Jedis之ShardedJedis一致性哈希分析
Jedis之ShardedJedis一致性哈希分析
ShardedJedis通过一致性哈希实现的的分布式缓存。主要思路:
redis服务器节点划分:将每台服务器节点采用hash算法划分为160个虚拟节点(可以配置划分权重)
将划分虚拟节点采用TreeMap存储
对每个redis服务器的物理连接采用LinkedHashMap存储
对Key or KeyTag 采用同样的hash算法,然后从TreeMap获取大于等于键hash值得节点,取最邻近节点存储;当key的hash值大于虚拟节点hash值得最大值时,存入第一个虚拟节点
sharded采用的hash算法:MD5 和 MurmurHash两种;默认采用64位的MurmurHash算法;
源码:
public class Sharded<R, S extends ShardInfo<R>> {
public static final int DEFAULT_WEIGHT = 1;
private TreeMap<Long, S> nodes;
private final Hashing algo;
private final Map<ShardInfo<R>, R> resources = new LinkedHashMap<ShardInfo<R>, R>();
........................
........................
}
这个类维护了一致性哈希后的物理机器和虚拟节点的映射关系,看一张图你会秒懂,
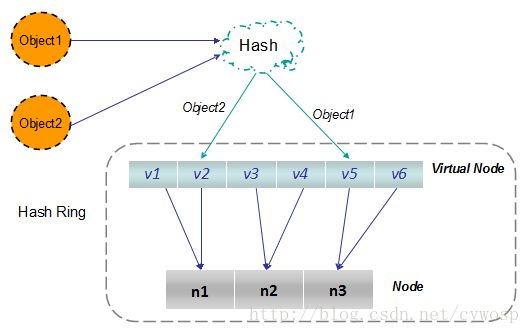
TreeMap<Long, S> nodes,存储的是虚拟节点和key的映射关系。有了虚拟节点,还要找到真正的存储位置。
Map<ShardInfo<R>, R> resources维护了虚拟节点和真正的存储位置的映射关系。
也是说,hash(key) -> virtual node -> real node;
jedis划分虚拟节点的逻辑代码,在Sharded类中,方法是initialize。这是在实例化对象池ShardedJedisPool过程中执行的划分虚拟节点。
private void initialize(List<S> shards) {
nodes = new TreeMap<Long, S>();
for (int i = 0; i != shards.size(); ++i) {
final S shardInfo = shards.get(i);
if (shardInfo.getName() == null) {
for (int n = 0; n < 160 * shardInfo.getWeight(); n++) {
nodes.put(this.algo.hash("SHARD-" + i + "-NODE-" + n), shardInfo);
}
} else {
for (int n = 0; n < 160 * shardInfo.getWeight(); n++) {
nodes.put(this.algo.hash(shardInfo.getName() + "*" + shardInfo.getWeight() + n), shardInfo);
}
}
resources.put(shardInfo, shardInfo.createResource());
}
}
以上代码就是划分虚拟节点的逻辑。
那么ShardedJedis客户端是如何执行set key value呢?
通过这里可以看出还是通过Jedis客户端执行的set key value。
public String set(String key, String value) {
Jedis j = getShard(key);
return j.set(key, value);
}
看一下代码中大体的逻辑,首先通过key得到ShardInfo,然后通过ShardInfo得到泛型Jedis客户端。
Sharded.java
public R getShard(byte[] key) {
return resources.get(getShardInfo(key));
}
public S getShardInfo(byte[] key) {
SortedMap<Long, S> tail = nodes.tailMap(algo.hash(key));
if (tail.isEmpty()) {
return nodes.get(nodes.firstKey());
}
return tail.get(tail.firstKey());
}
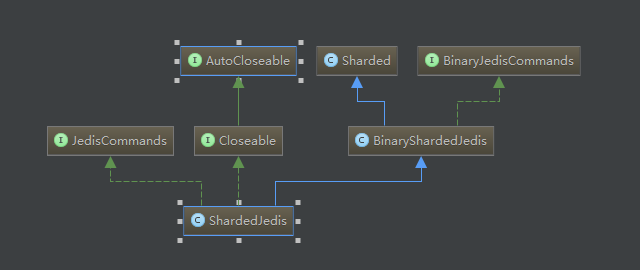
来看一下ShardedJedis的继承关系吧,
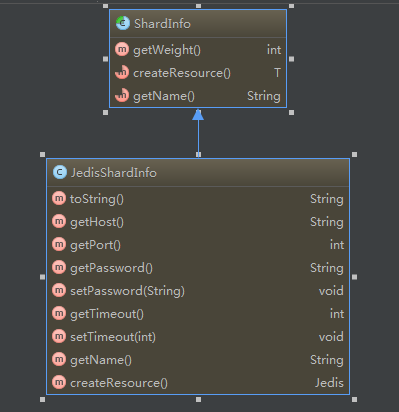
还有ShardInfo和JedisShardInfo继承关系,
参考:http://yychao.iteye.com/blog/1751583
=================END=================