怎么看懂SQL SERVER 查询计划以及如何对应做优化
Declare @Loop Int
Declare @PRID UniqueIdentifier
Declare @ PRDesc Varchar (100)
Set @Loop = 1
Set @ PRDesc = ''
WHILE @Loop <= 100000
BEGIN
Set @PRID = NewID()
Set @PRDesc = ' PerformanceIssue - ' + Convert( Varchar(10),@Loop )
Insert Into PerformanceIssue Values (@PRID, @Loop, @PRDesc)
Set @Loop = @Loop + 1
END本文中我主要对“Table Scan”、“Index Scan”、“Index Seek”、“Cluster Index Scan”以及“Clustered Index Seek”感兴趣。也许在以后,可以对别的任务进行另外介绍。
开始入手
为了解释“显示执行计划”中的“Table Scan”、“Index Scan”、“Index Seek”、“Clustered Index Scan”和“Clustered Index Seek”,先创建新表,并添加一些示例数据进去。下面是创建新表的脚本:
Create Table PerformanceIssue
(
PRID UniqueIdentifier NOT NULL,
PRCodee Int NOT NULL,
PRDesc Varchar (100) NOT NULL
)
ON [PRIMARY]
表创建后需要添加一些数据。使用下面的脚本添加100,000条记录进去。脚本执行时间可能比较长,请耐心等待其执行完毕。
Declare @Loop Int
Declare @PRID UniqueIdentifier
Declare @ PRDesc Varchar (100)
Set @Loop = 1
Set @ PRDesc = ''
WHILE @Loop <= 100000
BEGIN
Set @PRID = NewID()
Set @PRDesc = ' PerformanceIssue - ' + Convert( Varchar(10),@Loop )
Insert Into PerformanceIssue Values (@PRID, @Loop, @PRDesc)
Set @Loop = @Loop + 1
END
脚本成功执行后,数据就添加进去了。
用下面语句来看一下表的内容:
Select PRID, PRCodee, PRDesc
From PerformanceIssue
GO
由于记录较长,因此这里就不列出查询结果了。
正如我前面讲到,我想解释何时会有“Table Scan”、“Index Scan”、“Index Seek”、“Clustered Index Scan”和“Clustered Index Seek”。上述哪个会改善性能呢?
当SQL Server返回数据时,我们想知道SQL Server采取何种扫描机制来协助获取数据。首先看一下“Table Scan”。我们想了解什么时候“Table Scan”会产生。
选择“显示执行计划”或者使用热键“Alt + Q”来激活“显示执行计划”,当然也可以用快捷键“Ctrl+K”。
看一下执行下面查询后的“执行计划”结果。
Select PRID, PRCodee, PRDesc
From PerformanceIssue
GO
上面的“执行计划”中,SQL Server用到了“Table Scan”。我问自己为什么会有“Table Scan”,SQL Server是根据什么来使用该方法的。难道是因为我想获取所有100,000条记录吗?于是我换了一个角度进行思考,如果来避免查询中出现“Table Scan”呢?此时我对SQL Server的扫描机制还不是很清楚,那么该如何优化查询呢?下面的SELECT查询中仅选择两列:[PRID, PRCodee]。
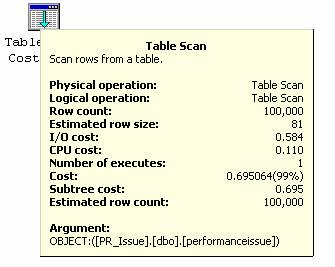
Select PRID, PRCodee
From PerformanceIssue
GO
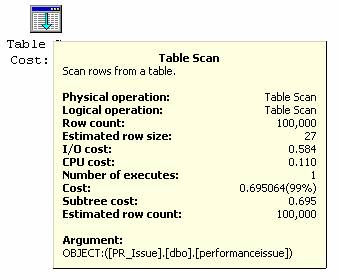
查询执行后,执行计划和第一个查询一样。于是将查询改变为只检索一个字段 [PRID]。
Select PRID
From PerformanceIssue
GO
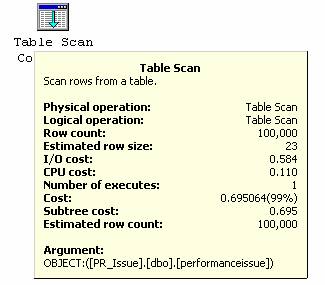
查询执行后,执行计划仍然和第一个查询的相同。对“Estimated row size”属性不需要太大关注。意思我立刻决定只获取一条记录,看看执行计划会如何。查询语句如下
Select PRID, PRCodee, PRDesc
From PerformanceIssue
Where PRID = 'D386C151-5F74-4C2A-B527-86FEF9712955'
-- PRID GUID value might be differ in your machine
GO
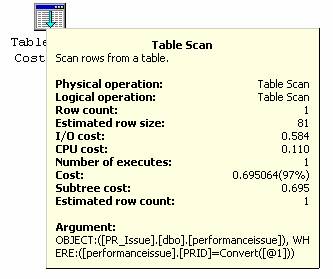
查询仍然使用了“Table Scan”方法来显示数据。
那么,我需要想其它办法来避免“Table Scan”。首先我想到应该给表加上索引。于是我在PRID字段上创建非聚集索引。添加了索引后是否就能避免“Table Scan”?下面我们开始讨论关于“Index Scan”和“Index Seek”的主题。
Index Scan 和 Index Seek
首先在PRID字段上创建非聚集索引。
CREATE UNIQUE NONCLUSTERED INDEX UNC_PRID
ON PerformanceIssue (PRID)
GO
本文假定读者已经知道非聚集索引如何工作的知识。了解非聚集索引更详细的信息,请阅读BOL相关主题,也可参看 http://www.sql-server-performance.com/gv_index_data_structures.asp。下面我们详细讲述“Index Scan”是如何工作的。
执行下面语句并查看执行计划的结果。
Select PRID, PRCodee, PRDesc
From PerformanceIssue
GO
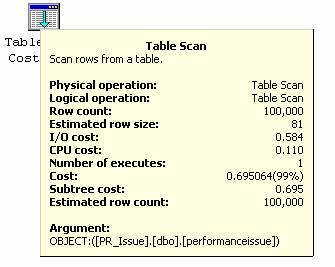
奇怪了,“Table Scan”仍然用到了。为什么SQL Server没有用到那个非聚集索引?于是继续优化查询语句,选择检索两个字段 [PRID, PRCodee] 。
Select PRID, PRCodee From PerformanceIssue
GO
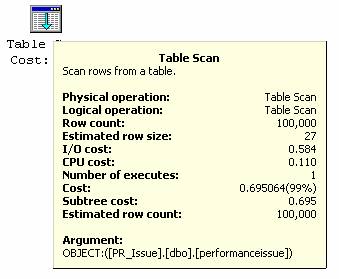
执行结果是和上一个查询结果一摸一样。于是修改查询为只检索一个字段 [PRID] 。
Select PRID
From PerformanceIssue
GO
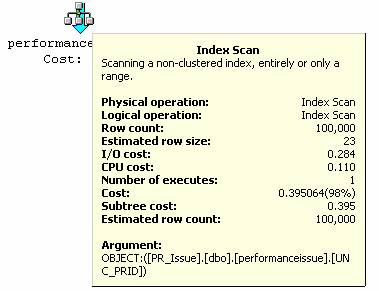
“Index Scan”在查询中被用到了,这很好。很自然,接下来的问题就是“Index Scan”什么时候会被用到。字段PRID上有一个索引,查询语句中选中的字段为PRID。执行查询的时候,SQL Server扫描索引页,因此用到了“Index Scan”方法。前面的查询中选择了有索引的和没有索引的字段,SQL Server无法使用“Index Scan”。当查询中只选择有索引的字段时,SQL Server就使用了“Index Scan”。我不清楚SQL Server底层到底是如何判断的,不过通过这些试验,我认为当查询中只选择有索引的字段时,SQL Server就使用“Index Scan”方法。
下面看“Index Seek”方法何时产生。当我看到“Seek”这个词时,第一反应就是条件查询这个主意。
我尝试三种不同的带WHERE语法的查询语句,以找出那种会用“Index Seek”。第一种语句如下:
Select PRID, PRCodee, PRDesc
From PerformanceIssue
Where PRCodee = 8
GO
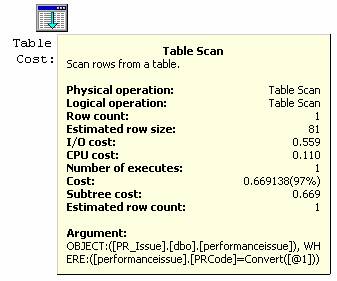
Select PRID, PRCodee, PRDesc
From PerformanceIssue
Where PRDesc = ' PerformanceIssue - 8'
GO
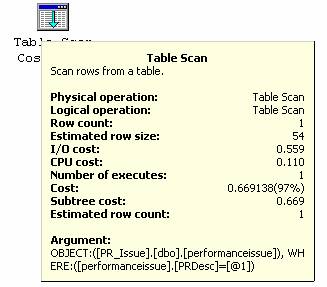
Select PRID, PRCodee, PRDesc
From PerformanceIssue
Where PRID = 'D386C151-5F74-4C2A-B527-86FEF9712955'
-- PRID GUID value might be differ in your machine
GO
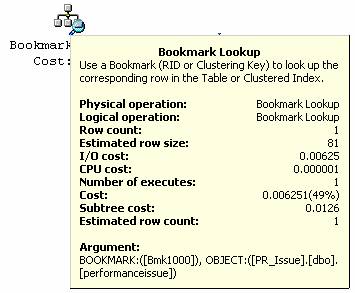
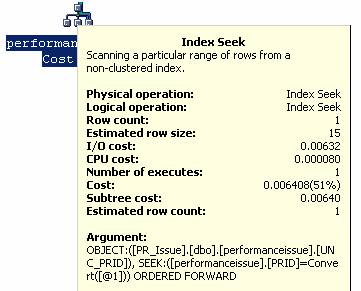
查询用到了“Index Seek”和“Bookmark Lookup”方法。用到“Index Seek”是因为WHERE后面使用带索引的字段PRID来进行过滤。“Bookmark Lookup”方法被用到是因为查询中选择了没有索引的字段。如果去掉这两个没有索引的字段,那么“Bookmark Lookup”方法就可以去掉。当然如果只返回PRID字段,那么该查询就没什么意义了,因为WHERE语句后面已经给出PRID具体取值了。
我认为“Index Seek”在性能改善上比“Index Scan”和“Table Scan”要好,这主要表现在下面几个方面:
“Index Seek”不需要对表和索引页进行扫描;而“Table Scan”和“Index Scan”需要。
“Index Seek”利用“WHERE”来过滤获取的数据,这样比用“Index Scan”和“Table Scan”快很多。
当我完成这些测试后,我同事问我一个很有意思的问题:SQL Server什么时候使用“Clustered Index Scan”和“Clustered Index Seek”?下面对“Clustered Index Scan”和“Clustered Index Seek”进行实验。
我决定在PRCodee上建一个聚集索引来测试“Clustered Index Scan”和“Clustered Index Seek”。
Clustered Index Scan & Clustered Index Seek
下面的脚本删除PRID字段上的索引,并在PRCodee字段上创建聚集索引。
Drop Index PerformanceIssue.UNC_PRID
GO
CREATE UNIQUE CLUSTERED INDEX UC_PRCodee
ON PerformanceIssue( PRCodee)
GO
-------------
Clustered index has been created successfully.
Index has been created.
关于聚集索引的基础知识请查阅联机帮助的相关主题或者 http://www.sql-server-performance.com/gv_index_data_structures.asp。下面我们将重点放在“Clustered Index Scan”和“Clustered Index Seek”如何被使用上。
执行下面查询语句:
Select PRID, PRCodee, PRDesc
From PerformanceIssue
GO

下面用三种不同的WHERE方式来试验何时SQL Server会用到“Clustered Index Seek”。第一种形式如下:
Select PRID, PRCodee, PRDesc
From PerformanceIssue
Where PRDesc = ' PerformanceIssue - 8'
GO

第二种形式如下:
Select PRID, PRCodee, PRDesc
From PerformanceIssue
Where PRID = 'D386C151-5F74-4C2A-B527-86FEF9712955'
-- PRID GUID value might be differ in your machine
GO
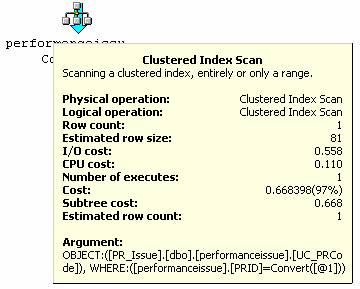
Select PRID, PRCodee, PRDesc
From PerformanceIssue
Where PRCodee = 8
GO

当在WHERE后用到PRCodee字段的时候,“Clustered Index Seek”被用到。执行计划对聚集索引表检索的时候,因为在选取的字段中,包括没有索引的字段,所以不用用到“Bookmark Lookup”方法。
我个人认为,从改善性能角度考虑,“Clustered Index Seek”比“Clustered Index Scan”和“Index Seek”要好。
“Clustered Index Seek”不需要扫描整个聚集索引页。
和“Index Scan”相比,对于检索选择的字段包含那些没有索引的字段时,“Clustered Index Seek”不会有“Bookmark Lookup”方法出现。
通过这些试验,我对执行计划的应用积累了实际经验。我知道哪种扫描机制可以提高性能。