况必须要检测,后续分析ConcurrentHashMap时再讨论。
附注1:
我所定义的场景,是基于对以下资料了解的,比较低层,没有细看。
原文:http://www.cs.umd.edu/~pugh/java/memoryModel/DoubleCheckedLocking.html
其中分析一个对象创建过程的部分摘抄如下:
singletons[i].reference = new Singleton();
to the following (note that the Symantec JIT using a handle-based object allocation system).
0206106A mov eax,0F97E78h 0206106F call 01F6B210 ; allocate space for ; Singleton, return result in eax 02061074 mov dword ptr [ebp],eax ; EBP is &singletons[i].reference ; store the unconstructed object here. 02061077 mov ecx,dword ptr [eax] ; dereference the handle to ; get the raw pointer 02061079 mov dword ptr [ecx],100h ; Next 4 lines are 0206107F mov dword ptr [ecx+4],200h ; Singleton's inlined constructor 02061086 mov dword ptr [ecx+8],400h 0206108D mov dword ptr [ecx+0Ch],0F84030h
As you can see, the assignment to singletons[i].reference is performed before the constructor for Singleton is called. This is completely legal under the existing Java memory model, and also legal in C and C++ (since neither of them have a memory model).
另外,从JVM创建一个对象的过程来看,分为:“装载”,“连接”,“初始化”三个步骤。
在连接步骤中包含“验证”,“准备”,“解析”这几个环节。
为一个对象分配内存的过程是在连接步骤的准备环节,它是先于“初始化”步骤的,而构造函数的执行是在“初始化”步骤中的。
附注2:
Java6 API文档中对于内存一致性(Memory Consistency Properties)的描述:
内存一致性属性
Java Language Specification 第 17 章定义了内存操作(如共享变量的读写)的 happen-before 关系。只有写入操作 happen-before 读取操作时,才保证一个线程写入的结果对另一个线程的读取是可视的。synchronized 和 volatile 构造 happen-before 关系,Thread.start() 和 Thread.join() 方法形成 happen-before 关系。尤其是:
1) 线程中的每个操作 happen-before 稍后按程序顺序传入的该线程中的每个操作。
2) 一个解除锁监视器的(synchronized 阻塞或方法退出)happen-before 相同监视器的每个后续锁(synchronized 阻塞或方法进入)。并且因为 happen-before 关系是可传递的,所以解除锁定之前的线程的所有操作 happen-before 锁定该监视器的任何线程后续的所有操作。
3) 写入 volatile 字段 happen-before 每个后续读取相同字段。volatile 字段的读取和写入与进入和退出监视器具有相似的内存一致性效果,但不 需要互斥锁。
4) 在线程上调用 start happen-before 已启动的线程中的任何线程。
5) 线程中的所有操作 happen-before 从该线程上的 join 成功返回的任何其他线程。
java.util.concurrent 中所有类的方法及其子包扩展了这些对更高级别同步的保证。尤其是:
6) 线程中将一个对象放入任何并发 collection 之前的操作 happen-before 从另一线程中的 collection 访问或移除该元素的后续操作。
7) 线程中向 Executor 提交 Runnable 之前的操作 happen-before 其执行开始。同样适用于向 ExecutorService 提交 Callables。
8) 异步计算(由 Future 表示)所采取的操作 happen-before 通过另一线程中 Future.get() 获取结果后续的操作。
9) “释放”同步储存方法(如 Lock.unlock、Semaphore.release 和 CountDownLatch.countDown)之前的操作 happen-before 另一线程中相同同步储存对象成功“获取”方法(如 Lock.lock、Semaphore.acquire、Condition.await 和 CountDownLatch.await)的后续操作。
10) 对于通过 Exchanger 成功交换对象的每个线程对,每个线程中 exchange() 之前的操作 happen-before 另一线程中对应 exchange() 后续的操作。
11) 调用 CyclicBarrier.await 之前的操作 happen-before 屏障操作所执行的操作,屏障操作所执行的操作 happen-before 从另一线程中对应 await 成功返回的后续操作。
后续补充:
附注一种所引用的文章(Double-Checked Locking is Broken)是一篇比较著名的文章,但也比较早;他所使用的JIT还是Symantec(赛门铁克)JIT,这是一个很古老的JIT,早已经退出了Java舞台,不过我了解了一下历史,在SUN的HotSpot JIT出现之前,Symantec JIT曾是市场上编译最快的JIT。
Symantec的JIT反汇编后证明的逻辑,并不一定证明其他其他JIT也是这样的,我不清楚用什么工具能将java执行过程用汇编语言表达出来。没有去证明其他的编译器。
所以我所描述的new一个对象的场景不一定是完全正确的(不同的编译器未必都和Symantec的实现方式一致),但是始终存在reording 优化,即使编译器没有做,也有可能在cpu级去做,所以new一个对象的过程对多线程访问始终存在不确定性。